解析木を帰りがけ順で辿りつつ、バイトコードを生成します。 generate.cにて実施しています。
解析木の構築(create.c)
解析木の構築に関しては、crowbarのそれとさほど変わるところはありません。 多少違いがあるところといえば、「ブロック」の扱いくらいです。
Diksamでは、ローカル変数のスコープは、それが宣言されたブロックの中です。
たとえば式の中で「a」という変数が使用された時、 コンパイラは、まず最内周のブロックに「a」の宣言がないかどうかを探し、 なければその外側のブロックに探しに行きます。 これを実現するため、ブロックにouter_blockというメンバを入れています。
typedef struct Block_tag {
BlockType type;
struct Block_tag *outer_block;
StatementList *statement_list;
DeclarationList *declaration_list;
union {
StatementBlockInfo statement;
FunctionBlockInfo function;
} parent;
} Block;
outer_blockは外周のブロックへのポインタを保持します。
outer_blockを設定するには、Block構造体が確保された時点で、 現在のブロック(新たに確保するブロックのひとつ外周のブロック)が わからなければなりません。 そのために、コンパイラ本体(DKC_Compiler)にてcurrent_blockを保持しています。
struct DKC_Compiler_tag {
MEM_Storage compile_storage;
FunctionDefinition *function_list;
int function_count;
DeclarationList *declaration_list;
StatementList *statement_list;
int current_line_number;
Block *current_block;
DKC_InputMode input_mode;
};
このcurrent_blockをセットするタイミングは、 ブロックが開始された時(パーサが「{」を読み込んだ時)です。 たとえばcrowbarではcrowbar.yに以下のように記述されていましたが、
block
: LC statement_list RC
{
$$ = crb_create_block($2);
}
| LC RC
{
$$ = crb_create_block(NULL);
}
;
この方法では、ブロックが閉じる時までアクションが動きません。
これでは困るので、diksam.yでは、規則の途中にアクションを突っ込んでいます。
/* 規則はあくまで「LC statement_list RC」 */
block
: LC
{
$$ = dkc_open_block();
} ←この続きが「;」でも「|」でもないのがミソ
statement_list RC
{
$$ = dkc_close_block($<block>2, $3);
}
「LC RC」という規則もあるが、省略
このようなアクションを埋め込みアクションと呼びます。
yaccは、埋め込みアクションのある場所にダミーのターゲットを埋め込み、 埋め込みアクションを、そのダミーターゲットのアクションとして扱います。 つまり、
block
: LC { 埋め込みアクション } statement_list RC
{
ブロックが閉じた時に動くアクション
}
;
と書くことは、以下のように書くのと同値です。
block
: LC dummy_target statement_list RC
{
ブロックが閉じた時に動くアクション
}
;
dummy_target
: /* empty */
{
埋め込みアクション
}
;
ダミーターゲット部分は型の宣言をしていないので、 埋め込みアクションで$$に設定している値を使用したければ、 「$<型>」のように記述します。 よって、下記のdiksam.yの抜粋にて、
block
: LC
{
$$ = dkc_open_block();
}
statement_list RC
{
$$ = dkc_close_block($<block>2, $3);
}
dkc_close_block()の引数に$<block>2, $3を渡していますが、 この$<block>2は、埋め込みアクションで$$に設定している値となりますし、 statement_listは(埋め込みアクションの分ひとつずれて)$3になります。
解析木の確定(fix_tree.c)
上でも少し書きましたが、解析木の確定フェーズでは、 以下の処理を行ないます。
定数部分式の畳み込み
これはcrowbarでも実施していましたが、 Diksamにおいても、式中の定数部分式(「24*60」といった式)は、 コンパイルの時点で定数に畳み込みます。 現状のDiksamでは、数値の加減乗除と剰余、+による文字列連結、 単項マイナス、比較、単項の!が対象です。
式への型の付与
Diksamでは、式の解析木の各ノードは型を保持します。
