
Cでプログラミング言語の処理系を実装するのであれば、 多くの場合、yaccとlexというツールを使います。
実のところ、Cとyacc/lexで簡単なプログラミング言語を作る、というのは、 以前、「C言語ヨタ話 」で書いた「 電卓を作ってみよう」 の焼き直しになります。yaccとlexの説明もそちらに簡単に書いたので、 そちらを見てください――と言いたいところですが、 まあここでも軽く説明します。 内容的には重複、というかコピペしている部分もありますが。
プログラミング言語の処理系は、通常、以下のような手順を取ります。
この後、Cなどの機械語を吐くコンパイラや Javaのようなバイトコードを吐くコンパイラなら、 「コード生成」という処理が入りますが、 今回は、解析木を作ったらそのまま実行しますから、 コード生成の処理は入りません。
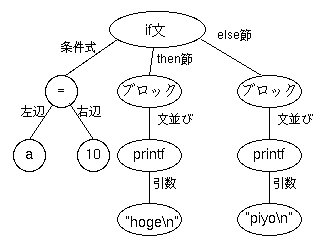
たとえば、前述の以下のようなソースについて、
if (a == 10) {
printf("hoge\n");
} else {
printf("piyo\n");
}
字句解析を行なうと、 以下のようなトークンに分割されます(この箱ひとつひとつがトークンです)。
これを構文解析して解析木を構築すると、 以下のようになります(既に出した図を再掲)。
字句解析を行なうプログラムのことを、 レキシカルアナライザ(lexical analyzer)※1 と呼びますが、 これを自動生成してくれるのがlexです。
また、前述のように、構文解析を行なうプログラムのことを パーサ(parser)と呼びます。yaccはこれを自動生成してくれるプログラムです。
yacc, lexともに、それ専用の定義ファイルを入力とし、 Cのソースを出力します。
どちらもかなり古いツールなので、 データの受け渡しにグローバル変数を使ってるあたり等、 今見るとかなりトホホなのですが、それでも、少なくともyaccの方は、 gccやらperlやらrubyやらの処理系を作成するために、 まだ現役でバリバリ使われているようです。 ただ、レキシカルアナライザは割と簡単に自作できますから、 本格的な言語では、lexはあまり使われていないような気がします。
yaccとlexは、UNIXなら標準で付属しています。 Windowsの場合、 GNUプロジェクトが提供しているbisonとflexを使うことができます (入手方法などはこちら)。
上で書いたように、ソースファイルの構文解析は、 まずレキシカルアナライザがソースをトークンに分割してから、 パーサが構文解析する、という分業により行なわれます。
よく、CやJavaについての質問で、
a+++++b;これは「a++ + ++b」以外に解釈のしようがないと思うんですが、 うちのコンパイラはエラーにしちゃうようです。なぜですか?
というものがあったりしますが、 レキシカルアナライザとパーサが前述のような分業体制を取っている以上、 これがエラーにされるのは当然です。 レキシカルアナライザはCやJavaの構文を知らないため、 「a ++ ++ + b」というトークン分割をしてしまうわけです。
yacc/lexを知らない人にその機能を説明するには、 いきなり「プログラミング言語」を例に出して説明するよりも、 もっと単純な例を使った方がよいようです。
というわけで、ここではまず簡単な「電卓」を例にして説明します。 yacc/lexのサンプルとしては、あまりにも陳腐な例ではあるのですけど。
ここで作成する電卓は、コマンドラインで起動し、 キーボードから式を入力すると、その値を表示してくれます。 演算子の優先順位を見てくれるので、
1 + 2 * 3
という入力に対しては、9ではなく7を表示します。
コマンド名はmycalcとしましょう。実行例はこんな感じです。
% mycalc ←mycalcの起動 1+2 ←式の入力 >>3.000000 ←結果の出力 1+2*3 ←加算と乗算の混在 >>7.000000 ←優先順位を見てくれました
整数しか使っていないのに出力が「3.000000」のようになっているのは、 mycalcは内部的な計算をすべてdoubleで行なっているからです。
lexはレキシカルアナライザを自動生成するツールです。 「.l」という拡張子のファイルを入力とし、 Cのソースを出力します。これのGNU版がflexです。
レキシカルアナライザは、 入力された文字列をトークンに分割するプログラムですから、 lexの定義ファイルではmycalcが扱うトークンを定義しなければなりません。
mycalcが扱うトークンには、以下のものがあります。
lexでは、正規表現※2 を使ってトークンを定義します。
mycalcにおけるlexの入力ファイル「mycalc.l」は以下の通りです。
1: %{
2: #include <stdio.h>
3: #include "y.tab.h"
4:
5: int
6: yywrap(void)
7: {
8: return 1;
9: }
10: %}
11: %%
12: "+" return ADD;
13: "-" return SUB;
14: "*" return MUL;
15: "/" return DIV;
16: "\n" return CR;
17: [1-9][0-9]* {
18: double temp;
19: sscanf(yytext, "%lf", &temp);
20: yylval.double_value = temp;
21: return DOUBLE_LITERAL;
22: }
23: [0-9]*\.[0-9]* {
24: double temp;
25: sscanf(yytext, "%lf", &temp);
