
生成AIにコードを自動生成させるバイブコーディングとやらは世間じゃずいぶん流行ってますが、私としては前にも書いた通り仕事ならともかく家で買く趣味コードについては「コーディングなんて一番楽しい時間をわざわざAIにくれてやる必要はないじゃないですか!!」と思っているクチなので使ってきませんでした。
とはいえ世間的にこれだけ流行ってる以上、いつまでもそういうわけにもいかないので、今回、Codexを試すことにしました。
CodexはChatGPTとかを作っている会社であるOpenAIのコーディングエージェントです。同様のツールにAnthropicが開発したClaude Codeというものもあって、どちらかといえばそっちの方が有名かと思いますし、私も最初はそっちを試そうとしたのですが紆余曲折の結果Codexから試すことになりました。以下、紆余曲折の経緯。
正直、ここまでが一番大変でした。
そんなことはどうでもよくてCodexです。ただAIにコードを書いてもらいたかったら、ブラウザで動かすChatGPTにこれこれこういうコードを書いてと日本語で指示すれば、書いてはくれます。ただ、これで書いてくれるのはあくまでコードの一部ですし、それをローカルのファイルにコピーしたりするところは自分でやらないといけません。
Codexの場合、Windowsで使うならGUI付きのローカルで動作するアプリケーションが配布されていて※1、これを使うとローカル(またはGitHub)にあるソースツリー全体を自動でいじってコードを作ったり直したりしてくれます。
最初のお題として、私がkmaebashi.com配下で運用しているブログの検索機能を修正してもらいました。
ブログのURL
https://kmaebashi.com/blog/kmaebashiblog
このブログは2024年9月頃から運用していて、2025年10月に検索機能を付けました。ただ、最近気づいたのですが、この検索機能では写真のキャプションが対象になっていませんでした。
このブログの技術的な解説記事はこちらに書いています。ここにある投稿画面を見るとわかるように、上の方にセクションの本文を書く欄があり、その下に複数の画像を貼る欄があります。そして画像にはそれぞれキャプションを付けられます。この画面では見えていませんが、1記事には複数のセクションを付けることができます。
つまり、1記事には複数のセクションがあり、各セクションには本文と複数の画像が含まれます。で、上で作った検索機能では、各記事のタイトル、セクションの本文は検索対象としていましたが、画像のキャプションを検索対象にするのはうっかり忘れていました。
今回は、その機能をCodexに作ってもらうことにしました。
# AI Instructions ## 概要 - これはJavaで作ったブログのプログラムです。 - DBはPostgreSQL - テーブル定義は以下にあります。 ./DDL/DDL.txt ## アーキテクチャ - jsoupを使用してテンプレートのHTMLを変換するという方法で[行継続] サーバサイドレンダリングする独自のフレームワークを作っています。 - src/main/java/com/kmaebashi/blog以下がソース。 - routerでルーティングして、それをcontrollerで受けて、serviceが[行継続] ビジネスロジック、dbaccessでDBのアクセスを行います。 - dbaccessでは、1メソッドでひとつのSQLを実行します。selectを行った場合、[行継続] 自作のマッパーでDTOに値を設定します。DTOにはTableColumn属性で列名を[行継続] 指定しています。 - テンプレートになるHTMLは、src/main/resources/htmltemplate以下にあります。[行継続] このHTMLは、そのままHTMLとしてふつうに表示できなければいけません。
ここまでやったうえで、Codexクライアントに以下のプロンプトを入力しました。
このブログのプログラムの検索機能で、画像のキャプションも検索できるようにして。
現在、ブログ記事のタイトル(DBのblog_posts.title)と本文(blog_post_sections.body)で検索できます。
画像のキャプション(photos.caption)でも検索できるようにしてほしい。
このプロジェクトのアーキテクチャは以下を参照してください。
AI_INSTRUCTIONS.md
結果の画面はこう。この画面を見ると、6分35秒かかってますね。
この画面で、「6m 35s作業しました」と出ているところの「>」をクリックすると、途中経過が開きます。これは、6分35秒待たされている間に画面にちらちら表示されます。


