タイトルの通りですが、ブログを作りました。以下のURLでちょっと前から試験運用しています。
K.Maebashi's blog
https://kmaebashi.com/blog/kmaebashiblog
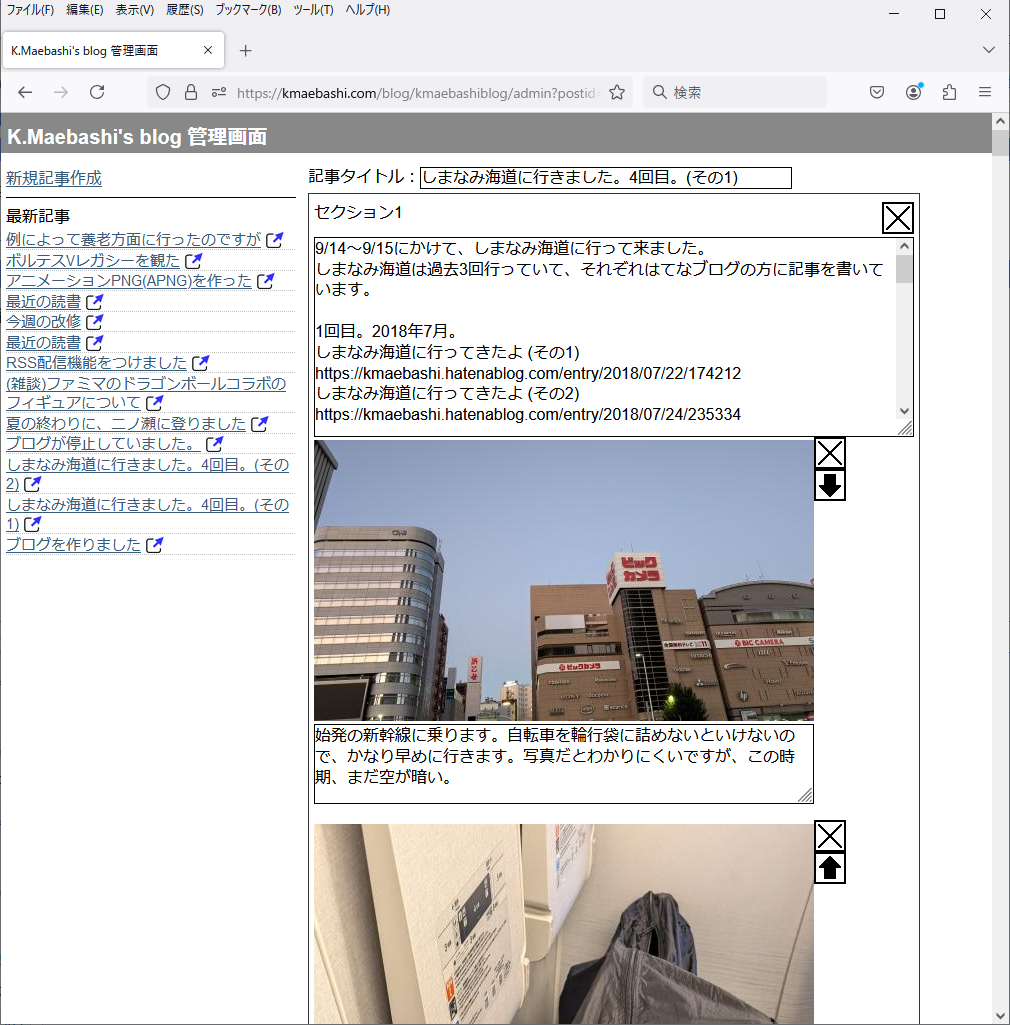
表側の画面はこのリンクから見ていただくとして、管理者(ブログ記事を書く人)向けの画面はこんな感じです(クリックで拡大します)。
見るとわかるように、画像は貼れますが、文章を書くところはただのテキストエリアになっていて、文字に色を付けたり太字にしたりするリッチテキストエディタの機能はありません。リッチテキストエディタは個人が余暇で作るにはちょっと荷が重いですし、フリーで使えるライブラリもいろいろあるようですが私はあまり外部のライブラリに頼りたくないので。それに、ブログとかで使うリッチテキストエディタって、いろいろいじっているうちに何がなんだかわからなくなって結局HTML編集モードでHTMLいじる、ということが多いように思います※1。まあSNSなどでも文字の装飾はできないわけで、それで困っていない人が多いなら、別に不要なのではと思います。
上の画像を見ると、「セクション1」と出ています。つまり、このブログでは、ひとつのブログ記事はひとつまたは複数の「セクション」から構成されます。そしてひとつのセクションには、テキストエリアで記述する文章部分があり、かつその下に複数の写真が貼れます。写真にはキャプションを付けることができます。
まあこれぐらいのことができれば、どっかに遊びに行ったりした時の日記ぐらいは書けそうです。他のことを書きたくなった時に書けるかどうかは、今後書きながら考えます。
プログラムのソースなどは貼りにくいので、プログラミング系の技術記事には向かないですが、それはこうやってWebページの方に書いてリンクだけ貼ればよいかな、と思っています。
ソースはGitHubに(動かすには、いろいろ足りてないですが)
https://github.com/kmaebashi/blog
このブログはJavaとサーブレットと自作なんちゃってフレームワークで作りました。DBはPostgreSQLを使用しており、DOM操作のためにjsoup、パスワードのハッシュ化のためにjBCryptに依存しています。
サーバサイドでレンダリングします。ブラウザからGETが飛んできた時の流れは下図の通り。
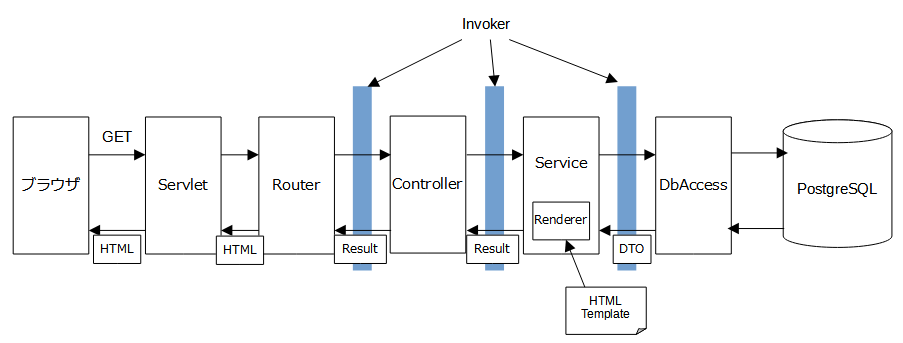
ブラウザからのリクエストを最初に受けるのはサーブレットですが、このなんちゃってフレームワークでは、サーブレットは自分で書きます。ソースはこんな感じ。
画像とかJavaScriptとかCSSとかの静的なファイル以外のリクエストは、すべてこのサーブレットが受けて、次のルータに渡します。画面やAPIがどんなに増えてもサーブレットを修正する必要はないので、1回ぐらいサーブレットを書くのは自分でやってもよいでしょう。
画像とかJavaScriptとかCSSとか以外のリクエストをサーブレットで受けるためには、画像とかJavaScriptとかCSSとかとそれ以外のリクエストの区別がつかなければいけません。このあたり、web.xmlで「拡張子.pngと.jpgと.cssと.js以外はこのサーブレットに渡す」という設定ができればよいのですが、web.xmlのurl-patternは、ワイルドカードは使えるくせに「これを除外する」という書き方はできません。この対応については以前はてなブログの方に書きました。
サーブレットのweb.xmlで静的ファイルを除外する方法 今回もこの方法を使っています。Routerは、リクエストを適切なControllerに振り分ける処理(ルーティング)を行います。
このなんちゃってフレームワークでは、Routerは、フレームワークが提供するRouterクラスを継承し、ルーティングの処理自体は自分で書きます。
この程度のブログでも、それなりの種類のURLをルーティングしなければいけないわけで(付録のURL一覧参照)、これを設定ファイルに書いたりControllerにアノテーションを付けて振り分ける、というようなことをしてもよいのでしょうが、URLの日付部分の解釈とかログイン状態の有無とかを考えるといろいろ面倒そうで、それぐらいならコードでガリガリ書いても変わらないかな、と思っています。
このブログでは、SelectRoute.javaでルートの決定を行い、それを元にBlogRouter.javaでControllerを呼び分けています。