struct Expression_tag {
TypeSpecifier *type; ←ここで型を保持
ExpressionKind kind;
int line_number;
union {
DVM_Boolean boolean_value;
int int_value;
double double_value;
DVM_Char *string_value;
IdentifierExpression identifier;
CommaExpression comma;
AssignExpression assign_expression;
BinaryExpression binary_expression;
Expression *minus_expression;
Expression *logical_not;
FunctionCallExpression function_call_expression;
MemberExpression member_expression;
ExpressionList *array_literal;
IndexExpression index_expression;
IncrementOrDecrement inc_dec;
CastExpression cast;
} u;
};
たとえば「3」のような整数値のノードはint型に決まっていますし、 int型の変数の型もint型に決まっていますが、(1 + 0.5)のような式の型は、 右辺と左辺を見て、適切な型拡張を行なわなければなりません。
上のコードにあるように、 Expression構造体ではtypeメンバが型を保持していますが、 その指す先にある構造体TypeSpecifierの定義は以下のようになっています。
struct TypeSpecifier_tag {
DVM_BasicType basic_type;
TypeDerive *derive;
};
DVM_BasicTypeは下記のような列挙型です (定義は/include/DVM_code.hにあります)。 この列挙型で、「基本型」を表現します。
typedef enum {
DVM_BOOLEAN_TYPE,
DVM_INT_TYPE,
DVM_DOUBLE_TYPE,
DVM_STRING_TYPE,
DVM_NULL_TYPE
} DVM_BasicType;
そして、もうひとつのメンバであるderiveは、「派生型」を表現します。 関連する型定義は以下のとおり(定義はdiksamc.hにあります。 似たような型定義がDVM_code.hにもありますが、そのへんの関係は後述)。
typedef enum {
FUNCTION_DERIVE,
} DeriveTag;
typedef struct {
ParameterList *parameter_list;
} FunctionDerive;
typedef struct TypeDerive_tag {
DeriveTag tag;
union {
FunctionDerive function_d;
} u;
struct TypeDerive_tag *next;
} TypeDerive;
struct TypeSpecifier_tag {
DVM_BasicType basic_type;
TypeDerive *derive;
};
列挙型DeriveTagは派生型の種類を表現します。 現在のDiksamには配列も何もないので、 存在する派生型は関数型(FUNCTION_DERIVE)だけです。 関数の派生型の定義はFunctionDeriveが保持します。 具体的には、引数の型情報です。
派生型とはそもそも何か、という話は、「C言語 ポインタ完全制覇」 に書いたので――と言いたいところですが (「配列とポインタの完全制覇」にも書いたのでこっちならタダで読めます) 例によって軽く説明すると、
たとえばDiksamのprint()関数の定義は以下のようになっています。
int print(string str);
この時、「print」という識別子の型は、 「int を返す関数(引数はstring)」 です。※1 これに対し関数呼び出しの演算子()を適用すると、 「を返す関数(引数はstring)」の部分がひっぺがされて、 int型になります。
TypeDeriveにはメンバnextがありますから、 型派生は連結リストで連結されます。よって、 「int を返す関数(引数はstring) を返す関数(引数なし)」 等も表現できますし(ただし、現在はそういう型を宣言する構文がないので 使えませんが)、 配列も派生型の一種とすれば、 「int の配列の配列を返す関数(引数はstring)」 といったものも表現できるわけです(もちろん現在は配列がないのですが)。
――つか、どうせ使えないのなら、 今の段階では関数呼び出しの構文規則を
primary_expression
: IDENTIFIER LP parameter_list RP
;
としておけば、派生型を表現する必要もなかったんですけどね…
キャストノードの追加