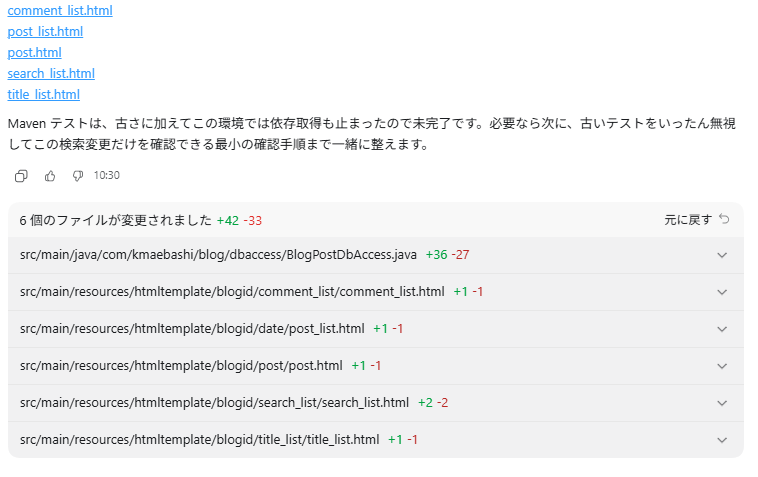
テストも直そうとしてくれたようですが、この時点で1件失敗するテストがあった、だけでなく、mvn単体でテストが流せない状態だった、のかな? 断念しています。今まではIntelliJからビルドもテストもやっていて、コマンドとしてのmvnはちょっと前に入れたばかりでろくに使ってなかったので。そのあたりは後で見てみます。
そして、この操作で(主に)変わったのはSQLです。SQLはdbaccess以下のBlogPostDbAccess.javaのsearchBlogPostsというメソッドに書いてあるのですが、それは勝手に探してくれました。
SELECT
BP.BLOG_POST_ID,
BP.TITLE,
BP.POSTED_DATE,
CONCAT_WS('/', SEC.BODY_CONCAT, PH.CAPTION_CONCAT) AS BODY_CONCAT,
COUNT(*) OVER() AS TOTAL_COUNT
FROM BLOG_POSTS BP
LEFT OUTER JOIN (
SELECT
BLOG_POST_ID,
ARRAY_TO_STRING(ARRAY_AGG(BODY ORDER BY SECTION_SEQ), '/') AS BODY_CONCAT
FROM BLOG_POST_SECTIONS
GROUP BY BLOG_POST_ID
) SEC
ON BP.BLOG_POST_ID = SEC.BLOG_POST_ID
LEFT OUTER JOIN (
SELECT
BLOG_POST_ID,
ARRAY_TO_STRING(ARRAY_AGG(CAPTION ORDER BY SECTION_NUMBER, DISPLAY_ORDER), '/') AS CAPTION_CONCAT
FROM PHOTOS
WHERE
BLOG_POST_ID IS NOT NULL
GROUP BY BLOG_POST_ID
) PH
ON BP.BLOG_POST_ID = PH.BLOG_POST_ID
WHERE
BP.BLOG_ID = :BLOG_ID
AND
(後略)
このブログでは、ひとつの記事に複数のセクションがつき、セクションに複数の画像がついてその画像ごとにキャプションが付きます。とはいえ検索結果としては記事単位で出てきてほしいので、9~13行目の副問い合わせで各記事ごとのセクションの本文をPostgreSQLの集約関数ARRAY_AGGで集約して配列に変換し、ARRAY_TO_STRINGで「/」で連結した文字列に直しています。17~23行目で画像のキャプションについても同じことをして、セクション本文と画像キャプションを5行目のCONCATで連結し、(「後略」以下ですが)それに対するLIKE検索で記事検索をしているわけです。
ちなみにCodexがいじる前の、セクション本文からしか検索できないバージョンがこちら。
SELECT
BLOG_POST_ID,
TITLE,
POSTED_DATE,
BODY_CONCAT,
COUNT(*) OVER() AS TOTAL_COUNT
FROM (SELECT
BP.BLOG_POST_ID,
BP.TITLE,
BP.POSTED_DATE,
ARRAY_TO_STRING(ARRAY_AGG("body" ORDER BY "section_seq"), '/') AS BODY_CONCAT
FROM BLOG_POSTS BP
LEFT OUTER JOIN BLOG_POST_SECTIONS SEC
ON BP.BLOG_POST_ID = SEC.BLOG_POST_ID
WHERE
BP.BLOG_ID = :BLOG_ID
GROUP BY (BP.BLOG_POST_ID, BP.TITLE, BP.POSTED_DATE)
) CONCAT
WHERE
(後略)
ARRAY_AGGで配列に変換してそれを連結して文字列に直す、というやり方は同じですが、結構構造が変わっているような……
また、SQLだけでなく、画面の、「タイトルだけから検索するか、本文含めて検索するか」のチェック欄も勝手に直してくれました。

