まずはcrowbar ver.0.1のソースコードに
GLOBAL
をかけてみました。
ここから参照可能です。
細かい不具合修正を全バージョンに対して行うのは大変ですので、 ver.0.1系列はver.0.1.01に統合しました。 ここから参照してください。
crowbar ver.0.1は全体で3つのモジュールから構成されています。
MEMとDBGは汎用的なライブラリモジュールであり、 crowbarに特化したものではありません。 ソースはそれぞれcrowbar配布ディレクトリの下の memory, debugというディレクトリに存在します。
なお、ここで私が「モジュール」と言っているのは、 「ある特定の機能を持つプログラムの固まり」のことです。 モジュールにはたいてい複数の.cファイルが含まれます。
名前の衝突を避けるため、以下のような命名規則を使用しています。
たとえばcrowbarインタプリタの型名はCRB_Interpreterですし、 これを生成する関数名はCRB_create_interpreter()です。 また、crowbarの内部関数で外部結合を持つもの(staticで隠蔽していないもの)は、 crb_create_parameter()のように小文字のプレフィクスを付けています。 crowbarが外部に公開しない型名やマクロについてはプレフィクスを付けません。 ヘッダファイルの切り分けで隠蔽できるからです。
また、モジュールは、 外部へのインタフェースとしてパブリックヘッダファイルを公開します。 ここには、公開関数や、それを呼ぶために必要なデータ型が宣言されています。 crowbarの場合、crowbarインタプリタを使う人のために CRB.hが、crowbarの組み込み関数を作成する人のために CRB_dev.hがそれぞれ公開されています。
このあたりのことは、かつて「C言語ヨタ話」の 「モジュールと命名とヘッダファイルと」 で書きましたので、 よろしければそちらもどうぞ。
crowbarの処理系はCにより実装されています。 Cでは、領域破壊系のバグや、解放忘れによるメモリリーク、 あるいは解放後の領域の参照による再現性の薄いバグなど、 メモリ周りでは嫌らしいバグが起きがちです。
おまけに、crowbarには文字列型の変数が存在し、 文字列は+演算子で結合できるので、 何らかのガベージコレクタを実装する必要があります。 たとえば
a = "a" + "b" + "c"
を評価した時、まず「"a" + "b"」 という式が実行され「"ab"」という文字列が生成されますが、 これはすぐに「"abc"」になるため 「"ab"」のための領域は自動的に解放されなければなりません。 そのための実装については「 文字列とガベージコレクション――string_pool.c」で説明しますが、 それなりにややこしいことをしなければならないため バグが入りがちであり「本当にメモリリークが起きていないか」 を確認する手段が是非とも必要です。
そこで、以下のような機能を持つメモリ管理モジュールを作成しました。 モジュール名は「MEM」ですので、 全ての公開関数はMEM_というプレフィクスを持ちます。
仕様としては、Visual C++ をデバッグモードで使った時と同じようなものになっていると思います。
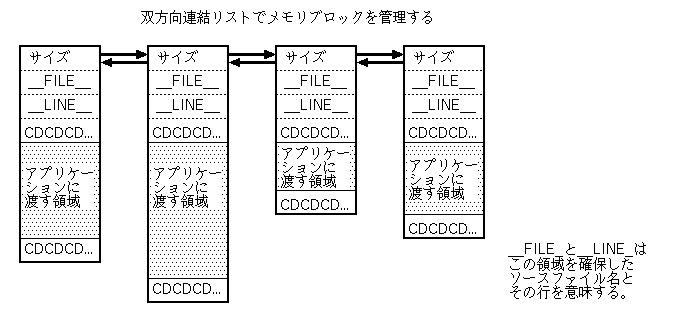
メモリ管理モジュールMEMは、図にするとこんな感じでメモリを管理しています。
単純なモジュールですが、 この程度のものでも、バグの検出にはずいぶん役に立ちました。
また、動的に確保されるメモリの中には、 「細かい領域を何回も確保するけど、解放する時には一斉に解放する」 というものも少なからずあります。 解析木のノードなどはまさにその典型例で、 確保はちまちまやりますが、解放は、まるごと一気に行ないます。
そのため、MEMは、「ストレージ」 という概念を導入したメモリ確保ルーチンも装備しています。
MEM_storage_malloc()は、 MEM_open_storage()で確保された大きな領域を、 端から順に切って返しているだけです。 そのため、実行効率は生のmalloc() よりも良いんじゃないかと思いますが(計ってませんが)、 個別に解放したり、realloc()で伸ばしたりすることはできません。
MEMは、アプリケーションが要求した領域の前後に、 管理用の領域を取ります。 intやポインタが4バイト、doubleが8バイトという(よくある)環境なら、 前に取る領域が24バイト、 後ろに取る領域が(アラインメント込みで)8バイトになります。
小さいオブジェクトを山ほど作る場合、 これはなんとも無駄に見えるかもしれません。
でも、今時のコンピュータ環境なら、 この程度の無駄は屁でもないんだから、 メモリや処理速度の節約のために小技を弄するのはやめて、 開発効率を高めよう、という考え方があります。 それが「 富豪的プログラミング」です。
crowbarの実装は結構富豪的です。 たとえば、crowbarで書かれたプログラムに、 hoge_piyo_foo_barという名前の変数が登場したとします。 最近のプログラムでは、この程度の長さの変数名・関数名はざらですよね。 当然、このプログラムでは、何度も「hoge_piyo_foo_bar」 という変数が登場することになるのでしょうが、 crowbarインタプリタはそれら全てに別の領域を割り当てています。 よって、その分メモリを食いますし、 変数名の一致をチェックするにはstrcmp()の必要があります。 また、変数や関数の検索は全てリニアサーチです。
crowbarで実用プログラムを書いたことは私もまだないわけですが、 もし遅かったら遅かった時に考えればよいわけで、 当面はプログラムの書きやすさとわかりやすさを優先させました。
crowbarを使う場合は、まずインタプリタを生成し、 それにソースファイルを渡してコンパイル(解析木の生成)を行なったり、 実行したりします。
このインタプリタの定義は以下の通り(crowbar.h)。 なお、CRB.hで公開されているCRB_Interpreter はこの構造体の不完全型宣言であり、 この構造体定義自体は外部に対して隠蔽されています。
