Diksam ver.0.1の実装――DVM編
Diksam仮想マシン――DVM_VirtualMachine
それではいよいよ実行編です。
何度も書いているように、Diksamのプログラムは、
Diksam仮想マシン(Diksam Virtual Machie:DVM)により実行されます。
DVMのインストラクションセットは
こちらのページ
に一覧を載せておきました。
さて、DVMは、実装上は
DVM_VirtualMachine構造体で表現されています(dvm_pri.h)。
struct DVM_VirtualMachine_tag {
Stack stack;
Heap heap;
Static static_v;
int pc;
Function *function;
int function_count;
DVM_Executable *executable;
};
上から3つはDVMの実行中の記憶領域を保持します。
見ての通り、DVMには以下の3つの記憶領域があります。
- スタック――ローカル変数
-
前述のように、ローカル変数や関数の引数、
関数から戻るための復帰情報等はスタック上に確保されます。
DVM_VirtualMachine構造体のstackメンバの型Stackは以下のとおり。
typedef struct {
int alloc_size;
int stack_pointer;
DVM_Value *stack;
DVM_Boolean *pointer_flags;
} Stack;
これを見るとわかるように、スタックの実体はDVM_Value型の配列です。
DVM_Valueは、crowbarにおけるCRB_Valueに相当する、
Diksamで使えるあらゆる型を保持できる共用体ですが、
CRB_Valueと違い型を区別するためのタグが付いていません(DVM.h)。
typedef union {
int int_value;
double double_value;
DVM_Object *object;
int function_index;
} DVM_Value;
静的言語では型が特定できるので、型タグが不要であるわけです
――が、ガベージコレクションの際、
スタック上の値がポインタであるかどうかを判定するのは
静的な情報だけからでは難しいので(ローカル変数や引数の型はわかりますが、
計算途中の値もスタックには積まれており、その型がわからない)、
Stack構造体のpointer_flags配列によりスタック上の値が
ポインタであるかどうかを保持しています。
pointer_flags配列はstackと同じ要素数を持ち、添字が一致しています。
現状では、スタックはDVMの起動時に一定サイズで確保し、
拡張を行ないません。範囲チェックもしていないので、
深い再帰ではクラッシュする可能性があります。
「ある関数が消費するスタックの量」は静的に決定できるので
関数呼び出しの際に(必要なら)拡張すればよいのですが、
現状ではまだ手を抜いています。
Stack構造体のstack_pointerメンバが、スタックポインタ
(stack pointer)すなわちスタックのトップのインデックスを保持します。
スタックポインタが指しているのは次にプッシュした時に要素が格納される
インデックスなので、実際に要素が入っているインデックスは
スタックポインタ-1以下となります。
- ヒープ――(今のところ)文字列
-
ヒープは、参照を通じてアクセスする領域です。
Java等ではヒープにオブジェクトを保持しますし、
Diksamもいずれはそうするつもりですが、
現状ではまだクラスもオブジェクトも存在しないので、
現在ヒープに保持されるのは文字列だけです。
crowbar同様、ヒープ上のオブジェクトは連結リストで保持します。
/* オブジェクトを保持する構造体 */
struct DVM_Object_tag {
ObjectType type;
unsigned int marked:1;
union {
DVM_String string;
} u;
struct DVM_Object_tag *prev;
struct DVM_Object_tag *next;
};
/* ヒープ構造体 */
typedef struct {
int current_heap_size;
int current_threshold;
DVM_Object *header;
} Heap;
- スタティック(静的)領域――グローバル変数
-
DVM_VirtualMachineのstatic_vメンバは、
グローバル変数を保持します(staticだと予約語とかち合うため、
メンバ名はstatic_vとしています)。
Static構造体の定義は以下のとおり。
typedef struct {
int variable_count;
DVM_Value *variable;
} Static;
見ての通り、DVM_Valueの配列を保持しています。
push_static_int等のインストラクションでグローバル変数を参照する際、
オペランドで渡しているのはこの配列の添字です。