Routerでルートが決まったらControllerを呼び、ControllerはServiceを呼び、ServiceはDbAccessを呼び、というのがこのなんちゃってフレームワークにおける呼び出し階層ですが、この階層をまたぐところ、Controllerの呼び出し、Serviceの呼び出し、DbAccessの呼び出しのところでは、せめてログぐらいは出力しておきたいところです。
そういうことをしたければ、Javaの標準機能の範囲なら、まずControllerやServiceやDbAccessのinterfaceを書いてjava.lang.reflect.Proxyを使って実装クラスのメソッドを呼び出す、という方法があります。ただ、この方法はまずinterfaceを書くのが面倒ですし、それだけならまだしもIDEでメソッドの実装に直接飛べず、たいへん不便な思いをかつてしたことがあって避けました(とかなんとか言ってるうちにIDE側が進歩して実装に直接飛べるようになってたりしましたが)。
以前私はきしださんの記事を参考にJavassistを使ってメソッドを呼び出す方法を試したこともありますし、Spring boogあたりだとByte Buddyとやらを使っているらしいのですが、バイトコードの黒魔術に手を出すのはちょっと、ということで、今回は処理本体はラムダ式として記述し、それをなんちゃってフレーム枠が提供するinvoker()メソッドを経由して呼び出すことで、呼び出しにフレームワークを介入させるようにしました。これでログは出せますし(現状、引数が出せてませんが……)、Serviceの階層ではトランザクションの機能を提供したりもしています。
たとえば以下はログイン画面のControllerであるLoginControllerの画面表示メソッドshowPage()から、LoginServiceのshowPage()を呼び出すところです。
public static RoutingResult showPage(ControllerInvoker invoker, String path) {
return invoker.invoke((context) -> {
RoutingResult result
= LoginService.showPage(context.getServiceInvoker());
return result;
});
}
Controllerには引数でControllerInvokerが渡されており、そのメソッドinvoke()に、Controllerの処理をラムダ式で渡しています。invoke()が処理本体を呼び出すときに引数としてcontextを渡しており、Service用のinvokerはこのcontextから取得するので、invoke()を経由せずにServiceを呼び出すことはできないようになっています(ServiceにはService用のcontextが、DbAccessにはDbAccess用のcontextがあり、それがないと処理に困る)。
処理本体のインデントがひとつ深くなりますが、それはまあ問題にはならないかと思っています。
テスト時のスタブでは処理本体を動かさないとか、そういうこともできそうですが、そのあたりはまだ試していません。
Controllerは、1回のHTTPリクエストに対して1回呼び出され、Serviceに処理を渡す前の前捌きを行います。
前述のように、invoke()で処理を呼び出すとcontextが手に入りますが、このcontext(型はRequestContext)は以下のようなインタフェースになっています。
public interface RequestContext {
ServiceInvoker getServiceInvoker();
HttpServletRequest getServletRequest();
HttpServletResponse getServletResponse();
Logger getLogger();
}
このようにController用のcontextからHttpServletRequestやHttpServletResponseが入手できますが、それはつまりHttpServletRequestやHttpServletResponseを使うような処理はControllerの階層で済ませておけ、ということを意図しています※2。
ServiceはWebアプリケーションとしてのロジックを書く階層です。
ブログのようなアプリケーションでは、ロジックといえば「DBから値をかき集めてHTMLを生成すること」だと思うので、そのような役割を担うようになっています。Serviceに渡されるcontextであるServiceContextの定義は以下の通り。
