Diksam ver.0.1では配列が使えませんが、 いくらなんでもこれでは実用に耐えないので、 配列を導入することにします ――はっ、この書き出しは前回と同じではないか。
GLOBALをかましたソースは こちらから参照可能です。
ダウンロードは、UNIX版がこちら、 Windows版がこちら。
Diksamの配列の仕様は、ほぼJavaと同様です。
まず、Diksamでは変数には宣言が必要です。 当然(?)配列型の変数にも宣言が必要であり、Java風に以下のように書きます。
int[] a; // intの配列型変数を宣言
配列を生成する際の構文もJavaと同様です。
// a[2][4]までアクセス可能な配列が生成される。 a = new int[3][5];
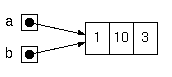
crowbarやJavaと同様、Diksamの配列は参照型です。 よって、下記のように書けば、「a[1]..10」と表示されます。
int[] a = {1, 2, 3};
int[] b = a; // aとbは同じ配列を指す
// よって、b[1]を変更すればa[1]も変更される
b[1] = 10;
print("a[1].." + a[1] + "\n");
言うまでもないですが、これは、a, b ふたつの変数が同じ配列を指しているためです。
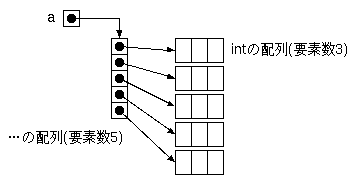
また、多次元配列(のように見えるもの)は、 実際には配列の配列です。 つまり、a = new int [3][5];と書いたときaに得られるものは 「intの配列(要素数3)の配列(要素数5)」です。 そして、配列は参照なので、図にすると下図のようになります。
ところでJavaの場合、配列型の変数を宣言と同時に初期化する場合だけ 以下のように書けますが、
int[] a = {1, 2, 3};
それ以外の個所では、配列のリテラルは以下のように書かなければなりません。
a = new int[] {1, 2, 3};
Java(やDiksam)のような静的型付け言語では 型を明示的に指定しないといけない、という事情はわかるのですが、 この「new int[]」の部分はなんとも冗長ですし、 初期化とそれ以外で構文が違うというのも、 コンパイラを両方の構文に対応させなければならなくて (言語実装者の都合から)気に入りません。 そこでDiksamでは、配列リテラルの型は「最初の要素の型」の配列とする、 ということにしました(これは Dを真似ました)。 つまり、下記のように書けば、
double[] a = {1.0, 2, 3}
2番目、3番目の要素はdoubleにキャストされ、{1.0, 2.0, 3.0}からなる doubleの配列がaに代入されることになります。
なお、上に書いたように、Diksamでは「a = new int[5][3];」 と書くことで、a[0][0]からa[4][2]までアクセス可能な配列が生成されます。
これはJavaを真似ているわけですが、 Dでは、a[0][0]からa[4][2]までアクセス可能な配列が欲しければ 「int[3][5] a;」と書きます(これは静的配列です。new を使って動的に割り当てるときにはnew int[][](3, 5)と書くようです)。
JavaやDiksamで「new int[5][3];」により得られるものは、 「intの配列(要素数3)の配列(要素数5)」であり、Javaでは、 これを左から順に読んでいくことができません。 その点、Dでは、日本語順で左から順に読めますから、 こちらの方が自然であると言えるわけですが、 さすがに、 現在広く使われているJava等と似た構文で違う意味になるのでは 混乱を招きそうですから(ていうか私自身混乱しそうですから)、 DiksamはJavaに合わせました ――Cの宣言の構文にケチつけて本1冊書いた奴が今さら日和るのかよ、 とか言われそうですが※1。
言語仕様の決定というのはこの手の妥協の連続ですね。 私も、もう若くないさと君に言い訳するくらい歳を食ったということでしょうか。 うーん。
配列関連で今回追加した構文規則は以下の通りです。
まず、1の型指定子については、従来は
type_specifier
: BOOLEAN_T
| INT_T
| DOUBLE_T
| STRING_T
;
のように基本型が書けるだけでしたが、今回は、 従来の基本型をbasic_type_specifierとし、 下記のようにしました。
type_specifier
: basic_type_specifier
| type_specifier LB RB
;
type_specifierはそれ自体[]を含むことができるので、 このように書くことで、「int[][][]」のように []をいくつでも付けられるわけです。
2の、newによる配列の生成構文は、一見するより厄介です。
たとえばJavaで「new int[10]」と書いて得られるものは、 intの配列(要素数10)です。
ということは、これに[5]という添字を付けて 「new int[10][5]」と書けば、 「new int[10]」で得られた配列の5番目 ※2 の要素が得られる――はずはなく、当然これは2次元配列の生成を意味します。 つまり、添字演算子[]は、通常の式には適用できても、 newによる配列生成(array_creation)には適用できないように しなければなりません。
そこで、Diksam1.0では式を構成する最小の式 (演算子の優先順位最強のカタマリ)は 「primary_expression」でしたが、これを「newによる配列生成」と 「それ以外のもの」に分け、
primary_expression
: primary_no_new_array /* newによる配列生成以外のもの */