――ということは、この配列は「ひとつのDVM_Executable」
専用ということであり、現在の構造のままでは、
複数のDVM_Executableをリンクすることはできません。
というかそれはもうDVM_VirtualMachineがひとつだけ
DVM_Executableを保持しているところからして明らかなわけですが、
複数のDVM_Executableをリンクすることを考えると、
いくつか設計上の決断をしなければならないので、
今はまだ先送りにしています。
DVM_VirtualMachineの残りのメンバのうち、「pc」は、
プログラムカウンタ(program counter)を意味します。
プログラムカウンタは、バイトコードの中で、
現在実行中のインストラクションのアドレスを保持します
(ここでの「アドレス」の定義は
前のページを参照のこと)。
ジャンプ命令等では、プログラムカウンタを飛び先のアドレスに
書き換えることになります――が、実はDVM_VirtualMachine構造体メンバの
pcは、実行開始後すぐにローカル変数にコピーされ、
その後書き戻されてないので現状では役に立っていません。
残りのメンバ、functionとexecutableについてはこの下で説明します。
DVMへのDVM_Executableのロード/リンク
上でも書いたように、現状では、ひとつのDVM_VirtualMachineに対応する
DVM_Executableはひとつだけです。
DVM_ExecutableをDVM_VirtualMachineに結び付けるには、
DVM_add_executable()を使用します(追加できるDVM_Executable
はひとつだけなのにこの関数名は、羊頭狗肉のような気がしますが)。
DVM_add_executable()では、以下の処理を行ないます。
- 関数のDVM_VirtualMachineへの追加
-
繰り返しますが、ひとつのDVM_VirtualMachineに対し
DVM_Executableはひとつしか付きません。しかし、
print()のようなネイティブ関数は別途存在するわけで、
関数に関しては何らかの形でリンクを行なう必要があります。
そのためのテーブルが、DVM_VirtualMachine構造体のfunction配列です。
その型であるFunctionの定義は以下のとおり。
/* Functionの種別を見分けるためのタグ */
typedef enum {
NATIVE_FUNCTION,
DIKSAM_FUNCTION
} FunctionKind;
/* print()等のネイティブ関数を保持する */
typedef struct {
DVM_NativeFunctionProc *proc;
int arg_count;
} NativeFunction;
/* Diksamで定義された関数を参照する */
typedef struct {
DVM_Executable *executable;
int index; /* 上のexecutable内のDVM_Functionの添字 */
} DiksamFunction;
typedef struct {
char *name;
FunctionKind kind;
union {
NativeFunction native_f;
DiksamFunction diksam_f;
} u;
} Function;
各DVM_Executableで保持されていた関数は、
実行時にはこのテーブルから参照されます。
このテーブルには、print()のようなネイティブ関数も登録されているので、
このテーブルのインデックスにより、
Diksamで定義されたかネイティブであるかに関係なく、
関数を特定できます。
ところで、バイトコード中では、関数を呼び出す際には、
push_functionで関数のインデックスをスタックにプッシュしますが
(前のページを参照)、
コンパイルの時点では、DVM_Executable内のDVM_Functionのインデックスを
プッシュしていました。
よって、変換の必要があります。それを行なうのが次の過程です。
- 関数のインデックスの置き換え
-
コンパイルの段階では、push_functionでプッシュしていたのは
DVM_Executable内のDVM_Functionのインデックスでしたので、
それをDVM_VirtualMachine構造体のFunction配列のインデックスに置換します。
この操作は、あるDVM_VirtualMachineに合わせて
バイトコードに直接手を加えてしまうため、
ひとつのDVM_Executableを複数のDVM_VirtualMachineに対応付ける場合には
問題になります。
現在は単なる手抜きでこうなっていますが、いずれ、
バイトコードには手を触れないようにして、
間接参照テーブルをはさんで参照するように修正するつもりです。
- ローカル変数のインデックスの補正
-
上記手順と同時に、ローカル変数のインデックスの補正も行ないます。
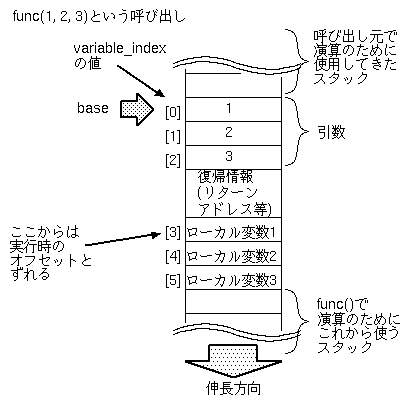