struct CRB_Interpreter_tag {
MEM_Storage interpreter_storage;
MEM_Storage execute_storage;
Variable *variable;
FunctionDefinition *function_list;
StatementList *statement_list;
int current_line_number;
};
インタプリタでは、見ての通り、以下のものを保持しています。
解析木はいらなくなる時には一度に解放できるので、 上で説明した、 MEMモジュールが提供する「ストレージ」によるメモリ管理が使えます。
interpreter_storageは、インタプリタ生成時に生成され、 インタプリタ破棄のタイミングで解放されるストレージです。 CRB_Interpreter自身もこのストレージに確保されています。
このストレージからのメモリ確保については、 util.cにて、crb_malloc()というユーティリティ関数を提供しています。
execute_storageは、実行時に使用するストレージです。 とはいえ実行時に必要なデータ構造は、 任意の順序で解放しなければならないものが多いため、 execute_storageは現状でグローバル変数を格納するためだけに使用しています。
Variableという構造体は、ひとつの変数を格納でき、 nextというメンバも持っているので連結リストにできます。 variableはその連結リストのトップを保持しています。 つまりこれはグローバル変数のリストになっているわけです。
crowbarでは、変数は最初の代入のタイミングで生成されるので、 このリストは実行時に伸長します。
上で説明したように、variableのリストは、 execute_storage中に確保されます。
function_listは、crowbarで書かれた関数のリストです。 構文解析により作られるのは、このfunction_listと、 以下のstatement_listです。
statement_listは、「文」のリストです。 crowbarインタプリタは、構文解析後、 このリストに格納された文を先頭から順に実行していきます。
エラーメッセージを出すためには行番号が必要です。 current_line_numberは、コンパイル時の、現在の行番号を示しています。
current_line_numberは、コンパイル終了後は使用されません。 実行時に発生するエラーでも行番号は表示されますが、 その行番号は、解析木中の「文」と「式」が保持しています。
crowbar.lは、前に例に出した電卓の mycalc.lに比べ、やや長くはなっていますが、 本質的にはさほど変わりません(ソースはこちら)。 crowbar.lで新たに使っている機能といえば、スタート条件くらいです。 mycalc.lと異なり、crowbar.lでは、ほとんどの規則の前に<INITIAL> と書いてありますが、これがスタート条件です。
crowbarでは、スタート条件を、 コメントと文字列リテラルの切り出しに使っています。
crowbarのコメントは#から行末までですが、 これを切り出すために「#.*$」という正規表現を使うと、 一時的にコメント全体がyytextに格納されることになります。
flexを含む最近のlex処理系は、yytextはchar*になっていて、 長いトークンが来た時には動的に領域を拡張するようですが、 昔の処理系だと、サイズ固定のcharの配列になっていて、 しかもそのサイズはそんなに大きくなかったりしたようですし、 動的に領域を拡張してくれる処理系でも、 どうせ捨てるコメントのためにわざわざ領域を取るのは馬鹿げています。
また、crowbarの文字列リテラルは、Cと同様、 中に「\n」や「\t」を入れたり、 「\"」でダブルクオート自体を表現したりできますから、 「\".*\"」のような単純な規則で済ませるわけにもいきません。
このようなケースで使うのがスタート条件です。 アクション中で「BEGIN COMMENT」のように書くと、 lexの状態が切り替わり、 以後は「<COMMENT>」と先頭に書いてある規則が適用されるようになります。 INITIALは初期状態のスタート条件としてlexで定義されています。
crowbar.lでは、
80: <INITIAL># BEGIN COMMENT;
…
86: <COMMENT>\n {
87: increment_line_number();
88: BEGIN INITIAL;
89: }
90: <COMMENT>. ;
という規則により、 「#が来たら、COMMENT(コメント状態)に移る」 「改行が来たら、INITIAL(初期状態)に戻る」 「改行以外の文字は、コメントの間はすべて捨てる」という機能を実現しています (increment_line_number()については後述)。
文字列リテラルに関しては、開始の時点でcrb_open_string_literal() を呼び出し、途中の文字はcrb_add_string_literal()で追加、 最後はcrb_close_string_literal()で文字列終了、という手順を踏みます。 その間、文字列は、string.c中の st_string_literal_bufferというstatic変数に保持されています。 ここでstatic変数を使うことに抵抗がなくはないですが、 yacc/lexを使う限り(少なくとも古い実装では) リエントラントにはならないのであって、 今のところ、「コンパイル中は静的な変数を使ってもよい」 ということにしています。
ところで、言語処理系は、コンパイル時にエラーが発生したら、 エラーメッセージを表示しなければなりません。 そして、エラーメッセージには行番号が必要です。
そこで、crowbar.lにおいて、改行が来るたびに行番号をカウントアップしています。 具体的には以下の3個所です。
79: <INITIAL>[ \t\n] {increment_line_number();}
…
86: <COMMENT>\n {
87: increment_line_number();
