またえらく長いこと放置しておりましてすみません。 今回実施した修正は以下の通りです。
私もたまにPerlを使うことがありますが、 私がPerlを使ってすることといえばほとんどテキストファイルの処理です。 今回の修正で、crowbar もそういう用途にそこそこ使えるようになったと思うので、 それなりに実用性が出てきたのではないでしょうか ――ってそれはほとんど鬼車のおかげなんですが。
「鬼車」というのは、小迫さんが開発された正規表現ライブラリです。
公式ページ:
http://www.geocities.jp/kosako3/oniguruma/
|
2018/03/12追記:掲示板で指摘いただきましたが、上記のページはなくなっており、
現在はGitHubで公開されているようです。 |
私はといえば、正規表現はまるっきり素人なのですが(もちろん普通に grepとかは使っていますが)、 鬼車を組み込むことで、簡単にcrowbarに正規表現を実装できました。
ここまでできれば、そろそろcrowbarも、その命名の由来の通り、 「Perlのようなもの」と言っても怒られない程度にはなったかな、 と思うのですが――ただ、今のPerlは、 (ライブラリ込みで)ずいぶん色々な用途に使われているので、 まだちょっと僭越ですかねえ。
GLOBALをかましたソースは こちらから参照可能です。
ダウンロードは、UNIX版がこちら、 Windows版がこちら。
2006/1/7追記:
以下の不具合があったので、取り急ぎver.0.4.01を上げます。
毎度初歩的なポカが多くすみません。
crowbar ver.0.3.02では、以下のような例外処理機能を実装していました。
今回、これらは以下のように修正されました。
最後の項目についてもう少し詳しく説明します。
Javaなどでは例外はクラスで提供されており、 catch節でクラスを指定することで、 その例外クラス(サブクラスを含む)の例外だけを選択的にcatch することができます。 この方法は、これはこれで確かに便利ではありますが、 「例外Aと例外Bの場合はこういう処理をしたい」という時、 同じようなcatch節を複数書かなければならないことがあります。 これは、「同じことを複数の個所に書いてはいけない」という コーディング上の大原則に反します。
もちろん、例外Aと例外Bに共通のスーパークラスがいれば、 そのスーパークラスでcatchすることはできますが、 例外の階層は例外クラスを提供する側の都合で決められますから、 例外を使う側の都合とは往々にしてずれるものです。 また、「例外Aと例外Bの場合はこういう処理をしたい」というように、 単にOR条件の記述をしたいだけなら、 catch節でクラスをカンマで区切って指定できるようにするなどの手も 考えられますが、「例外Aと例外Bの場合はこういう処理をしたい、 ただし、例外A, B, Cのすべてにおいて、この処理をしたい」 というようなケースもありますから、結局、例外の種類は、 アプリケーション側で通常のif文で振り分けてもらうのがよいのではと考えました。 ただ、この方法では、想定外の例外が発生に備え、 if文のelse節で例外を再度throwする必要がありますが、 これをいかにも書き忘れそうだ、という欠点はありますね。
というわけで、crowbarで例外を使う場合は、以下のような記述になります。
try {
zero = 0;
a = 3 / zero;
} catch (e) {
/* child_ofメソッドで例外の種類を判定 */
if (e.child_of(ArithmeticException)) {
print("? /0 Error.\n");
} else {
throw e;
}
}
この例では、算術例外(現状ではゼロ除算しかありません)の場合だけ 「? /0 Error.」というメッセージ(このメッセージの意味が わからない人はそのへんの年寄りに聞いてみよう)を表示し、 それ以外の例外はそのまま投げ直しています。
例外の種類は、 例外オブジェクトのchild_ofメソッドにより判定しています。 child_ofメソッドには「ArithmeticException」を渡していますが、 これは、「例外クラス」を表現するオブジェクトへの参照を格納した グローバル変数です。 なので、関数内で同じようなことを書こうと思ったら、 global文で宣言しておく必要があります ――このへんの仕様はちょっと使いにくいかも。
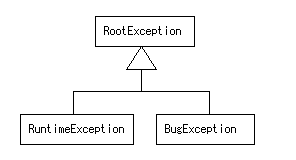