式に型を付けていく過程で、 先に説明した キャストノードの追加を行ないます。
現在、コンパイル時に暗黙に行なわれる型変換は以下の通りです。
- 二項演算子における型変換
- intとdoubleの演算ではintをdoubleに変換します。 また、左辺がstringの演算では、右辺をstringに変換します。
- 代入における型変換
- 代入時には、左辺の型に右辺の型を合わせます (+=のような代入でも同様です)。 関数の実引数および関数の戻り値についても、 代入時と同様の変換を行ないます。
関数内の宣言
「int a;」という宣言文がある時、create.cの段階で、 Declaration構造体を生成します。その定義は以下の通りです。
typedef struct {
char *name;
TypeSpecifier *type;
Expression *initializer;
int variable_index;
DVM_Boolean is_local;
} Declaration;
create.cの段階では、Declaration構造体のうち、 変数名(name)、型(type)、およびあれば初期化子(initializer)を 設定しています。
関数内での宣言の有効範囲はブロックですから、 Declaration構造体をブロックで保持するようにします。 上でも挙げましたが、ブロックはBlock構造体にて定義されていて、 その中のdeclaration_listが該当ブロックでの宣言を保持しています。
typedef struct Block_tag {
BlockType type;
struct Block_tag *outer_block;
StatementList *statement_list;
DeclarationList *declaration_list;
union {
StatementBlockInfo statement;
FunctionBlockInfo function;
} parent;
} Block;
まず、関数の仮引数は、関数内ではローカル変数として使えますから、 その関数の最外周のブロックでの宣言として追加します。 その後、ローカル変数を追加します。 ブロックはネストできますから、 fix_xxx系の関数は現在のブロックを引数として持ち歩いています。
同時に、Declaration構造体のうち未設定であった variable_indexとis_localの設定も行ないます。
is_localは、ローカル変数であるかどうかのフラグですから、 関数内での宣言ではTRUEにします。 variable_indexは、関数内で宣言された順に採番されます (最初の仮引数が0)。
ローカル変数(引数含む)はスタックに確保しますが、 スタック上の変数は「ベース」からのオフセットで参照できる、 ということをこのへんで 説明しました。variable_indexはこの「オフセット」になる ――とよいのですが、ここは少々複雑です。
後述しますが、Diksamの場合スタックはDVM_Value型の配列で 実現されており、添字の大きい方に向かって伸びます。 よって、Diksamに即した図にすると、以下のようになります。
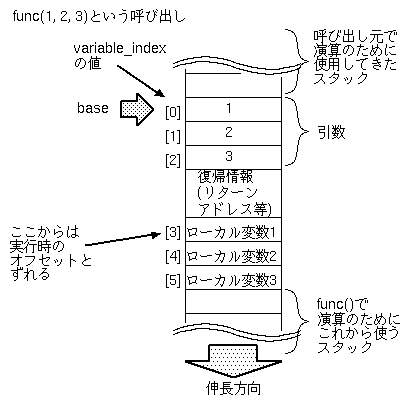
現在のコンパイラの実装では、variable_indexは、 最初の仮引数をゼロとして順に振っていくだけであり、 「復帰情報」の分を考慮していません。 よって復帰情報より下のローカル変数では、 variable_indexと実行時のオフセットがずれてしまいます。
もちろん、復帰情報のサイズは分かっていますから、 ローカル変数についてその分を加えた値を振ることは容易です。 しかし、復帰情報のサイズはDVM側の実装依存なので、 それに依存する値をバイトコードに埋め込んでしまうのは 避けたいところです。 もっとも、現状ではバイトコードはメモリ上に生成されるだけで ファイルに保存されるわけではないので、 埋め込んでしまっても実害はなさそうですが、 将来的にJavaのクラスファイルに相当するものを吐けるようにしたいとの 思いはあります。 その時、DVMのバージョンが上がって復帰情報のサイズが変わった瞬間、 過去のコンパイル済みファイルが使えなくなってしまっては 困るでしょう。
そこで、Diksamのコンパイラでは、ひとまず連番で振っておいて、 実行前(DVMにロードした時点)で変換しています。
また、ブロック内で新たなローカル変数が宣言できるということは、
if (a == 10) {
int a;
……
} else {
int b;
……
}
というようなコードがあったとき、aとbには同じ領域 (同じvariable_index)を割り当てればスタックが節約できそうですが、 Diksamではこのような場合も別々のインデックスを振っています。
Diksamでは初期化されていないローカル変数の値が決まっていて Cのように不定値ではありません。 string型などは実装上はポインタですから、 不定値にすると実行時にDVMごとクラッシュしてしまいます。 インタプリタ型の言語としてはこれは許容できません。