88: BEGIN INITIAL;
89: }
…
98: <STRING_LITERAL_STATE>\n {
99: crb_add_string_literal('\n');
100: increment_line_number();
101: }
ここでカウントアップされた行番号は、CRB_Interpreterの current_line_numberに保持されています。
ところで、crowbar.lにおいて、forやwhileやcontinueやbreakはそれぞれ FOR, WHILE, CONTINUE, BREAKというトークン種別を返すのに、 returnだけ、RETURN_Tと「_T」が付いているのは、 他のRETURNと#defineが衝突するケースがあったためです。
crowbarにおけるyaccの定義ファイルは、crowbar.yです。 これも、構造的には、 電卓のmycalc.yと変わるところはありません。
ただし、電卓では、reduceのタイミングで実際に計算を行なっているのに対し、 crowbar.yでは解析木の構築を行なっています。
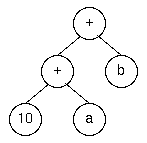
たとえば、加算式(「10 + a」など)は、 以下の規則により構築されます。
additive_expression
(中略)
| additive_expression ADD multiplicative_expression
{
$$ = crb_create_binary_expression(ADD_EXPRESSION, $1, $3);
}
ここで、additive_expressionがmycalc.yにおけるexpression、 multiplicative_expressionはtermに相当します。
アクションにて、crb_crete_binary_expressionが呼び出されていますが、 その実装はcreate.cにあります。 この関数では、 定数式の畳み込みなども行なっているので多少ややこしいのですが、 それを除いたコアな部分だけ取り出すと、 要するにやっているのはこういうことです。
Expression *
crb_create_binary_expression(ExpressionType operator,
Expression *left, Expression *right)
{
Expression *exp;
exp = crb_alloc_expression(operator);
exp->u.binary_expression.left = left;
exp->u.binary_expression.right = right;
return exp;
}
crb_alloc_expression()は、細かい実装は後で説明しますが、 Expression型の構造体の領域を確保して返します。 Expression型はcrowbar.hで定義されていて、その定義は以下の通りです。
struct Expression_tag {
ExpressionType type; ←この式の種別を表す
int line_number;
union { ←共用体により、種別に応じた値を保持する
int int_value;
double double_value;
char *string_value;
char *identifier;
AssignExpression assign_expression;
BinaryExpression binary_expression;
Expression *minus_expression;
FunctionCallExpression function_call_expression;
} u;
};
この構造体は、解析木において「式」を表現する型です。 Cで継承に似たことをしようとする場合の定石ですが、 列挙型ExpressionTypeによりその式の種別を示し、 共用体で、それぞれの式に応じた値を保持するようにしています。
ExpressionTypeの具体的な定義はこちら。
typedef enum {
INT_EXPRESSION = 1, /* 整数定数 */
DOUBLE_EXPRESSION, /* 実数定数 */
STRING_EXPRESSION, /* 文字列定数 */
IDENTIFIER_EXPRESSION,/* 変数 */
ASSIGN_EXPRESSION, /* 代入式 */
ADD_EXPRESSION, /* 加算式 */
SUB_EXPRESSION, /* 減算式 */
MUL_EXPRESSION, /* 乗算式 */
DIV_EXPRESSION, /* 除算式 */
MOD_EXPRESSION, /* 剰余式 */
EQ_EXPRESSION, /* == */
NE_EXPRESSION, /* != */
GT_EXPRESSION, /* > */
GE_EXPRESSION, /* >= */
LT_EXPRESSION, /* < */
LE_EXPRESSION, /* <= */
MINUS_EXPRESSION, /* 単項マイナス */
FUNCTION_CALL_EXPRESSION,/* 関数呼び出し式 */
NULL_EXPRESSION, /* null式 */
EXPRESSION_TYPE_COUNT_PLUS_1
} ExpressionType;
このうち、ADD_EXPRESSIONからLE_EXPRESSIONまでが、 共用体のbinary_expressionメンバを使用します。 binary_expressionの型はBinaryExpressionですが、 その定義は以下の通りです。
typedef struct {
Expression *left;
Expression *right;
} BinaryExpression;
crb_create_binary_expression()は、こうして構築した Expressionへのポインタを返しますが、 それがcrowbar.yの中で$$に代入されるため、
$$ = crb_create_binary_expression(ADD_EXPRESSION, $1, $3);