crowbarは、処理系が投げるものだけで、 現在50種類以上の例外がありますが(今までcrb_runtime_error() で出していたメッセージごとにすべて別の例外を割り当てたため。 こんなに分ける必要はなかったかも)、 それらは下図のような階層構造を持っています。
すべての例外は、RootExceptionの子ですが、 そのうちバグがなければ発生し得ない(と私が考える)ものは BugExceptionのカテゴリに入れています。 バグがなくても、 利用者側ユーザの不手際などで発生し得るものはRuntimeExceptionです。 BugExceptionは、 crowbarプログラムとしてはたぶんどうしようもないので、 たいていのプログラムでは、catchすべきではありません。
「例外クラス」は、以下のようにして生成されます。
1: function create_exception_class(parent) {
2: this = new_object();
3: this.parent = parent;
4:
5: # 例外のインスタンスを生成するメソッド
6: this.create = closure(message) {
7: e = new_exception(message);
8: e.stack_trace.remove(0);
9: e.child_of = this.child_of;
10: return e;
11: };
12:
13: # child_ofメソッド
14: this.child_of = closure(o) {
15: for (p = this; p != null; p = p.parent) {
16: if (p == o) {
17: return true;
18: }
19: }
20: return false;
21: };
22: return this;
23: }
24:
25: # 例外クラスを生成し、グローバル変数に設定する。
26: RootException = create_exception_class(null);
27: BugException = create_exception_class(RootException);
28: RuntimeException = create_exception_class(RootException);
29: ArithmeticException = create_exception_class(RuntimeException);
(後略)
引数として「親クラス」を渡してcreate_exception_class()を呼び出すと、 「例外クラス」のオブジェクトが生成されます。 そして、その「例外クラスのオブジェクト」のcreate() メソッドを呼び出すことで、その例外クラスに属する例外が生成されます。
さて、上記のcreate_exception_class()関数を使うことで、 「例外クラス」らしきものを作ることができるわけですが、 0.3までのcrowbarには、 crowbarで記述されたライブラリを読み込む機能がありません。 では、処理系として、 create_exception_class()関数をどのように提供すればよいでしょうか。
いくつかの方法が考えられます。
crowbarで書けば簡潔に書けることをCでゴリゴリ書くのは、 (何より私が)面倒なので嫌です。 といって、実行時に別ファイルを読み込むようにすると、 crowbarが実行形式単独で動作しなくなります。
実行形式単独で動作しないと何が困るのか、 インストールが大変だというならちゃんとインストーラを作ればいいじゃないか、 という声も聞こえてきそうですが、 crowbarのようなスクリプト言語は、 「ログファイルを見やすい形に整形したい」 といった用途で使われることが多いものです (Perlは実際そのような用途向けに作成された言語ですし)。 crowbarも、ちょうど今回正規表現ライブラリを積んだことで、 そういう用途に使えるものになりつつあるでしょう。 そして、プログラマなんて稼業をやっていると、 たとえば客先で作業していてちょっとログを整形したい、 といったことも多いのですが、 そういう場合、 客先のマシンに好き勝手なソフトをインストールできるとは限りません。 しかし、実行形式単独で動くようにしておけば、 USBメモリ※1 なりCD-Rなりにcrowbarの実行形式を入れておき、 ちょっとカレントディレクトリに放りこんで、 作業が終わったら消して帰るという方法も使えます(お客さんが許せば)。 それを考えると、crowbarにとって、 「実行形式単独で動く」というのは大きなメリットであり、 これを崩したくはありません (だからいまだにエラーメッセージもソース埋め込みにしているわけです)。