上記のaとbで型が異なる場合、別々の領域が割り当てられていれば、 初期化は関数呼び出し時の一度で済むわけです。
識別子と宣言との対応付け
式の中の変数や関数名を保持しているのは、 Expression構造体の共用体メンバとして保持されている IdentifierExpression構造体です。
typedef struct {
char *name;
DVM_Boolean is_function;
union {
FunctionDefinition *function;
Declaration *declaration;
} u;
} IdentifierExpression;
このfunctionまたはdeclarationが、 関数定義または変数宣言を指すように設定します。
Diksam実行形式――DVM_Executable
さて、fix_tree.cを抜けたらいよいよバイトコードを生成します。
ただし、実行時に必要なのは、必ずしもバイトコード (DVMが実行する機械語のようなコード)だけではなく、 グローバル変数の一覧等、他の情報も必要です。 Diksamでは、バイトコードおよびそういった関連情報を保持する構造体として、 DVM_Executableという構造体を定義しています。 generate.cですべきことは、「DVM_Executable構造体を生成すること」 であるわけです。
というわけで、まずDVM_Executable構造体について以下に説明します。
DVM_Executable構造体
DVM_Executable構造体は、DVM_code.hで定義されています。
struct DVM_Excecutable_tag {
int constant_pool_count;
DVM_ConstantPool *constant_pool;
int global_variable_count;
DVM_Variable *global_variable;
int function_count;
DVM_Function *function;
int code_size;
DVM_Byte *code;
};
見ての通り、可変長配列で、以下のものを保持しています。
- コンスタントプール(constant_pool)
- 定数を保持する領域です。
- グローバル変数(global_variable)
- グローバル変数の一覧を保持します。
- 関数(function)
- 関数定義を保持します。 関数の分のバイトコードは、この中(DVM_Function)に保持しています。
- トップレベルのコード(code)
- Diksamではトップレベル(関数の外)にコードが書けますが、 そのバイトコードを保持しています。
コンスタントプール
「コンスタントプール」というのは、定数を保持する領域です。
たとえばdoubleの値をスタックに積む際、 前に出した例では、
push_double 2.5
のように書きました。
これを実際にバイトコードとして出力する場合、 「push_double」という命令には 何らかのコードが割り当てられていることでしょう。 DVMの場合、10進で「6」です。
というわけで、「6」という1バイトをバイトコードとして 出力するのはよいとして、「2.5」はどうすべきでしょうか。 私の環境ではdoubleは8バイトですから、 「6」の続きにその8バイトを出力するのでしょうか。
正直、現状のDiksamは、バイトコードはメモリに保持するだけなので、 コンパイラの環境のdouble型のバイナリ表現をそのままバイトコード中に 突っ込んでも構わないかもしれません。しかし、バイトコードを ファイルに出力するようになったら困るでしょう。 そのバイトコードを実行するマシンは、コンパイルしたマシンとは 異なる表現形式でdoubleを保持しているかもしれないからです。
そこで、「バイトコード中では何らかの正規化された表現で保持しておいて、 読み込んだ時点で変換する」という処理が必要になるのですが、 その際、バイトコードの真ん中にポンと「2.5」が埋まっていると 変換が面倒です。 また、実数だけでなく文字列についても、 バイトコード中に「"hello, world\n"」を埋め込むのは 普通のプログラマなら美しくないと感じるのではないでしょうか。
そこでコンスタントプールです。コンスタントプールの配列の各要素は 以下のような構造体です。
typedef enum {
DVM_CONSTANT_INT,
DVM_CONSTANT_DOUBLE,
DVM_CONSTANT_STRING
} DVM_ConstantPoolTag;
typedef struct {
DVM_ConstantPoolTag tag;
union {
int c_int;
double c_double;
DVM_Char *c_string;
} u;
} DVM_ConstantPool;
見ての通り、intまたはdoubleまたは文字列を保持できる共用体になっています。
Diksamのバイトコードにおいては、
- 負または65536以上の整数
- 0または1以外の実数
- 文字列
については、コンスタントプールに格納されます。 バイトコードからはコンスタントプールでのインデックスを指定します。