「10 + a + b」のような式からは、以下のような解析木が構築されます。
さて、crb_alloc_expression()関数ですが、 これは単純に、crb_malloc()でExpressionの領域を確保し、 typeと行番号を設定した上で返しているだけです。
crb_alloc_expression(ExpressionType type)
{
Expression *exp;
exp = crb_malloc(sizeof(Expression));
exp->type = type;
exp->line_number = crb_get_current_interpreter()->current_line_number;
return exp;
}
式に対して、そのreduceのタイミングで行番号を設定している、ということは、 複数行に渡る式(関数呼び出しで引数がたくさんある場合など)では、 「最後の行」の行番号が設定されることになります。 そして、エラーメッセージで表示されるのはその行番号ですから、 仕様としてちと問題があるとは思いますが、 今のところ面倒なのでこの形になっています。
解析木では、「式」だけでなく「文」も重要です。 考え方は同じなので、関連する構造体定義をcrowbar.hから抜粋しておきます。
struct Statement_tag {
StatementType type;
int line_number;
union {
Expression *expression_s; /* 式文 */
IfStatement if_s; /* if文 */
WhileStatement while_s; /* while文 */
ForStatement for_s; /* for文 */
ReturnStatement return_s; /* return文 */
} u;
};
共用体メンバの一例として、WhileStatementの定義は以下の通り。
typedef struct {
Expression *condition; /* 条件式 */
Block *block; /* 実行するブロック */
} WhileStatement;
「Block」は中括弧で囲まれたブロックを表現する型です。 文の並びを保持します。
typedef struct {
StatementList *statement_list;
} Block;
StatementTypeの一覧は以下の通り。
typedef enum {
EXPRESSION_STATEMENT = 1,
IF_STATEMENT,
WHILE_STATEMENT,
FOR_STATEMENT,
RETURN_STATEMENT,
BREAK_STATEMENT,
CONTINUE_STATEMENT,
STATEMENT_TYPE_COUNT_PLUS_1
} StatementType;
BREAK_STATEMENTやCONTINUE_STATEMENTは、 今のところ特に付属情報を持たないので(ラベルが付けば別)、 対応する共用体メンバはありません。
エラーメッセージは、多国語対応などを考えると、 できるだけプログラムのソース中に埋め込むのは避け、 外部ファイルなどで提供するようにしたいものです。 とはいえ、「実行形式ひとつで実行できる」というのも重要なメリットです。 そこで今回は、「error_message.c」 というソースファイルにメッセージを埋め込むことにしました。
MessageFormat crb_compile_error_message_format[] = {
{"dummy"},
{"文法エラー($(token)付近)"},
{"不正な文字($(bad_char))"},
{"関数名が重複しています($(name))"},
{"dummy"},
};
MessageFormat crb_runtime_error_message_format[] = {
{"dummy"},
{"変数が見つかりません($(name))。"},
{"関数が見つかりません($(name))。"},
{"関数が要求する引数に対し、渡している引数が多すぎます。"},
{"関数が要求する引数に対し、渡している引数が少なすぎます。"},
{"条件式は整数型でなければなりません。"},
{"マイナス演算子のオペランドは数値型でなければなりません。"},
{"文字列に対して適用できる演算子は「+」のみです。"},
{"2項演算子$(operator)のオペランドの型が不正です。"},
{"&&, ||演算子のオペランドに実数型は使えません。"},
{"dummy"},
};
この形式なら、将来多国語対応などを行なう場合に、 外部ファイルを読み込むように修正するのも容易だと思います。 crb_compile_error_messageと crb_runtime_error_messageというふたつの配列があるのは、 コンパイル時のエラーメッセージと実行時のエラーメッセージを分けたためです。
上のエラーメッセージには、「$(token)」のような文字列が埋め込まれています。 これは、エラーメッセージにおける可変部分であり、 エラーメッセージを表示する際に、引数として渡した値が表示されます。 たとえば実際に「変数が見つかりません(hoge)。」 といったエラーメッセージを表示しているのはeval.cの中ですが、 そこでは以下のように記述されています。
crb_runtime_error(expr->line_number, VARIABLE_NOT_FOUND_ERR,
STRING_MESSAGE_ARGUMENT, "name", expr->u.identifier,
MESSAGE_ARGUMENT_END);
最初の引数は行番号(create.cでExpression構造体に設定したもの)、 次がエラーの種別、 そこから先の引数は、3個一組で、メッセージ中の可変部に対応しています。 STRING_MESSAGE_ARGUMENTが型を表現(printf()における%sに相当)し、 "name"がメッセージ中の「$(name)」を指定、 expr->u.identifierがそこに表示される文字列を意味しています。 このようにcrb_runtime_errorは可変長引数を取るので、 MESSAGE_ARGUMENT_ENDにより終了を示しています。