public interface ServiceContext {
DbAccessInvoker getDbAccessInvoker();
Path getHtmlTemplateDirectory();
Logger getLogger();
}
getHtmlTemplateDirectory()というメソッドがあり、これでHTMLテンプレートのディレクトリを取得します。
HTMLをテンプレートから生成する、というのはサーバサイドレンダリングのWebアプリケーションでは大昔から定番ですが、このなんちゃってフレームワークでは、HTMLだけである程度見るに堪えるレベルのHTMLを、「そのまま」使います。 たとえばこのブログのHTMLテンプレートは以下に置いてありますが、これとまったく同じHTMLが(ダミー画像を含めて)このブログを動かすサーバにも配置されており、Serviceの中でjsoupを使ってDOMを変更して、実際にブラウザの画面に表示するHTMLを作ります。
このような形にしているのは、「デザイナとの協業」のためです。
Webアプリケーションを作るとき、ある程度見栄えのよさが要求される場合は、プログラムの開発者がHTMLやCSSをゴリゴリ書くのではなく、HTMLやCSSまでは専門のデザイナが作成することがあります。まあ私を含め、プログラマはデザインやCSSの素養がないことが多いでしょうし。
そういう場合、たいてい以下のようなことになります。
こういうことが起きるのは、上記なら3の段階で、HTMLをHTMLならざるものに書き換えてしまっているためです。
もちろんこれを問題だと考えている人はいて、Spring bootで使っているテンプレートエンジンであるThymeleafでは、以下のことをうたっています。
Thymeleafの主な目的は、テンプレートの作成に対して優雅で保守性の高い方法を提供することです。それを実現するために、Thymeleafはナチュラルテンプレートというコンセプトを採用しており、デザインプロトタイプとして使用されるテンプレートファイルに影響を与えることなくロジックを注入することができます。これによって、デザインに対するコミュニケーションが改善され、デザインチームと開発チームの隙間が埋められます。
具体的にどう書くのか、と見てみると、こんな感じ。
<input type="text" name="userName" value="James Carrot" th:value="${user.name}" />ブラウザーで正しく表示できるだけでなく、(任意ですが)value属性を指定することもできます(この場合の“James Carrot”の部分です)。プロトタイプを静的にブラウザーで開いた場合にはこの値が表示され、テンプレートとして処理した場合には${user.name}の評価結果値で置き換えられます。
このおかげで、デザイナーとデベロッパーが全く同じファイルを触ることができ、静的なプロトタイプをテンプレートに変換する労力を削減することができます。こういったことを実現する機能のことをナチュラルテンプレーティングと呼びます。
「th:」で始まる属性はブラウザは無視するので、HTMLとして表示できる、デザイナもそれを無視すれば、デザイナとプログラマが同じHTMLを触ることができる――というのですが、実際問題として「th:」で始まる属性はデザイナにとっては許容できないレベルで邪魔でしょうし、プログラマにとっては表示のためだけのvalue属性は許容できないレベルで邪魔でしょう。「th:」で始まる属性の中にはそれなりにややこしい式が入ることがありますし、HTML表示のためだけのvalue属性とか要素内のテキストとかはそれなりに長いものです。HTMLなんてもともとそんなに可読性がよいものではないのに、そこにこんなに余計なものを入れたらかなり辛いのではないでしょうか。
それに、HTMLにはくり返しが含まれます。たとえばこのブログなら、左のエリアに「最新記事」の欄があり、ここには最新記事が10件表示されます※3。

こういうことをしたければ、Thymeleafでは「th:each」を使うわけですが、これを使ったHTMLをブラウザで直接開いても、中身はひとつしか表示されません。「デザインチームと開発チームの隙間が埋められます」とうたっておきながらこれではいくらなんでも詐欺だと思うので、何かやり方はあるのだと思いますが、チュートリアルの範囲では載っていないようです。