| array_creation /* newによる配列生成 */
;
かつ、3の添字演算子のところで、 以下のようにして、添字演算子の[](LBとRBは、それぞれLeft Bracketと Right Bracketで[と]のことです)がnewによる配列生成にはくっつかない ようにしています。
primary_no_new_array
: primary_no_new_array LB expression RB
(後略)
……とか偉そうに書いてますが、これはまるごと Javaの構文規則のパクリなんですけどね。
さて、Diksamのコンパイラにおいて、型はTypeSpecifier構造体にて 保持されています。
TypeSpecifier構造体については、 こちらでざっと説明しました。 要は、基本型(DVM_BasicType)を保持するTypeSpecifier構造体と、 そこから連結リストでつながった派生型(TypeDerie)で型を表現している わけです。 該当部分のソースは以下のとおり。
typedef enum {
FUNCTION_DERIVE,
ARRAY_DERIVE
} DeriveTag;
typedef struct {
ParameterList *parameter_list;
} FunctionDerive;
typedef struct {
int dummy; /* make compiler happy */
} ArrayDerive;
typedef struct TypeDerive_tag {
DeriveTag tag;
union {
FunctionDerive function_d;
ArrayDerive array_d;
} u;
struct TypeDerive_tag *next;
} TypeDerive;
struct TypeSpecifier_tag {
DVM_BasicType basic_type;
TypeDerive *derive;
};
前回は、派生型は「関数型」の派生しかありませんでしたが、 今回、配列の派生が追加されています(TypeDeriveのtagにARRAY_DERIVEが入る)。
fix_expr.cにて、式の各ノードにはTypeSpecifier構造体が付加されます。 たとえばint[][] a;と宣言された変数aの場合、 これに付加されるTypeSpecifierには、 配列派生のTypeDeriveがふたつ連結リストになったものが deriveメンバに繋がれます(basic_typeにはDVM_INT_TYPEが入る)。 そして、a[10]のように添字演算子を付けて参照された場合、 TypeDeriveの連結リストの先頭のひとつがひっぺがされたものが その式全体の型となります。当然a[10][3]のように書けば、 ふたつともひっぺがされて式の型はintとなります。
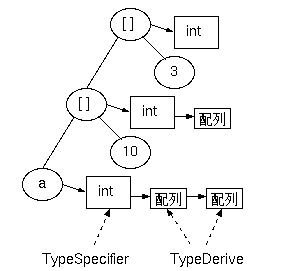
上の図で、丸の中に[ ]で表現されているものは、 添字演算子IndexExpressionです。 これは、Expression構造体の中の共用体の一種で、 以下のように、配列と添字の式を保持します。
typedef struct {
Expression *array; /* 配列側の式 */
Expression *index; /* 添字側の式 */
} IndexExpression;
今回、配列の追加により、DVMに追加したインストラクションは以下の通りです。
| 命令 | オペランドの型 | 意味 | スタック |
|---|---|---|---|
| push_array_int | スタック上の配列と添字から、配列の要素(int型)を取得し、 それをスタックに積む。 | [array int] → [int] | |
| push_array_double | スタック上の配列と添字から、配列の要素(double型)を取得し、 それをスタックに積む。 | [array int] → [double] | |
| push_array_object | スタック上の配列と添字から、配列の要素(object型)を取得し、 それをスタックに積む。 | [array int] → [object] | |
| pop_array_int | スタック上の値(int1)を、配列arrayの添字int2の要素に代入する。 | [int1 array int2] → [] | |
| pop_array_double | スタック上の値(double)を、配列arrayの添字intの要素に代入する。 | [double array int] → [] | |
| pop_array_object | スタック上の値(object)を、配列arrayの添字intの要素に代入する。 | [object array int] → [] | |
| new_array | byte, short | オペランドのshortで示される型の配列を、 byte次元だけ、スタックで指定されるサイズ分生成し、スタックに積む。 | [size1 size2 ...] → [array] |
| new_array_literal_int | short | スタックに積まれた、オペランドで与えられる数だけのint型要素から、 配列を生成しスタックに積む。 | [int1 int2 int3 ...] → [array] |
| new_array_literal_double | short | スタックに積まれた、オペランドで与えられる数だけのdouble型要素から、 配列を生成しスタックに積む。 | [double1 double2 double3 ...] → [array] |
| new_array_literal_object | short | スタックに積まれた、オペランドで与えられる数だけのobject型要素から、 配列を生成しスタックに積む。 | [object1 object2 object3 ...] → [array] |