現状では、コンパイルエラー、実行時エラー共に、 エラーメッセージを表示したら即座にexit()して実行を終了しています。 これは単なる手抜きであり、 アプリケーションの組み込み言語として使うには致命的なので、 いずれ修正の必要があるでしょう。
crowbarプログラムの実行は、CRB_interpret()により開始されますが、 その実装はこれだけです。
void
CRB_interpret(CRB_Interpreter *interpreter)
{
interpreter->execute_storage = MEM_open_storage(0);
crb_execute_statement_list(interpreter, NULL, interpreter->statement_list);
}
つまり、crb_execute_statement_list()にて、 インタプリタが保持している文のリストを順次実行しているわけです。
それでは、crb_execute_statement_list()がどうなっているのかといえば、
StatementResult
crb_execute_statement_list(CRB_Interpreter *inter, LocalEnvironment *env,
StatementList *list)
{
StatementList *pos;
StatementResult result;
result.type = NORMAL_STATEMENT_RESULT;
for (pos = list; pos; pos = pos->next) {
result = execute_statement(inter, env, pos->statement);
if (result.type != NORMAL_STATEMENT_RESULT)
goto FUNC_END;
}
FUNC_END:
return result;
}
こんな感じです。 ここから呼び出しているexecute_statement()では、 Statement型の種別に応じて、対応する処理を実行しています。
static StatementResult
execute_statement(CRB_Interpreter *inter, LocalEnvironment *env,
Statement *statement)
{
StatementResult result;
result.type = NORMAL_STATEMENT_RESULT;
switch (statement->type) {
case EXPRESSION_STATEMENT:
crb_eval_expression(inter, env, statement->u.expression_s);
break;
case IF_STATEMENT:
result = execute_if_statement(inter, env, statement);
break;
case WHILE_STATEMENT:
result = execute_while_statement(inter, env, statement);
break;
case FOR_STATEMENT:
result = execute_for_statement(inter, env, statement);
break;
case RETURN_STATEMENT:
result = execute_return_statement(inter, env, statement);
break;
case BREAK_STATEMENT:
result = execute_break_statement(inter, env, statement);
break;
case CONTINUE_STATEMENT:
result = execute_continue_statement(inter, env, statement);
break;
case STATEMENT_TYPE_COUNT_PLUS_1: /* FALLTHRU */
default:
DBG_assert(0, ("bad case...%d", statement->type));
}
return result;
}
execute_statement()の第2引数には、 LocalEnvironmentという構造体(へのポインタ)が渡されています。 これは、現在実行中の関数のローカル変数を保持する構造体で、 関数の実行中ではない場合は、NULLが渡されます。
execute_statement()内部では、見ての通り、 switch caseにより処理を振り分けています。 たとえばwhile文であれば、execute_while_statement()が呼び出されます (エラーチェックなど、本質的でない部分を除いてあります)。
static StatementResult
execute_while_statement(CRB_Interpreter *inter, LocalEnvironment *env,
Statement *statement)
{
StatementResult result;
CRB_Value cond;
result.type = NORMAL_STATEMENT_RESULT;
for (;;) { /* まずは無限ループ */
/* 条件式を評価して… */
cond = crb_eval_expression(inter, env, statement->u.while_s.condition);
/* 真でなければ終了 */
if (!cond.u.int_value)
break;
/* さもなければ、中身を実行する */
result = crb_execute_statement_list(inter, env,
statement->u.while_s.block
->statement_list);
/* このへんの話は後述 */