前ページの図を再掲しますが、
ローカル変数を参照する際のインデックスは、
復帰情報のサイズ分、引数のそれと離れることになります。
しかし、復帰情報のサイズはコンパイラにはわからない(本当はわかるけど
情報隠蔽の意味でわからないことにしたい)ので、
コンパイルの時点では、引数のインデックスの続きのインデックスで
参照しています。
DVM_add_executable()にてこれを補正します。
対象となるインストラクションは、push_stack_xxxとpop_stack_xxxです。
- グローバル変数のDVM_VirtualMachineへの追加
-
DVM_Executable構造体のglobal_variable配列の数だけ、
DVM_VirtualMachine構造体のstatic_v.variable配列を確保し、
値の初期化を行ないます。
実行――巨大なswitch case
ではいよいよ実行です。
DVMは仮想マシンであり、
コンパイラが生成したバイトコードを逐次実行します。
ということは、バイトコードのインストラクションの種類だけの
巨大なswitch caseを、ループでぐるぐる回せばよいわけです。
これについては直接ソースを見た方がイメージできるでしょう。
static DVM_Value
execute(DVM_VirtualMachine *dvm, Function *func,
DVM_Byte *code, int code_size)
{
int pc;
int base;
DVM_Value ret;
DVM_Value *stack;
DVM_Executable *exe;
stack = dvm->stack.stack;
exe = dvm->executable;
for (pc = dvm->pc; pc < code_size; ) {
switch (code[pc]) {
case DVM_PUSH_INT_1BYTE:
STI_WRITE(dvm, 0, code[pc+1]);
dvm->stack.stack_pointer++;
pc += 2;
break;
case DVM_PUSH_INT_2BYTE:
STI_WRITE(dvm, 0, GET_2BYTE_INT(&code[pc+1]));
dvm->stack.stack_pointer++;
pc += 3;
break;
case DVM_PUSH_INT:
STI_WRITE(dvm, 0,
exe->constant_pool[GET_2BYTE_INT(&code[pc+1])].u.c_int);
dvm->stack.stack_pointer++;
pc += 3;
break;
case DVM_PUSH_DOUBLE_0:
STD_WRITE(dvm, 0, 0.0);
dvm->stack.stack_pointer++;
pc++;
break;
case DVM_PUSH_DOUBLE_1:
STD_WRITE(dvm, 0, 1.0);
dvm->stack.stack_pointer++;
pc++;
break;
case DVM_PUSH_DOUBLE:
STD_WRITE(dvm, 0,
exe->constant_pool[GET_2BYTE_INT(&code[pc+1])]
.u.c_double);
dvm->stack.stack_pointer++;
pc += 3;
break;
case DVM_PUSH_STRING:
STO_WRITE(dvm, 0,
dvm_literal_to_dvm_string_i(dvm,
exe->constant_pool
[GET_2BYTE_INT(&code[pc+1])]
.u.c_string));
dvm->stack.stack_pointer++;
pc += 3;
break;
(後略)
えー、なんといいますか、
現時点でこの関数(execute.cのexecute()関数)は400行以上あるわけで、
しかもこれからどんどん増える予定なわけで、
「1関数は××行以下とする」などという
機械的なコーディング規約を定めているプロジェクトでは
思いきり規約に違反しそうです。
が、この関数を分割したからといって別に読みやすくはならないと思います。
「1関数は××行以下とする」という機械的なコーディング規約を
決められるほど、プログラミングという作業は機械的なものではない、
ということなのでしょう。
それはさておき、この関数内からスタックを参照するため、
いくつかのマクロを用意しています。
- STI(dvm, sp), STD(dvm, sp), STO(dvm, sp)
-
現在のスタックポインタにspを加えたインデックスで、
スタック上の要素の値を返します。
四則演算等に使用します。
二項/単項演算子はスタックのトップ近辺の値を操作するためです。
STIはint用、STDはdouble用、STOはstring(オブジェクト)用です。
以下同様です。
- STI_I(dvm, sp), STD_I(dvm, sp), STO_I(dvm, sp)