今回のなんちゃってフレームワークでは、雛型となるのは、「HTMLならざるもの」ではなく真正のHTMLです。まあデザイナが上げてきたものに、プログラマ側でid属性とかclass属性とかを足す必要はあると思いますが、その程度の修正ですみます。それならデザイナでも触れるし、いつでも最新の画面をHTMLだけで見ることができるのではないでしょうか。
くり返しがある場合、このブログでは、最初のひとつの要素をよけておいていったん親要素の中身を全部消し、よけておいた最初の要素をclone()で複製してその中身を書き換えて親要素に詰めていく、という方法を(基本的には)取っています。基本的には、というからにはそうでないところもあって、簡単な要素ならJava側でゼロから生成してしまっているところもあります。そういうところのデザインがHTML側で後から変わったら追従しないわけで、プログラマ側もそういうところに気を付けてコーディングする必要はあります(つまり、当の私がやらかしておるわけですが)。
こうしてjsoupでDOMを修正したら、HTML画面を表示するServiceは、そのDOMのインスタンスをもとにDocumentResultクラスのインスタンスを生成して返却します。これがController経由でRouterに戻されて、あとはフレームワークがブラウザにHTMLを返却してくれます。
Webアプリケーションが返すのはHTMLだけではないので、なんちゃってフレームワークには現時点で以下のXxxxxResultクラスがあります。これらはすべてRoutingResultのサブクラスです。
| クラス名 | 用途 |
|---|---|
| DocumentResult | HTML文書を返します。 |
| ImageFileResult | 画像ファイルのパスをもとに、画像を返します。 |
| JsonResult | JSONを返します。 |
| RedirectResult | リダイレクトさせます。 |
具体的なServiceの実装としては、ブログ記事ページ(日別、月別ページも含む)をレンダリングするShowPostService.javaを見るのがよいかと思います。この中のrenderXxx()というメソッドで、DOMをいじってレンダリングを行っています。
――実際のところ、HTMLをレンダリングするのなら、th:eachだのth:ifだのプログラミング言語モドキみたいな新たな文法を覚えるよりも、使い慣れたちゃんとしたプログラミング言語でゴリゴリ書く方が、通常のプログラミングテクニックが今まで通り使えるのでよっぽど楽なのでは、と私は思います。
DbAccessの層はその名の通りDBにアクセスする層です。
DbAccessに渡されるcontextであるDbAccessContextの定義は以下の通り。
public interface DbAccessContext {
Connection getConnection();
Logger getLogger();
}
見ての通り、ここでjava.sql.Connectionが取得できます。現状、なんちゃってフレームワークでは、ひとつのアプリケーションが複数のConnectionを使うことは想定していません(ありがちなケースだとは思いますが)。
Connectionを手に入れたら、あとはここで公開しているNamedParameterPreparedStatementを使ってSQLを手で書いて、検索結果をここで公開しているResultSetMapperでDTO(Data Transfer Object)に詰め込んで返します。DbAccessのメソッドは、フレームワークで矯正できるわけではありませんが、1メソッド1SQLを想定しています。
具体的な実装はBlogPostDbAccess.javaあたりを見ていただくのがよいかと。
結果を格納するDTOは、たとえばこのBlogPostDto.javaのように、TableColumnアノテーションでSQL上の列名(別名でもよい)が指定されています。これを使って検索結果をDTOにマッピングするわけです。
SQLはたいていJOINするでしょうから、DTOはDB上のテーブルとはあまり一致せず、用途に応じて作ることになります。
ある程度のWebアプリケーションともなれば、SQLを投げるときはたいていJOINぐらいするわけで、テーブルごとにSELECTかけて関連テーブルをまたひとつずつSELECTして性能が悪くなって、それを「N+1問題」とか大げさな名前を付けて真面目に論じてる人たちって、もうね、ええと、アボカドだったかバナナだったっけか。
Webアプリケーションフレームワークというといろいろ大げさな仕組みがありますが、こんななんちゃってフレームワークでも、まあそこそこ実用的なプログラムは作れるものです。