見てわかるように、「object型」というのが登場しています。 これは、前回は文字列しかなかった参照型に配列が追加されたため、 文字列と配列を統合する型です。 これに伴い、前回push_static_string等であったインストラクションは、 文字列比較等の実際に文字列を扱うものを除き、 push_static_objectといったインストラクションに変更されました。
上記のインストラクションのうち、 new_arrayは追加の説明が必要かと思います。
「オペランドのshortで示される型」とありますが、 このオペランドは、 DVM_Executableに今回追加されたDVM_TypeSpecifier 配列の添字を意味します(DVM_LineNumberとかいうのも増えていますが、 これについては後述)。
struct DVM_Excecutable_tag {
int constant_pool_count;
DVM_ConstantPool *constant_pool;
int global_variable_count;
DVM_Variable *global_variable;
int function_count;
DVM_Function *function;
int type_specifier_count;
DVM_TypeSpecifier *type_specifier;
int code_size;
DVM_Byte *code;
int line_number_size;
DVM_LineNumber *line_number;
int need_stack_size;
};
DVM_TypeSpecifier構造体は、 コンパイラのTypeSpecifierと同等の情報を持ちます。 たとえば「new int[5][3]」という配列生成では、 「int[][]」という型情報を持つDVM_TypeSpecifierの添字を new_arrayのオペランドで指定します。
さて、このようにしてDVM_TypeSpecifierを見れば配列の次元数は わかるのですが、int[][]型の配列を 「new int[5][]」のように生成することもできるので、 実際に生成する次元数(この場合は1)を、もうひとつのbyte型の オペランドで与えます。 なお、「a = new int[5][];」として生成された配列は、 Java同様、a[0]~a[4]がnullで初期化されます。
ところで、DVMでは、配列リテラルの生成は、 上記のようにスタック上に積まれたたくさんの値から行うわけですが、 JVMにはこれに相当するインストラクションがありません。 では、初期化子で配列生成する時やnew int[] {1, 2, 3} とか書いた時の配列生成はどうなっているのかと、 javapかけたらこうでした。
元ソース:
class Test {
public static void main(String[] args) {
int[] a = {1, 2, 3, 4, 5}; 0: iconst_5
}
}
javapの結果(インストラクション部分のみ抜粋):
0: iconst_5 1: newarray int 3: dup 4: iconst_0 5: iconst_1 6: iastore 7: dup 8: iconst_1 9: iconst_2 10: iastore 11: dup 12: iconst_2 13: iconst_3 14: iastore 15: dup 16: iconst_3 17: iconst_4 18: iastore 19: dup 20: iconst_4 21: iconst_5 22: iastore 23: astore_1 24: return
これはつまり、
int[] a = new int[5]; a[0] = 1; a[1] = 2; a[2] = 3; a[3] = 4; a[4] = 5;
と書くのと同じですね……いや、別にいいんですが。
DiksamにしろJavaにしろ、配列リテラルおよび初期化子による配列の生成では、 その中身は「実行時」に決まります。なので、
int[] a = {b * 10, func()};
といったように、初期化子の中に、 実行時にしか決まらない式を書くことが可能です。
それに対し、Cでは、配列を初期化子で初期化することはできますが、 その中身はすべて定数式でなければなりません。
こうすると、コンパイル時に あらかじめ配列のメモリイメージを生成しておいて、 static変数の場合は実行開始時に、自動変数の場合は関数に入った時に、 そのイメージをメモリに貼り付けるだけで初期化が可能になります。
今回、配列が追加されたことで、 DVM_Objectにも配列メンバが追加されました(dvm_pri.h)。
struct DVM_Object_tag {
ObjectType type;
unsigned int marked:1;
union {
DVM_String string;
DVM_Array array;
} u;
struct DVM_Object_tag *prev;
struct DVM_Object_tag *next;
};
DVM_Arrayの中身は以下の通り。
typedef enum {
INT_ARRAY = 1,
DOUBLE_ARRAY,
OBJECT_ARRAY,
FUNCTION_INDEX_ARRAY
} ArrayType;
struct DVM_Array_tag {
ArrayType type;
int size;
int alloc_size;
union {
int *int_array;
double *double_array;
DVM_Object **object;