1~2バイトの整数および0または1の実数については、 下記の専用命令が用意されています。
- push_int_1byte
- バイトコード上では、この命令の直後に1バイトの整数が格納されています。
- push_int_2byte
- バイトコード上では、この命令の直後に、 ビッグエンディアンで2バイトの整数が格納されています。
- push_double_0
- 実数演算で定数0が登場するケースはそれなりにあるので、 命令を分けています(ていうかJVMの真似ですが)。
- push_double_1
- 実数演算で定数0が登場するケースはそれなりにあるので、 命令を分けています(これもJVMの真似ですが)。
なお、「コンスタントプールのインデックス」といっても 1バイトでは(たぶん)足りないので、現状のDiksamの実装では 2バイトになっており、「push_double」のような命令の直後に 2バイトの整数値がビッグエンディアンで格納されています ――2バイトじゃ足りないんじゃないか、 という懸念はごもっともです。どうしたものか。
なお、同じ定数がプログラム中に何度も現れた時、 コンスタントプール上で同じエントリを割り当てれば コンスタントプールの領域を節約できますが、 現状ではやっていません。これも例によって単なる手抜きです。
グローバル変数
DVM_Executable構造体のglobal_variableメンバは、 読んで字のごとくグローバル変数を表現します。 バイトコードからグローバル変数を参照する場合、 このDVM_Variable型の配列のインデックスを使用します。 たとえば、整数型のグローバル変数の値をスタックにpushする命令は、 「push_static_int」です。 その後ろに2バイトのビッグエンディアンでこの配列のインデックスが続きます。
DVM_Variableの定義は以下の通りです。
typedef struct {
char *name;
DVM_TypeSpecifier *type;
} DVM_Variable;
見ての通り、ここで表現しているのはグローバル変数の名前と型です。
グローバル変数の型は、実行開始時の初期化と、 ガベージコレクションのために使います。
変数名は、現状では使用していません。 バイトコードからグローバル変数を参照するには、 前述のようにインデックスを使うからです。 将来的に複数のDVM_Executableをリンクするケースを考えても、 (関数はともかく)グローバル変数を他のソースファイルから 参照できるようにする必要はないんじゃないか、 と現状では思っていますが ――ただし、デバッガを実装する場合には必要になると思います ※2。
ところで、グローバル変数の型ですが、DVM_TypeSpecifierという 構造体で保持しています。
コンパイル時は、これは「TypeSpecifier」という構造体で保持しています。 こっちには「DVM_」が付いていません。
つまり、generate.cの中で、TypeSpecifier構造体から DVM_TypeSpecifier構造体へのコピーを行なっているわけです。
コンパイル時のTypeSpecifierは、 なにしろ解析木のすべての式のノードに割り当てられます。 たとえば「a + 1」という式がありaがint型の時、 intを表現するためのTypeSpecifierが(「a」と「1」と「a + 1」のために) (現状の実装では)3つ確保されています。 でもよく考えれば「a + 1」のノードのTypeSpecifier は左辺か右辺かどっちかのを直接参照してもよいはずで、 実際マイナス演算子ではそうしています。
このように、TypeSpecifier構造体は、 誰が所有者なのかわけがわからんようなこんがらがった参照で 保持されているので、解析木の他の部分同様、 コンパイル終了時に(MEM_Storageの機能を使用して)一括で破棄しています。 よって、DVM_Execututableでは、別途DVM_TypeSpecifierを用意しているわけです。
なお、TypeSpecifierでは派生型を連結リストで保持していますが、 DVM_TypeSpecifierでは配列です。これは、コンパイルが終われば、 「派生型をひとつひっぺがして…」といった操作を行なう必要が なくなるためです。
関数
関数を表現する構造体DVM_Functionの定義は以下のとおりです。
typedef struct {
DVM_TypeSpecifier *type;
char *name;
int parameter_count;
DVM_LocalVariable *parameter;
DVM_Boolean is_implemented;
int local_variable_count;
DVM_LocalVariable *local_variable;
int code_size;
DVM_Byte *code;
} DVM_Function;
typeは戻り値の型であり、nameは関数名です。 parameterとlocal_variableは、以下のような構造体で、 名前と型を保持しています。型は初期化のために使用していますが、 名前は現状では使用していません。