26: yylval.double_value = temp;
27: return DOUBLE_LITERAL;
28: }
29: %%
11行目に「%%」という行がありますが、この行までの部分を指して 定義部と呼びます。 定義部には、 スタート状態の定義や正規表現の名前付けなど(それが何であるかは 今は知らなくてよいです)を行なうことができるのですが、 この例では、Cのコードを記述しています。
1行目から10行目までの、「%{」「%}」で囲まれている部分は、 生成されるレキシカルアナライザにそのまま出力されます。 そこで、これ以降の部分で必要なヘッダファイルの#include などをここで行ないます。 3行目では「y.tab.h」というヘッダファイルを#includeしていますが、 これは、後述するyaccが自動生成するヘッダファイルです。 この下で出てくる、ADD, SUB, MUL, DIV, CR, DOUBLE_LITERAL などはy.tab.hの中で#defineされています。
5行目から9行目までで、yywrap()という関数を定義しています。 これは、これを書かないとlexのライブラリをリンクしなければいけなくなって、 環境によってはコンパイルが面倒なので書いてあります。 今は「こういうもんだ」と思って書いておいてください。
12行目から28行目までは規則部です。 見ての通り、正規表現でトークンを表現しています。
規則部は、正規表現の後ろに何個かの空白を入れて、Cのコードを書く、 という形式になっています。 入力された文字列が正規表現にマッチした場合、 その後ろのCのコードが実行されます。 このCコードの部分のことをアクションと呼びます。
12~16行目では、四則演算の演算子、および改行について、 それぞれ決められたシンボルをreturnしています。 これらのシンボルは、トークンの種類を表現していて、前述のように y.tab.hの中で#defineされています。
ところで、一口にトークンと言っても、 その持つ意味合いとしては3通りあります。
「+」や「-」なら、トークンの種類だけを気にしていればよいでしょうが、 DOUBLE_LITERALの場合、トークンの値もパーサに渡さなければなりません。
上に挙げた、トークンの3つの要素のうち、 「トークンの文字列」は、アクションの中では、 yytextというグローバル変数(とほほ)で参照することができます。 18~21行目で、sscanf()でそれを解析しています。
17行目から始まる規則では整数の解釈を、 23行目から始まる規則では実数の解釈を行なっています。 mycalcでは整数を入れても実数で解釈するので、 同じコードをコピペしちゃっています( プログラミングでは一般にコピペはよろしくなわけですが、 まあ例ということで(^^; )
解釈した値は、yylvalというグローバル変数(またしても…)にセットします。 このyylvalというグローバル変数は、 色々なトークンの値を格納しなければなりませんから (今回の電卓ではdoubleだけですが)、共用体になっています。 その共用体の定義は、yaccの定義ファイル側で行ないます。
29行目にまた「%%」があります。これは規則部の終わりを表していて、 これより後ろは、ユーザコード部になります。 ここには、任意のCのコードを記述することができます(今回は書いてませんが)。 定義部と違い、「%{」[%}」で囲む必要はありません。
yaccは、パーサを自動生成するツールです。 「.y」という拡張子のファイルを入力とし、 Cのソースを出力します。これのGNU版がbisonです。
mycalcにおけるyaccの入力ファイル「mycalc.y」は以下の通りです。
1: %{
2: #include <stdio.h>
3: #include <stdlib.h>
4: #define YYDEBUG 1
5: %}
6: %union {
7: int int_value;
8: double double_value;
9: }
10: %token <double_value> DOUBLE_LITERAL
11: %token ADD SUB MUL DIV CR
12: %type <double_value> expression term primary_expression
13: %%
14: line_list
15: : line
16: | line_list line
17: ;
18: line
19: : expression CR
20: {
21: printf(">>%lf\n", $1);
22: }
23: expression
24: : term
25: | expression ADD term
26: {
27: $$ = $1 + $3;
28: }
29: | expression SUB term
30: {
31: $$ = $1 - $3;
32: }
33: ;
34: term
35: : primary_expression
36: | term MUL primary_expression
37: {
38: $$ = $1 * $3;
39: }
40: | term DIV primary_expression
41: {
42: $$ = $1 / $3;
43: }
44: ;
45: primary_expression
46: : DOUBLE_LITERAL
47: ;
48: %%
49: int
50: yyerror(char const *str)
51: {
52: extern char *yytext;
53: fprintf(stderr, "parser error near %s\n", yytext);