if (result.type == RETURN_STATEMENT_RESULT) {
break;
} else if (result.type == BREAK_STATEMENT_RESULT) {
result.type = NORMAL_STATEMENT_RESULT;
break;
}
}
return result;
}
if文やwhile文は、その内部に文を含みます。つまり文はネストするわけで、 crowbarでは、文のネストがある度に、再帰呼び出しを行ない、 ネストの奥の方の文を実行していくわけです。
実は、この方法では、break, continue, returnといった、 ある意味goto的な制御構造を実現するのが結構面倒です。
break, continue, returnなどが登場すると、再帰呼び出しの奥の方から、 強制的に復帰しなければなりません。 まあbreakやcontinueは「最も内側の」ループだけを脱出することになっていますが、 breakやcontinueは何重にもネストしたif文の中にあるかもしれませんから、 いずれにしても、 再帰呼び出しの階層を一気に遡らなければならないことに変わりはありません。
これを実現するために、longjmpを使う――という荒技もあるにはあるのですが、 この荒技は例外処理機構の実装まで取っておくことにして、 ここでは、ちまちまと戻り値で終了状態を返していくことにしました。
execute_statement()およびそこから呼び出される execute_XXXX_statement()という関数群は、 戻り値として構造体StatementResultを返します。 StatementResultの定義は以下の通り。
typedef enum {
NORMAL_STATEMENT_RESULT = 1,
RETURN_STATEMENT_RESULT,
BREAK_STATEMENT_RESULT,
CONTINUE_STATEMENT_RESULT,
STATEMENT_RESULT_TYPE_COUNT_PLUS_1
} StatementResultType;
typedef struct {
StatementResultType type;
union {
CRB_Value return_value;
} u;
} StatementResult;
通常はNORMAL_STATEMENT_RESULTが返されるわけですが、 return, break, continueを実行すると、それぞれ RETURN_STATEMENT_RESULT, BREAK_STATEMENT_RESULT, CONTINUE_STATEMENT_RESULT, をtypeに設定したStatementResultが返されます。 たとえば上のexecute_while_statement()では、 実行した文の戻り値を見て、 BREAK_STATEMENT_RESULTやRETURN_STATEMENT_RESULT の場合は処理を中断しています。
なお、continueの場合は、crb_execute_statement_list() の中で実行を中断しています。
returnの場合は、関数の実行をそこで中断するだけでなく、 戻り値を持ち帰らなければならないので、 StatementResult内のreturn_valueに戻り値を詰めています。 その型はCRB_Valueですが、それについての説明はこの続きで。
式の評価は、eval.cで行なっています。
式の評価は、解析木を再帰呼び出しで下降していき、 その帰り道で演算を行なうことで実現しています(post order traversal)。 演算結果は、CRB_Valueという構造体に詰め、上位に返します。 CRB_Valueの定義は以下の通りです。
typedef struct {
CRB_ValueType type;
union {
int int_value;
double double_value;
CRB_String *string_value;
} u;
} CRB_Value;
crowbarで扱える型は、整数、実数、文字列ですから、 これらを表現できるように共用体になっています。
式評価の中での大物は「関数呼び出し」です。 関数呼び出しは、eval_function_call_expression()で行なっています。
static CRB_Value
eval_function_call_expression(CRB_Interpreter *inter, LocalEnvironment *env,
Expression *expr)
{
CRB_Value value;
FunctionDefinition *func;
char *identifier = expr->u.function_call_expression.identifier;
func = crb_search_function(identifier);
if (func == NULL) {
crb_runtime_error(expr->line_number, FUNCTION_NOT_FOUND_ERR,
STRING_MESSAGE_ARGUMENT, "name", identifier,
MESSAGE_ARGUMENT_END);
}
switch (func->type) {
case CROWBAR_FUNCTION_DEFINITION:
value = call_crowbar_function(inter, env, expr, func);
break;
case NATIVE_FUNCTION_DEFINITION:
value = call_native_function(inter, env, expr, func->u.native_f.proc);
break;
case FUNCTION_DEFINITION_TYPE_COUNT_PLUS_1:
default:
DBG_assert(0, ("bad case..%d\n", func->type));
}
return value;
}
この関数自体は、crowbarで記述された関数と、 Cで記述された関数(ネイティブ関数)とで、処理を分岐させているだけです。