今回のブログは、しょせん個人が余暇で作ったものですので、そうたいした規模でもないですが(それでも、Javaだけで、フレームワーク込みで、6000行近くにはなったのか……)、もっと機能を増やして巨大なアプリになったところで、フレームワーク自体はこのままで行けそうな気がしています。
だからってこのなんちゃってフレームワークをみなさん使ってください、とはあまり思いませんが(使いたければご自由にどうぞ。ライセンスはNYSLでよいです)、こんな感じでみんな自分のオレオレフレームワークを作ろうぜ、ぐらいのことは思っています。
注意!!) それにしてもセキュリティまわりはあまり自作すべきではないとは思っていて、このブログではログインとかCSRF対策あたりを自作しているのは本来はあまりよろしくないのかもしれません。不具合があれば教えてください/真似するのなら自己責任で。
このフレームワークではController, Service, DbAccessすべてstaticメソッドで書きます。そして、DbAccessの階層では、SQLを直接書きます。
これでまあ、たいていのWebアプリは作れると思います。Serviceまわりで共通のロジックがいろいろ出てきそうですが、そのあたりは昔からのプログラマの伝家の宝刀、関数化で共有できるでしょう※5。
だとすれば、結局のところ、staticおじさんとSQLおじさんが正しかったんじゃないですかね。
以下がこのブログのURLの一覧です。冒頭の「/blog/」部分は、アプリケーションのディレクトリを指します(よって、warファイルの名前を変えれば別の名前になります)。
| 区分 | メソッド | URL | 遷移先 | クエリストリング |
|---|---|---|---|---|
| 表画面 | GET | /blog/{ブログID} | ブログトップ | page..ページングの際のページ番号 |
| GET | /blog/{ブログID}/{YYYYMM] | 月別表示 | page..ページングの際のページ番号 | |
| GET | /blog/{ブログID}/{YYYYMMDD} | 日別表示 | page..ページングの際のページ番号 | |
| GET | /blog/{ブログID}/post/{ブログポストID} | 記事個別表示 | ― | |
| 表画面API | GET | /blog/{ブログID}/api/getimage/{ブログポストID}/{画像ID} | 画像取得(縮小画像) | ― |
| GET | /blog/{ブログID}/api/getorgsizeimage/{ブログポストID}/{画像ID} | 画像取得(オリジナルサイズ画像) | ― | |
| GET | /blog/{ブログID}/api/getprofileimage | プロフィール画像取得 | ― | |
| GET | /blog/{ブログID}/api/getpostcounteachday | 日別の投稿数取得(カレンダー用) | month..対象月(YYYYMM形式) | |
| GET | /blog/{ブログID}/rss | RSS取得 | ― | |
| POST | /blog/{ブログID}/api/postcomment | コメント投稿 | ― | |
| 管理画面 | GET | /blog/login | ログイン画面表示 | ― |
| GET | /blog//blog_list | ブログ一覧画面 | ― | |
| GET | /blog/{ブログID}/admin | ブログ管理画面 | ― | |
| GET | /blog/{ブログID}/previewpost/{ブログポストID} | ブログ記事プレビュー画面 | ― | |
| 管理画面API | GET | /blog/api/checkpassword | パスワード確認 | ― |
| POST | /blog/api/dologin | ログイン実施 | ― | |
| GET | /blog/api/getimageadmin/{画像ID} | 管理画面用画像取得 | ― | |
| POST | /blog/{ブログID}/api/postimages | 画像投稿 | ― | |
| POST | /blog/{ブログID}/api/postarticle | ブログ記事投稿 | ― |
DDLをそのまま貼っておきます。