54: return 0;
55: }
56:
57: int main(void)
58: {
59: extern int yyparse(void);
60: extern FILE *yyin;
61:
62: yyin = stdin;
63: if (yyparse()) {
64: fprintf(stderr, "Error ! Error ! Error !\n");
65: exit(1);
66: }
67: }
104行目は、lexの場合と同じく、 「%{」「}%」で囲んでCのコードを記述しています。
3行目に「#define YYDEBUG 1」とありますが、こうしておくと、 グローバル変数yydebugをデバッガなどで非ゼロにしてやることで、 構文解析の状態を実行時に見ることができます。 今は気にしなくてよいでしょう。
5~7行目は、トークンと非終端子の型宣言です。 既に書いたように、トークンは、その種類の他、値も持つ必要があります。 トークンの取り得る型はいろいろありますから、共用体で宣言しています。 ここでは、説明のためint型のint_valueとdouble型のdouble_value との共用体にしていますが、 今のところint_valueは使用していません。
非終端子とは、トークンを組み合わせて作られるもののことで、 リスト中にあるline_listとかlineとかexpressionとかtermのことです。 なお、非終端子を分割していくと最後にはトークンに行き着くわけで、 トークンのことを、終端子と呼ぶこともあります。
9~10行目は、トークンの宣言です。 mycalcで使用するトークンの種類を、ここで定義しています。 ADD, SUB, MUL, DIV, CRに関しては、 単にトークンの種類だけわかればよいですが、 DOUBLE_LITERALは値を持つトークンなので、その型を、 <double_value>として指定しています。 このdouble_valueは、すぐ上の%unionのメンバ名です。
11行目では、非終端子の型宣言をしています。
lexと同様、13行目の%%より後ろが規則部です。 規則部は、構文規則と、Cで記述されたアクションから構成されているわけですが、 規則の中にアクションが混じっていると読みにくいので、 構文規則だけ抽出し、コメントを加えると以下のようになります。
1: line_list /* 「行並び」とは… */ 2: : line /* (ひとつの)行、*/ 3: | line_list line /* または、「行並び」の後ろに「行」を並べたもの。*/ 4: ; 5: line /* 「行」とは… */ 6: : expression RETURN_T /* 式の後ろに改行を入れたもの。 */ 7: expression /* 「式」とは… */ 8: : term /* 「項」、 */ 9: | expression ADD term /* または、「式」 + 「項」 */ 10: | expression SUB term /* または、「式」 - 「項」 */ 11: ; 12: term /* 「項」とは、 */ 13: : primary_expression /* 「一次式」、 */ 14: | term MUL primary_expression /* または、「項」 * 「一次式」 */ 15: | term DIV primary_expression /* または、「項」 / 「一次式」 */ 16: ; 17: primary_expression /* 「一次式」とは… */ 18: : DOUBLE_LITERAL /* 実数のリテラル */ 19: ;
これを見るとわかるように、構文規則は、以下のような形式で記述し、
A : B C | D ;
「Aとは、BとCを並べたもの、またはDである」という意味になります。
1~4行目のような書き方は、 構文規則において「1回以上の繰り返し」を表現するための定石です。 mycalcは、1行の式を入力し、改行を叩くことで計算を行ないますが、 その後また繰り返し式を入力できるので、繰り返しの構造になっているわけです。
また、上の電卓の構文規則は、構文規則自体が演算子の優先順位と結合規則を 含んでいることに注意してください。 もし、演算子の優先順位(掛け算は足し算よりも先にやる) を考慮しなくてよいのなら、上記の構文規則は以下のようになります ※3。
expression /* 「式」とは… */ : primary_expression /* 「一次式」、 */ | expression ADD expression /* または、「式」 + 「項」 */ | expression SUB expression /* または、「式」 - 「項」 */ | expression MUL expression /* または、「式」 * 「項」 */ | expression DIV expression /* または、「式」 / 「項」 */ ; primary_expression /* 「一次式」とは… */ : DOUBLE_LITERAL /* 実数のリテラル */ ;
さて、こういった構文規則を元に、yaccがどのような動きをするかですが。
ま、ざっくり言えば、yaccがやってくれることは、 テトリスのようなもんだと思ってください。
まず、yaccが生成したパーサは、内部的にスタックを保持しています。 このスタックに、 テトリスのブロックよろしくトークンが積み上がっていくことになります。
例えば、「1 + 2 * 3」という入力があったとすると、 レキシカルアナライザで分割されたトークン(最初は「1」)が、 右の方から降ってきます。