typedef struct {
char *name;
DVM_TypeSpecifier *type;
} DVM_LocalVariable;
さて、DVM_Functionにはis_implementedというフラグがあります。 これは、「この関数が、このDVM_Executableにおいて実装されているか」 を表現しています。
たとえばprint()関数は組み込みのネイティブ関数なので、 ユーザの書くDiksamプログラムにその定義が登場することはありません。 しかし、DVM_Functionには登場し、 関数を呼び出す際はそのインデックスを使用します。 よって、DVM_Function配列中にそのエントリが必要であるわけです。 そのような場合、is_implementedが偽になり、 code_sizeが0になります。
ところで、コンパイル中は関数定義はFunctionDefinition構造体に 保持されているわけですが、 この構造体にはis_implementedに相当するフラグがなく、 blockがNULLの時は関数定義がないとみなします。 ていうか関数定義がないにも関わらず構造体名が 「FunctionDefine」というのも変な話で、 なぜそうなっているかといえば、 プロトタイプ宣言的な関数宣言は後から追加したからです ――行きあたりばったりで作ってるとこうなります。
DVM_Function構造体のcodeメンバの指す先には、 当然その関数のバイトコードが格納されています。
トップレベルのバイトコード
DVM_Executableのメンバcodeの指す先には、 トップレベルのバイトコードを格納します。 バイトコードの生成自体については、これから説明します。
バイトコードの生成(generate.c)
バイトコードの生成において、 面倒なことはfix_tree.cでだいたい済ませているので、 generate.cですべきことは、 ほぼ「解析木を帰りがけ順で辿りつつコードを吐く」ことだけです
具体的にどのようなコードを吐いているかについて以下に説明します。
バイトコードの構造
ここまで曖昧なまま書き進めてきましたが、 ここでバイトコードの構造についていったん整理します。
バイトコードは、 命令(インストラクション:instruction) とオペランド(operand)の組み合わせでできています。
「オペランド」とは、C言語等の関数における引数のようなものと 考えることができます。たとえば以下の例では、
push_int 10
「push_intというインストラクションは、オペランドをひとつ取る。 このオペランドはコンスタントプールのインデックスである。」という 言い方をします。
Diksamのバイトコードはバイト単位です(ていうかでなければ バイトコードとは呼ばんか)。 インストラクションは、1バイトの整数で表現されます。 上の例で言えば、push_intに対応する値は3です。 これは列挙型DVM_Opcodeで表現されています(DVM_code.h)。
typedef enum {
DVM_PUSH_INT_1BYTE = 1,
DVM_PUSH_INT_2BYTE,
DVM_PUSH_INT, ←これがpush_int (つまり、3)
DVM_PUSH_DOUBLE_0,
DVM_PUSH_DOUBLE_1,
DVM_PUSH_DOUBLE,
DVM_PUSH_STRING,
(中略)
} DVM_Opcode;
オペランドの型は、以下の3種類があります。
- 1バイトの整数。インストラクション直後に直接格納されている。
- 2バイトの整数。インストラクション直後にビッグエンディアンで 格納されている。
- コンスタントプールのインデックス。現状では単なる2バイト整数。
どのような命令がどのような型のオペランドを取るかについては、 /share/opcode.cで定義されています。
OpcodeInfo dvm_opcode_info[] = {
{"dummy", ""}, /* DVM_Opcodeが1から始まるため */
{"push_int_1byte", "b"},
{"push_int_2byte", "s"},
{"push_int", "p"},
{"push_double_0", ""},
{"push_double_1", ""},
{"push_double", "p"},
{"push_string", "p"},
(以下略)
この配列は、デバッグ用のディスアセンブル機能(disassemble.c)のほか、 バイトコードを順次解析しなければいけない局面で使用しています。 ここで、"b"とあるのが1バイトの整数、"s"は2バイトの整数、 "p"がコンスタントプールのインデックスです(文字列で表現しているのは、 オペランドを複数取るインストラクションが必要になった時のためです)。
バイトコードの生成
generate.cでは、バイトコードを出力するために、 以下の関数を用意しています。
static void generate_code(OpcodeBuf *ob, DVM_Opcode code, ...)