-- ブログを投稿するユーザを保持する。 create table users ( user_id varchar(32) primary key, password varchar(256) not null, mail_address varchar(32), created_at timestamp not null, updated_at timestamp not null ); -- ユーザごとに、プロフィールを保持する。 create table profiles ( user_id varchar(32) primary key, nickname varchar(32) not null, image_path varchar(64), about_me text not null, created_at timestamp not null, updated_at timestamp not null ); -- ブログ(記事ではなく、ブログ全体)の情報を保持する。 -- ひとりのユーザは複数のブログを持てる。 create table blogs ( blog_id varchar(32) primary key, title varchar(64) not null, description text not null, owner_user varchar(32) not null, created_at timestamp not null, updated_at timestamp not null ); -- ブログ記事の情報を保持する。 create table blog_posts ( blog_post_id integer primary key, blog_id varchar(32) not null, title varchar(64) not null, posted_date timestamp not null, status integer not null, -- 1..下書き、2..公開 created_at timestamp not null, updated_at timestamp not null ); -- ブログ記事のセクションを保持する -- 記事修正時にはすべて消して作り直す create table blog_post_sections ( blog_post_id integer, section_seq integer, body text not null, created_at timestamp not null, updated_at timestamp not null, primary key (blog_post_id, section_seq) ); -- ブログ記事の写真情報を保持する -- blog_post_idは記事を投稿するまで決まらず、写真は投稿ボタンを押す前に -- アップロードされるので、blog_post_id, display_order, captionは記事が -- 投稿されるまではNULL。 create table photos ( photo_id integer primary key, blog_id varchar(32) not null, blog_post_id integer, section_number integer, path varchar(64) not null, display_order integer, caption text, created_at timestamp not null, updated_at timestamp not null ); -- ブログ記事に付くコメント。 create table blog_post_comments ( blog_post_id integer not null, comment_id integer not null, poster_id varchar(32), poster_name varchar(32) not null, message text not null, created_at timestamp not null, updated_at timestamp not null, primary key (blog_post_id, comment_id) ); -- photo_idを生成するシーケンス。全体で連番。 create sequence photo_sequence; -- blog_post_idを生成するシーケンス。これも全体で連番。 create sequence blog_post_sequence;
公開日: 2024/10/27
不具合等ありましたら、掲示板か、ブログのコメント欄にご連絡願います。
ひとつ前 | ひとつ後 | ひとつ上のページへ戻る | トップページへ戻る