crowbarで記述された関数の場合、call_crowbar_function()が呼び出されます。
static CRB_Value
call_crowbar_function(CRB_Interpreter *inter, LocalEnvironment *env,
Expression *expr, FunctionDefinition *func)
{
CRB_Value value;
StatementResult result;
ArgumentList *arg_p;
ParameterList *param_p;
LocalEnvironment *local_env;
/* LocalEnvironmentを確保 */
local_env = alloc_local_environment();
/* 引数を評価し、ローカル変数として格納 */
for (arg_p = expr->u.function_call_expression.argument,
param_p = func->u.crowbar_f.parameter;
arg_p;
arg_p = arg_p->next, param_p = param_p->next) {
CRB_Value arg_val;
if (param_p == NULL) { /* 引数が足りない */
crb_runtime_error(expr->line_number, ARGUMENT_TOO_MANY_ERR,
MESSAGE_ARGUMENT_END);
}
arg_val = eval_expression(inter, env, arg_p->expression);
crb_add_local_variable(local_env, param_p->name, &arg_val);
}
if (param_p) { /* 引数が多過ぎ */
crb_runtime_error(expr->line_number, ARGUMENT_TOO_FEW_ERR,
MESSAGE_ARGUMENT_END);
}
/* 関数の中身を実行 */
result = crb_execute_statement_list(inter, local_env,
func->u.crowbar_f.block
->statement_list);
/* return文が実行されていたら、それを戻り値として返す */
if (result.type == RETURN_STATEMENT_RESULT) {
value = result.u.return_value;
} else {
value.type = CRB_NULL_VALUE;
}
dispose_local_environment(inter, local_env);
return value;
}
処理は見ての通りで、LocalEnvironmentを確保し、そこに引数を詰め込んで、 そのLocalEnvironmentを引数としてcrb_execute_statement_list() を呼び出しています。
LocalEnvironmentの定義は以下の通り。
typedef struct {
Variable *variable;
} LocalEnvironment;
Variableは、グローバル変数の保持にも使っている構造体です。 連結リストが構築できるように、nextがメンバに入っています。
typedef struct Variable_tag {
char *name;
CRB_Value value;
struct Variable_tag *next;
} Variable;
グローバル変数は、連結リストの根元をCRB_Interpreterが保持していましたが、 ローカル変数は、LocalEnvironmentが保持しているわけです。
CRB_Variable構造体の話が出たところで、変数について少し説明します。
既に説明したように、crowbarでは、 最初の代入が実行された時点で変数が宣言されます。 つまり、変数の宣言は、eval.cのeval_assign_expression()で発生します。
static CRB_Value
eval_assign_expression(CRB_Interpreter *inter, LocalEnvironment *env,
char *identifier, Expression *expression)
{
CRB_Value v;
CRB_Value *left;
v = eval_expression(inter, env, expression);
/* まずはlocal変数から探してみる */
left = crb_search_local_variable(env, identifier);
if (left == NULL) {
/* なければグローバル変数を探す */
left = crb_search_global_variable(inter, identifier);
}
if (left != NULL) {
どっちかにあれば、代入
*left = v;
} else { どちらにもないので、新たに作る
if (env != NULL) {
関数の外なので、グローバル変数
crb_add_local_variable(env, identifier, &v);
} else {
関数の中なので、ローカル変数
crb_add_global_variable(inter, identifier, &v);
}
}
return v;
}
関数の中で新しい変数に代入した場合、ローカル変数とみなされるので、 関数の中で、新たなグローバル変数を作り出すことはできません。
現時点では、構文規則において、 代入式の左辺は変数名であることが保証されています。 これが、配列などが使えるようになってくると、
a[b[func()]] = 10;
といったように、左辺にずいぶん複雑な式が登場することになりますから、 もうちょっと配慮が必要になります。