このように、トークンが降ってきて積み上がることを、 shiftと呼びます。
mycalcはすべての計算をdoubleで行なうので、 「1」というトークンは、DOUBLE_LITERALです。 トークンが落ちると同時に、上記規則のうち
primary_expression : DOUBLE_LITERAL
にひっかかり、 「primary_expression」に変換されます。

このように、何らかの規則に引っかかって変換されることを、 reduce(還元)と呼びます。
「primary_expression」は、さらに、
term : primary_expression
にひっかかって、「term」にreduceされ、

さらに、
expression /* 「式」とは... */
: term /* 「項」 */
により、「expression」にreduceされます。

次に、「+」が降ってきます。この状態では、どの規則にもマッチしませんから、 おとなしくshiftします。

次に、「2」が降ってきます。

さっきと同じ規則により、「2」(DOUBLE_LITERAL)は、 「primary_expression」を経由して「term」にreduceされます。

ここで、次の規則にマッチしたわけですが、
expression | expression ADD term
yaccは、これまたテトリスがそうであるように、 次に落ちてくるトークンが何であるかを、ひとつだけ先読みしています。 ここでは、次に落ちてくるのが「*」であることが分かっているので、
term | term MUL primary_expression
にマッチできる可能性があると考えて、さらにshiftします。

さらに、「3」が降ってきて、

「primary_expression」にreduceされると、

term | term MUL primary_expression
にマッチして、「term」にreduceされます。

さらに、「expression」「+」「term」は、
expression | expression ADD term
にマッチするので、最終的に「expression」にreduceされます。