Cで書くのも嫌だがcrowbarで書かれた外部ファイルを読むのも嫌だ、 ということで、今回とった方法は、 「crowbarで書かれたソースを実行形式中に埋め込む」というものです。 言葉でぐだぐだ説明するよりブツを見た方が早いでしょう。 これです→(builtin.cのソース)。
このように、 crowbarのソースを文字列リテラルの形でCプログラム中に埋め込めば、 「標準ライブラリ」的なものをcrowbarで書きつつ、 crowbarを実行形式単体で動作させることができるわけです。 この方法でcrowbarに埋め込まれたcrowbarスクリプトのことを、 「ビルトインスクリプト」と呼ぶことにしようと思います。
文字列リテラルとして埋め込まれたcrowbarソースは、 ユーザの書いたプログラムをコンパイルする前にコンパイルされます。 そのために今回、CRB_compile_string()という公開関数を追加しました。 この関数は文字列の配列を引数に取り、 それをcrowbarソースとしてコンパイルします。 配列の最後の要素はNULLでなければなりません。
void CRB_compile_string(CRB_Interpreter *interpreter, char **lines);
crowbarの場合、コンパイルはyaccとlexの共同作業で行ないます。 そして、ソースを最初に読み込むのはlex(が生成したプログラム)です。 lex(が生成したプログラム)は、デフォルトの状態では、 グローバル変数yyinに指定されたファイルポインタから ソースを読み込もうとします。 今回はこれでは困るので、lexの入力元を切り替える必要があるわけですが、 それにはYY_INPUTマクロを使用します(このマクロはO'Reillyの Lex&Yacc本に記述がないので、あまり標準的ではないのかもしれませんが、 flexでは使えています)。
/* crowbar.lの冒頭より */ #undef YY_INPUT #define YY_INPUT(buf, result, max_size) (result = my_yyinput(buf, max_size))
こんな感じで自分の入力ルーチンを定義します。 入力ルーチンは、バッファとバッファサイズを受け取り(fgets()流)、 バッファに文字列を詰め込んで、詰め込んだ文字数を返します。 バッファは'\0'で終端させる必要はありません。
my_yyinput()は、現在のインタプリタの「入力モード」を参照し、 CRB_FILE_INPUT_MODEであればファイルから、 CRB_STRING_INPUT_MODEであれば文字列からの入力を行ないます。
ところで、 このようにしてcrowbarのソースをCプログラム中に埋め込むことは できるわけですが、crowbarが埋め込まれたCソース(今回はbuiltin.c)は どのようにして作成すればよいでしょうか。 直接手で書くのは面倒ですし、crowbarプログラムのテストもできません。 こういうものは当然、crowbarソースから自動生成したいものです。
というわけで今回その自動生成プログラムをcrowbarで書きました (ソースはこちら→conv.crb)。 いやそのcrowbarのmakeを行なおうという環境なら当然 Cコンパイラはあるわけですから、 別にCで書いても構わなかったのでしょうが、 この手のスクリプト言語を作っていながら、こういう所で使わないのでは、 言語自体の存在意義を疑われそうでもありますし。
とはいうものの、この変換はcrowbarのmakeの途中で必要になります。 当たり前ですが、crowbarをmakeしている最中にcrowbarは使えませんので、 ビルトインスクリプトを組み込まない状態の 「minicrowbar」という実行形式を先に生成し、 conv.crbはminicrowbarで実行しています。 いやだからこんな凝ったことをやるくらいならこの程度の変換プログラム Cで書いた方が早いじゃないか、とも思うわけですが、 どっちかというとこういうのを「やってみたかった」わけでして(^^;
なお、conv.crbが正規表現を使っていないのは、 これを書いた時点でまだ実装されていなかったためで、 深い意味はありません。
conv.crbを書くにあたりいくつか機能が必要になったので、 追加しました(泥縄)。
crowbar hoge.crb a.txt b.txt