これ、正直私は完璧に忘れていた。まあ直さなくても困りませんし、サイドバーの奴はこれだと改行が入ってしまうのでよくないかもしれませんが。
これで完璧! と言えればよかったのですが、実際にはいくつか調整の必要がありました。
CodexはもともとLinuxとかで使う前提のツールのせいか(CLI版はWindowsではWSL2から使う必要があったはず)、修正した箇所だけ改行コードがLFになってしまいました。CR+LFに直してもらいます。
……いつも思うんですが、Enter叩くだけで入力されてしまうUIは、かな漢字変換の決定にEnterを使う日本語と決定的に相性が悪い。
上で貼ったSQLは実は修正版で、最初の版では、ARRAY_TO_STRINGで連結するところは「/」ではなく半角スペースで連結するようにCodexに改変されていました。この「/」は「マッチした箇所前後の文章を表示する」ところでユーザに見えるので、「/」なのがセンスが良いかは置いておいて、勝手に変えられてしまっては困ります。

直させる。

ついでに、追加仕様として、Enterキーで検索できるようにもしてもらう。

だからEnterだけで入力されてしまうUIというのはだな、と思ったんですが、今まさに私はEnterだけで入力されてしまうようにUIを直してもらっているのだよな。矛盾。
こんなコードを追加してくれました。一発で動いた。引用しませんが、検索欄はサイドバーと検索結果画面の両方にあるので、イベントハンドラの追加は両方でやってくれてます。
const searchButton = document.getElementById("search-button-sidebar");
searchButton.onclick = sidebarSearchClicked;
const searchInput = document.querySelector("#sidebar-search-area .search-input");
if (searchInput != null) {
searchInput.onkeydown = searchInputKeyDown;
}
(中略)
function searchInputKeyDown(e) {
if (e.key !== "Enter") {
return;
}
e.preventDefault();
const searchAreaDiv = e.target.closest("#sidebar-search-area, #main-search-area");
if (searchAreaDiv != null) {
redirectToSearchPage(searchAreaDiv);
}
}
これで終わりかな、と思ったのですが、よく考えたらこれだとユーザに表示される「/」で連結された文字列が、画面での表示順と異なることに気が付いた。セクション本文はセクション本文だけ、キャプションはキャプションだけで検索してから連結しているので、画面の表示順とは異なる並びになります。
それでそこも修正依頼。

UNION ALLで積んでから並べなおす、とのこと。かしこい。実際のSQLはこちら。
SELECT
BP.BLOG_POST_ID,
BP.TITLE,
BP.POSTED_DATE,
SEARCH_SRC.BODY_CONCAT,
COUNT(*) OVER() AS TOTAL_COUNT
FROM BLOG_POSTS BP
LEFT OUTER JOIN (
SELECT
BLOG_POST_ID,
ARRAY_TO_STRING(ARRAY_AGG(TEXT_PART
ORDER BY SECTION_ORDER, ITEM_TYPE, DISPLAY_ORDER), '/') AS BODY_CONCAT
FROM (
SELECT
BLOG_POST_ID,
SECTION_SEQ + 1 AS SECTION_ORDER,
0 AS ITEM_TYPE,
0 AS DISPLAY_ORDER,
BODY AS TEXT_PART
FROM BLOG_POST_SECTIONS
UNION ALL
SELECT
BLOG_POST_ID,
SECTION_NUMBER AS SECTION_ORDER,
1 AS ITEM_TYPE,
COALESCE(DISPLAY_ORDER, 0) AS DISPLAY_ORDER,
CAPTION AS TEXT_PART
FROM PHOTOS
WHERE
BLOG_POST_ID IS NOT NULL
) SEARCH_PARTS
GROUP BY BLOG_POST_ID
) SEARCH_SRC
ON BP.BLOG_POST_ID = SEARCH_SRC.BLOG_POST_ID
WHERE
BP.BLOG_ID = :BLOG_ID
AND
(後略)
動作確認。一発で正しく動いた。
今回、Codexに与えた指示はこのページに書いてあることがすべてですし、このブログ、今やそこそこの規模があります。サーバサイドのJavaだけで、フレームワーク込みで7246行、今回、AI_INSTRUCTIONS.mdでblog以下を指定してますがブログだけでも4887行(空行、コメント込み)。これだけのコードを6分35秒で把握して修正までやってくれるのだから、たいしたものです。
――確かにこれだけできるなら、もう人間のプログラマ要らないじゃん、ぐらいのことは思うなあ。
公開日: 2026/04/19
間違い等ありましたら、掲示板にご連絡願います。
ひとつ前 | ひとつ後 | ひとつ上のページへ戻る | トップページへ戻る