ところで、reduceが発生するたびに、yaccは、 その規則のアクションを実行します。 たとえば乗算を行なう規則は以下のようになっています。
33: term
35: | term MUL primary_expression
36: {
37: $$ = $1 * $3;
38: }
アクションはCのコードで記述するのですが、普通のCのコードでは見かけない、 $$, $1, $3という表現が混じっています。
このうち、$1, $3は、 それぞれtermとprimary_expressionが保持している値を意味しています。 つまり、yaccがパーサのソースを吐くとき、 スタックのその位置の要素を表すコードに変換するわけです。 なお、$2はアスタリスクなので、値を持ちません。
$1と$2で掛け算を行なって、$$に代入すると、 その値がスタックに残ります。今回の例では、2 * 3という計算を行なって、 6をスタックに残すことになります。

「あれ? $1や$3に対応しているのはtermやprimary_expressionであって、 2や3のようなDOUBLE_LITERALではないじゃないか。 なのになぜ2 * 3という計算になるんだ?」
と思う人がいるかもしれません。それは、アクションを書かなかった場合、 yaccは自動的にそこに { $$ = $1 }というアクションを補うためです。 よって、DOUBLE_LITERALがprimary_expressionにreduceされたり、 primary_expressionがtermにreduceされたりした時点で、 値が引き継がれているわけです。
33: term
34: : primary_expression
{
$$ = $1; /* 補われたアクション */
}
…
44: primary_expression
45: : DOUBLE_LITERAL
{
$$ = $1; /* 補われたアクション */
}
また、$$ や $1 のデータ型は、 それぞれ対応するトークンや非終端子の型と一致します。 たとえばDOUBLE_LITERALというトークンは
9: %token <double_value> DOUBLE_LITERAL
と宣言されていますし、expressionやtermやprimary_expressionは
11: %type <double_value> expression term primary_expression
こうです。ここで型を<double_value>と指定していることで、 %unionで宣言されている共用体の double_valueというメンバが使われることになるわけです。
さて、この例は電卓なので、アクションでそのまま計算を行なっていますが、 それなりのプログラミング言語を作るのであればそういうわけにはいきません。 プログラミング言語にはループという処理がありますが、 構文解析は一度しか通らないため、 同じ個所に対してアクションが繰り返し実行されることはないからです。
そこで、アクションでは、解析木を組み立てることになります。 その処理については後の章で。
さて、実際に電卓をコンパイル/リンクして、実行形式を作成してみます。
標準的なUNIXでは、以下のコマンドを順に実行すればよいでしょう (%はプロンプトです)。 これにより「mycalc」という名前の実行形式が出力されます。
% yacc -dv mycalc.y ←yaccの実行 % lex mycalc.l ←lexの実行 % cc -o mycalc y.tab.c lex.yy.c ←Cコンパイラでコンパイル
この過程でいくつかのファイルが生成されます。 その流れを図にすると、以下のようになります。

y.tab.cがyaccが生成する構文解析器のソースであり、 lex.yy.cがレキシカルアナライザのソースです。 crowbar.yで定義したトークンや共用体をlex.yy.cに伝えるために yaccが生成するのがy.tab.hというヘッダファイルです。
また、Cのプログラムでは当然のようにmain()関数が必要なわけですが、 mycalcでは、main()を、 mycalc.yのユーザコード部(47行目以降)に記述しています。 もちろんこれは他の.cファイルに分けてもかまいません。
なお、yaccの代わりにbisonを使用すると、y.tab.c, y.tab.hではなく、 mycalc.tab.c, mycalc.tab.hといったファイル名でファイルを生成します。 --yaccオプションを使えば、 yaccと同じファイル名を生成させることも可能です。
今回のサンプルはごく簡単な電卓ですが、この程度の電卓でも、 Windowsに付属するGUIの電卓などより結構使えたりします。