int *function_index; /* 未使用 */
} u;
};
crowbarでは、配列は「CRB_Valueの配列」でした。 今回も、DVM_Valueという共用体はあるので、 その配列にするという手もあるのですが、 Diksamは静的言語なので配列の型は静的に決まっています。 intの配列にdoubleが入ることは決してありません。
となれば、intの配列は「sizeof(int) × 要素数」 で確保した方が無駄がないですし、 Cの組み込みルーチンに渡す時も扱いが楽です。 というわけで、列挙型ArrayTypeで配列の要素の型を示しています。 ArrayTypeはDiksamの型とは必ずしも対応しません。 たとえば文字列の配列であっても、配列の配列であっても、 どちらもOBJECT_ARRAYです。 配列の型はコンパイル時に決定しているので、実行時にここで保持する 必要はないためです※3。
今回修正したところは配列の他にもいくつかありますが、 うちひとつは、「深い関数呼び出しでも死なないようにした」ことです。
ver.0.1のDVMは、スタックのサイズを固定長で保持しており、 深い再帰等でそれをオーバーすると、あっさり配列のオーバーランを 起こしていました。Cとかならそれも許されるでしょうが、 Diksamではそういうわけにはいきません。
これを避けるには足りなくなったところでスタックをrealloc()して ニョキニョキ伸ばせばよいのですが、 なにしろスタックへのプッシュは頻繁に行なわれるので、 その度にサイズをチェックしていたのでは効率に悪影響が出ます。
そこで、チェックするは「関数が呼び出されたタイミング」に限定し、 そのタイミングで「その関数が使用する最大スタックサイズ」が 残っているかどうかをチェックします。
で、「その関数が使用する最大スタックサイズ」はどう求めることが できるかですが、Diksamのコンパイラは、たとえば以下のような バイトコードは決して生成しません。
10 push_int_1byte 5 12 jump 10
こんなバイトコードが実行されたら、無限ループでスタックを食い潰して しまうのですが、Diksamの文法上こんなコードは出てきません。 上の例では無限ループですが、無限ではないループでも同じです。
よって、関数内のインストラクションすべてについて スタック消費量を足し合わせれば、その関数はそれ以上のスタックを 食うことはありません――実際には、スタックからポップする インストラクションもあるので、インストラクションを頭からスキャンして、 プッシュする時に増加、ポップする時に減少させた値の最大値で よいはずですが、面倒なので(大きい方に合わせて困ることもないので) 現状ではポップする方は計上していません。
配列や文字列は参照型なので、nullを追加しました。
これに伴い、従来は未初期化の文字列変数には空文字列が入っていましたが、 現状ではnullになっています。
現状のDiksamでは、実行時エラーが出た時その行番号を表示できませんでした。 しかし、実際問題として、行番号すら出ないのではデバッグもできません。 こういうところは、言語の機能として陽に評価はされにくいですが、 実用上は重要であると思います。
実行時にわかるのはバイトコードのインストラクションの位置(pc) だけですから、この情報からソースの行番号を表示するためには、 pcから行番号が引けるだけの情報がなければいけません。
そのため、DVM_ExecutableにDVM_LineNumberの配列を追加しました。
struct DVM_Excecutable_tag {
int constant_pool_count;
DVM_ConstantPool *constant_pool;
int global_variable_count;
DVM_Variable *global_variable;
int function_count;
DVM_Function *function;
int type_specifier_count;
DVM_TypeSpecifier *type_specifier;
int code_size;
DVM_Byte *code;
int line_number_size;
DVM_LineNumber *line_number;
int need_stack_size;
};
DVM_LineNumber構造体の定義は以下のとおり。
typedef struct {
int line_number; /* ソースの行番号 */
int start_pc; /* pcの開始位置 */
int pc_count; /* start_pcから、何バイト同じline_numberの
インストラクションが続くか*/
} DVM_LineNumber;
この情報は、generate.cのgenerate_code()関数で、 バイトコード生成と同時に生成しています。
今回、配列を導入しましたが、今時の言語を知っている人からすれば、 配列を導入したからには当然こういう機能もあるのではないか、 と期待する人もいることでしょう。
どれも今時の言語ではたいていできることですし(配列を表示すると 平気でハッシュ値だかアドレスだかを表示する言語もありますが)、 crowbarではできていたことでもあるのですが、 今回は見送りました。
ま、どれもCにはないしー。とか言ってしまうとアレですが、 どれも結局「メソッド」に帰着するので(print()で配列の内容を 表示するのも、toString()メソッドですし)、 クラスの仕様をもうちょっと考えてからの方がよいのではないかと 思っています。
また長いこと放置してしまいましたので、 今回も結局早期なリリースを目指すことになりました。 色々ヘンなところろを直しつつ、機能面では、 以下の順序でやっていこうと思います。
それではまた気長にお待ちくださいませ。