この関数は、インストラクションの他、可変長引数でオペランドを取ります。
/* push_intを生成するコード。 * cp_idxはコンスタントプールのインデックス。 */ generate_code(ob, DVM_PUSH_INT, cp_idx);
識別子
識別子には、以下の種類があります。
- ローカル変数
- グローバル変数
- 関数
ローカル変数については、(それが右辺値である場合) 以下のコードを生成します。オペランドはすべて2バイト整数で、 スタック上のインデックス(baseからのオフセット)です。
| push_stack_int | int型のローカル変数の値をスタックに積む |
| push_stack_double | double型のローカル変数の値をスタックに積む |
| push_stack_string | string型のローカル変数の値をスタックに積む |
この3つのインストラクションは、型が違うだけでやっていることは同じです。 列挙型DVM_Opcodeでもこの手のインストラクションは int, double, stringの順に並ぶようにしてあるので、 バイトコード生成は以下のようにして行なうことができます。
generate_code(ob, DVM_PUSH_STACK_INT
+ get_opcode_type_offset(identifier->u.declaration
->type->basic_type),
identifier->u.declaration->variable_index);
get_opcode_type_offset()という関数が、 booleanまたはintなら0を、doubleなら1を、stringなら2を返すわけです。 booleanの時も0を返すのは、Diksam言語にはbooleanがあっても、 DVMにはboolean型はなく、intで代用しているためです。
グローバル変数では、push_(型名)_stackの代わりに、 push_(型名)_staticを使用します。オペランドは、 グローバル変数のインデックスです。
関数の場合、push_functionにより関数のインデックス (DVM_Function配列の添字)をプッシュします――が、 これは実行時には別のものに読み換えられるので、 詳細は次のページを参照してください。
2項演算子
2項演算子では以下のインストラクションを生成します。 表中で(型)となっている部分は、get_opcode_type_offset()で取得した オフセット分だけずれたインストラクションが入っていると思ってください。
| 演算子 | インストラクション | 意味 |
|---|---|---|
| * | mul_(型) | 乗算 |
| / | div_(型) | 除算 |
| % | mod_(型) | 剰余 |
| + | add_(型) | 加算 |
| - | sub_(型) | 減算 |
| = | eq_(型) | 等値比較 |
| != | eq_(型) | 非等値比較 |
| > | gt_(型) | より大きい |
| >= | ge_(型) | 以上 |
| < | lt_(型) | より小さい |
| <= | le_(型) | 以下 |
| && | logical_and | 論理AND |
| || | logical_or | 論理OR |
これらの演算子には、オペランドはありません。
単項演算子
単項演算子には、単項のマイナスと論理否定(!)がありますが、 キャストも(現状で明示的な演算子はありませんが)単項演算子の 一種と考えることができるでしょう。
| インストラクション | 意味 |
|---|---|
| minus_(型) | 符号の反転 |
| logical_not_(型) | 論理NOT |
| cast_int_to_double | intからdoubleへキャスト |
| cast_double_to_int | doubleからintへキャスト |
| cast_boolean_to_string | booleanからstringへキャスト |
| cast_int_to_string | intからstringへキャスト |
| cast_double_to_string | doubleからstringへキャスト |
代入
現時点でDiksamには配列もオブジェクトのメンバもないので、 代入は必ず「変数 = 式;」の形になります。
そこで、まず右辺を評価し、値がスタックに取得できたら、 pop_stack_xxxまたはpop_static_xxxで変数にpopします。