上でも書いたように、文字列型や+による連結をサポートする以上、 何らかの形でガベージコレクタを実現しなければなりません。 現時点のcrowbarでは、参照カウンタ方式 というもっとも簡単なガベージコレクタを実装しました。
参照カウンタ方式とは、 あるオブジェクト(この場合は文字列)を指しているポインタの数を管理し、 それがゼロになったら解放される、という方法です。
crowbarの文字列は、CRB_Stringという構造体が保持しています。
typedef struct CRB_String_tag {
int ref_count; /* 参照カウンタ */
char *string; /* 文字列本体 */
CRB_Boolean is_literal; /* リテラルかどうか */
} CRB_String;
この構造体のstringの先に、文字列が格納された領域があります。
CRB_Stringは、crb_create_crowbar_string()または crb_literal_to_string()により作成され、 参照数がゼロになったタイミングで破棄されます。 その時、文字列本体(stringメンバの指す先)は、 通常は一緒に(MEM_free()により)解放されるべきですが、 その文字列がリテラル("" で囲まれてcrowbarソース中に登場した文字列)の場合は、 解放できません。 リテラルは、MEM_malloc()ではなく、MEM_storage_malloc()により interpreter_storage内に確保されているからです。 その区別を付けるためのメンバが、is_literalです。
CRB_Stringは以下のタイミングで生成されます。 生成の時点で参照カウンタは1にセットされます。
CRB_Stringを参照するポインタは、以下の個所に存在します。
ということは、これらのポインタから参照された際、 参照数をインクリメントし、参照されなくなった時、 参照数をデクリメントすればよいことがわかります。
よって、参照数をインクリメントするのは以下のタイミングになります。
参照カウンタがデクリメントされるのは、以下のタイミングです。
たとえば、以下のような文があったとすると(hoge()関数の戻り値は文字列型とします)、
a = b = c = hoge("piyo");
まず"piyo"が評価されたタイミングで、CRB_Stringが生成され、 参照カウンタが1になります。 それが関数の引数に渡された時点では、 「引数の式の評価の終了に伴なうデクリメントと相殺され」 て参照カウンタは1のままです。 それがcに代入されてカウンタは2, 代入式の値がbに代入されてカウンタは3, それがさらにaに代入されて4になったところで、 式文の評価が終わるので、1デクリメントされて3になります。 最終的に、a, b, cという3つの変数からの参照で、参照カウンタは3になるわけです。
ところで、参照カウンタによるガベージコレクションには、 致命的な欠陥があります。それは「循環参照が解放できない」ということです。
循環参照とは、下図のように、オブジェクト同士が参照し合うことです。
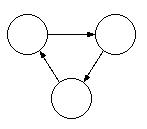
この状態では、参照カウンタは1ですから、参照カウンタ方式の GC(ガベージコレクタの略)では解放の対象にはなりませんが、 ローカル変数からもグローバル変数からも参照できなくなれば、 これらのオブジェクトは本来不要です。 つまり、参照カウンタ方式のGCは、 循環参照があったケースではメモリリークを起こす、ということです。
現状のcrowbarでは、GC対象のオブジェクトは文字列しかなく、 文字列が他のオブジェクトを参照することはあり得ませんから、 これは問題になりません。 しかし、現状のたいていの実用言語では、 オブジェクトが他のオブジェクトへの参照を保持できるようになっていますから、 そのように拡張する時点で、 参照カウンタ式のGCは見直さなければならないでしょう。
crowbarは、現時点では、ちと実用にはならない言語です。 たとえネイティブ関数をたくさん書き足すとしても、 配列もないんじゃ話にならないでしょう。
というわけで、まだ拡張する気はあるわけですが、 今後の拡張の方針はこんなふうに考えてます。
crowbar_0_1_unix.tgz
をダウンロードしてください。
展開したトップディレクトリでmakeを実行すれば、 (cc, yacc, lexが入っている環境なら)実行形式crowbarが作成されると思います。
crowbar_0_1_dos.lzh
をダウンロードしてください。
私の場合ですが、yaccの代わりにbison, lexの代わりにflex, コンパイラはMinGWを使っています。
2005/4/11追記:
cygwinもMSYSも入れていない素のWindows環境だと、
m4がないためにbisonがエラーを出すようです。
cygwinかMSYSのどちらかを入れてください。
http://gnuwin32.sourceforge.net/packages/bison.htm
MinGWはここから MinGW-3.2.0-rc-3.exeを、 bisonは ここの 「Setup」をクリックし、バイナリ(bison-1.875-1.exe)を、 同様にflexは ここの 「Setup」をクリックし、バイナリ(flex-2.5.4a-1.exe)を、 それぞれ取得し、言われるままにインストールして、パスを通しました。 MinGWについては、makeがインストールされるのですが、 「mingw32-make.exe」というファイル名になるようなので(?)、 gmakeという名前にコピーしました。
というわけで、添付のMakefileでは、makeの名前はgmake, Cコンパイラの名前はgccになっています。環境に合わせて調整してください。
うちの環境では、展開したトップディレクトリでgmakeを実行すれば、 crowbarが作成されました。
展開したディレクトリにはtest.crbというサンプルソースが入っています。
% crowbar test.crb
として実行することができます。
テキトーにテストやってるとこうなる、という見本のようなものですね(_o_)。
どちらもソースを見れば原因は一目瞭然ですので、 次バージョンで修正します。