-
spで直接指定するインデックスで、スタック上の要素の値を返します。
push_stack_xxx, pop_stack_xxx系のインストラクションで使用します。
これらのインストラクションは、baseを起点としてスタックを参照するためです。
- STI_WRITE(dvm, sp, r), STD_WRITE(dvm, sp, r), STO_WRITE(dvm, sp, r)
-
スタック上の要素をSTI()等と同様の方法で指定し、
そこにrを書き込みます。
STI()等はマクロなので、「STI(dvm, 0) = ×××;」という形で
代入することも可能です。にも関わらず書き込み用のマクロを
わざわざ分けてあるのは、型がポインタであるかどうかによって、
スタックのpointer_flagをセットしなければならないためです。
- STI_WRITE_I(dvm, sp, r), STD_WRITE_I(dvm, sp, r), STO_WRITE_I(dvm, sp, r)
-
STx_WRITE()のインデックス直接指定版です。
関数呼び出し
実行が始まってしまえば、execute()関数は確かに巨大な関数ではありますが、
個々のインストラクションで行なっていることはせいぜい数行レベルです。
ややこしいのは関数呼び出し程度でしょう。
ここではそれについて説明します。
関数呼び出しは以下の順序で行なわれます。
- 引数を前から順にスタックに積む。
- push_functionにて、関数のインデックスをスタックにプッシュする。
ここまで実行した時点で、スタックは以下の状態になっています。
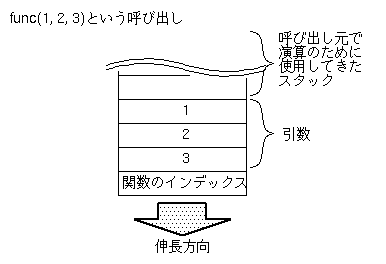
ここでinvokeが実行されます。
- invokeを実行し、スタックトップの関数を呼び出す
もし関数がネイティブ関数なら、ここで実際にその関数を呼び出します。
Diksamのネイティブ関数の呼び出し形式は以下のようになります(print()関数の例)。
static DVM_Value
nv_print_proc(DVM_VirtualMachine *dvm,
int arg_count, DVM_Value *args)
{
引数としてDVM_Valueの配列を渡すのですが、
ちょうどスタック上に最初の引数から順に並んでいるので、
最初の引数へのポインタを渡せばOKです。
Diksamの関数を呼び出す場合、以下の手順をとることになります。
- 復帰情報をスタックに積む。
- baseの値を設定する。
- ローカル変数の値を初期化する。
- 実行中のexecutableと関数を差し替える。
- プログラムカウンタを0にし、実行を開始する。
ここまで復帰情報復帰情報と言ってきましたが、
それはCallInfo構造体で表現されています。
typedef struct {
Function *caller;
int caller_address;
int base;
} CallInfo;
callerは呼び出し元の関数を指し、caller_addressは
その関数内でのバイトコード上のアドレスを指します。
baseは、呼び出し元のbase(引数やローカル変数を参照する起点)を指します。
関数が呼び出される時点で、
スタックにはいろいろと計算途中の値が積まれていますから、
baseをCallInfoで保持しておかないと関数が終わった時点で復帰できません。
CallInfo構造体は、呼び出す関数のインデックス
(push_functionで積んだもの)を上書きして配置されます。
その後新たなbaseを設定し、ローカル変数の領域を確保するので、
呼び出された関数の実行を開始する時点では、
スタックは下図の状態になります。
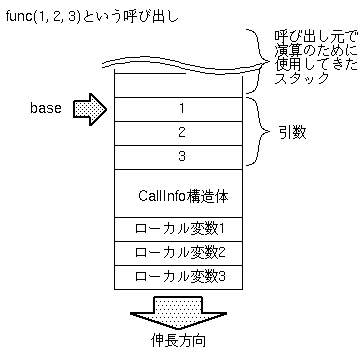
この状態から、呼び出され側の関数を実行するわけです。
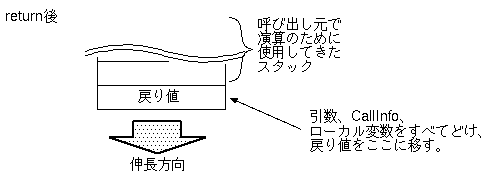
逆に関数からreturnする場合どのように動作するかですが、
関数は最後にreturnを実行して終わりますから、
関数終了時には必ずローカル変数の次の位置に戻り値が
保存されています。
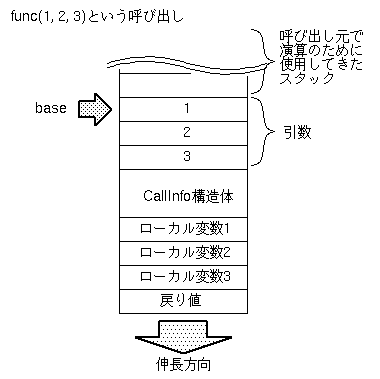
引数、CallInfo、ローカル変数をすべてどけ、
その後、戻り値をスタックのトップに置けば、
関数呼び出しが式評価の途中で起きていたとしても、
正しくその式の中で関数の戻り値を使用できるわけです。
今後のこと
長いこと放置してしまいましたので、
今回はとにかく早期なりリースを目指しました。
よって、正直、Diksamの実装においてはアレなところがいろいろあります
(深い再帰でクラッシュするとか)。
そういうところを直しつつ、機能面では、
以下の順序でやっていこうと思います。
- 配列および、関数型変数の実装。
- 複数ファイルのリンク。下準備は済ませているつもりなので…
- クラスの導入。
それではまた気長にお待ちくださいませ。
前のページ |
次のページ |
ひとつ上のページに戻る |
トップページに戻る