ところで、C同様、Diksamの代入も式であり値を持ちますから、 「a = b = c;」のような代入が可能です。ということは、 代入終了後、スタック上にひとつ値が残っていなければなりません。 右辺を評価した値を変数にpopするとスタック上の値はなくなってしまうので、 スタックのトップの値をもうひとつスタックに積む、 duplicateというインストラクションを用意しています ――が、実のところ「a = b = c;」 のような代入なんて(人にもよるでしょうが)そうそう書くものでもなく、 ほとんどのケースではわざわざduplicateでスタックの値を複製する必要は ないことでしょう。
そこで、代入式(およびインクリメント/デクリメント式)の 生成においては、「その式が式文のトップレベルの式であるか」を フラグで渡し、式文のトップレベルである場合は duplicateしないようにしています。
関数呼び出し
上に挙げた図を再掲しますが、 Diksamにおいては関数呼び出し時にスタックは下図のように伸びます。
まず、引数を前から順に評価してスタックに積みます(Diksamに 可変長引数引数はないので、Cのように後ろから積む必要はありません)。
そして、その次に「関数」を積みます。 既に書いたようにDiksamにおいては関数呼び出しの()は演算子であり、 関数名はひとつの式です。push_functionを使用して、 関数をスタックに積みます。
その後、「invoke」を実行することで、関数呼び出しが実行されます。 invokeは、push_functionが積んだ値をスタックからどけて、 復帰情報を積みローカル変数の領域を確保して関数の実行を開始します。 詳細は次のページで。
制御構造
こちらに書いたように、 if文のような制御構造は、バイトコードではジャンプ命令で表現します。
ところで、ジャンプするためには、ジャンプ先のアドレスがわからなければ なりません。ここで「アドレス」と言っているのは、 DVM_Executableにおいて関数ごと、あるいはトップレベルで保持している バイトコードの配列(DVM_Byte *code)の添字です。
たとえば以下のようなソースがあった時、
int a;
if (a == 0) {
a = 1;
} else {
a = 5;
}
コンパイルすると以下のようになります。
0 push_static_int 0 # 変数aの値をスタックに積む 3 push_int_1byte 0 # 0をスタックに積む 5 eq_int # 比較 6 jump_if_false 17 # 等しくなければ17にジャンプ 9 push_int_1byte 1 # 代入のため1をスタックに積む 11 pop_static_int 0 # 1を変数aにポップ 14 jump 22 # 22(このコードの末尾)に飛ぶ 17 push_int_1byte 5 # 代入のため5をスタックに積む 19 pop_static_int 0 # 5を変数aにポップ
ここで、左端の数字が「アドレス」になります。 機械語での言い方に合わせ、ある特定のアドレスについては 「○○番地」という言い方で表すことにしましょう。
上の例では、aと0を比較し、6番地にて、 等しくなければ17番地にジャンプしています。 問題は、6番地のjump_if_false命令を生成している時点では、 飛び先の「17番地」はまだ確定していないということです。
そこで、Diksamのコンパイラでは以下の方法を採用しました。
- ジャンプ命令等でアドレスが必要になった時は、
get_label()関数により「ラベル」を取得する。
ここで取得される「ラベル」は、ラベルテーブルの添字である。 - コード生成の最初のフェーズでは、飛び先のアドレスの代わりに、 ラベルを暫定的に出力しておく。
- ラベルを振った個所のアドレスが確定した時点で、 set_label()関数により、ラベルテーブルにアドレスを格納する。
- コード生成が一通り終了したら、ラベルテーブルを使用して、 暫定的にラベルを出力していた個所をすべてアドレスに置き換える。
- ※1 Cの場合、printf等の型は式の中では「関数へのポインタ」 に変換されますが、 Diksamではそういう無駄にややこしくなることはしません。
- ※2 デバッガを考えたら、他にも情報は山のように必要ですが。 ていうか現状では、実行時にはソースの行番号すら持ってないし。
前のページ | 次のページ | ひとつ上のページに戻る | トップページに戻る