"a.txt"がARGS[0]に、
"b.txt"がARGS[1]に、それぞれ格納されます。
えー、このあたりのことについては、 用語の使い方など色々難しいようですし、 私自身そんなに詳しいわけではないので、 以下の説明に間違い等ありましたらツッコミよろしくお願いいたします。 >識者の方
と、予防線を張ったところで、まずは用語の説明から入ります。
ver.0.3までのcrowbarは、文字列をchar*で保持していました。 ただし、日本語を扱うと、EUCでもSJISでも、漢字はたいてい2バイト消費します。 このような保持形式の文字列を、マルチバイト文字列と呼びます。
たとえば、crowbarの文字列には length()とかsubstr()といったメソッドがありますが、 このようなメソッドの実装においてはマルチバイト文字列は不便です。 crowbar ver.0.3では単純にバイト単位で処理していたため、 "abc漢字".length()は7になってしまいますし、 "abc漢字".substr(3, 1)と書くと「漢」の前半部だけを切り取ってしまいます。 これを表示すると文字化けなどの現象が起きることになるでしょう。
そこで、1文字あたり、 漢字を充分に含むことができる大きめの型を割り当てて、 すべての文字をひとつの整数値で扱えるようにしようという発想が出てきます。 これがワイド文字(列)です。 ワイド文字では、ひとつの文字は、wchar_t型で表現されます。 gccではsizeof(wchar_t)は4なので(VC++では2らしい)、 「a」のようなASCII文字でも4バイト食います。 よって、メモリ効率は悪いのですが、str[i]のように書けば、 ASCIIと漢字がごっちゃになったような文字列でも、 常にi文字目が参照できる、という利点があるわけです。
マルチバイト文字にせよワイド文字にせよ、 特定の文字コード系に限定されたものではありませんが、 ワイド文字の文字コードとしては、 現在のところUNICODEが使われることが多いようです。
crowbar ver.0.4からは、文字列の内部表現形式をワイド文字列としました。
なお、ここで「文字列」と言っているのは、crowbarの文字列型のことであり、 変数名などの識別子は含まれません (よって変数名に日本語を使うことはできません)。
また、マルチバイト文字列とワイド文字列の相互変換のタイミングは、 以下のようになっています。
これらの相互変換には、mbrtowc(), wcrtomb()といった関数を使用しています。 これらの関数は ISO C95から標準化された関数群です。 デフォルトでは、マルチバイト文字列は、WindowsではShift-JIS, LinuxではEUCであり、ワイド文字列の方はどちらもUNICODEになるようです。
ところで、「デフォルトでは…」と書いていますが、 こういった言語設定(ロケール)をデフォルトに設定するには 「setlocale(LC_CTYPE, "")」 という設定が必要です。 crowbarでは、この設定は、main()関数で行なっています。
これらの関数を実際の使用法は、wchar.cの CRB_mbstowcs(), CRB_wcstombs()を それぞれ参照してください。
――と、こう書くと、 何の苦もなくSJIS/EUCとUNICODEの相互変換ができそうですが、 実際には何かと苦労しました。
まず、Windowsの場合、mbrtowc()を使用するにはコンパイル時に-lmsvcp60 の指定が必要です(MinGWの場合)。 これはまあ指定すればよいとして、いろいろ試したのですが mbsrtowcs()は結局動きませんでした。 また、環境がないため試していませんが、おそらくこれらの関数は Windows9x系では動作しないと思われます。
今のところワイド文字列はcrowbarの中でしか使っていない (外部とのやりとりは、すべてマルチバイト文字列で行なっている) ことを考えれば、ワイド文字/マルチバイト文字の変換に関しては、 独自でやった方が堅いかもしれませんねえ…
細かいことですが、ver.0.3までのcrowbarでは、 Shift-JISの環境において、 文字列リテラル中に「表」などの文字を含めるとエラーになる、 という問題がありました。 これは、Shift-JISでは「表」の2バイト目が0x5Cであり、 ASCIIコードの「\」と同じであること、 およびcrowbarの文字列リテラル中では「\」 は特別な意味をもつことが原因です。
そこで、Shift-JISファイルでも読み込めるよう、 crowbar.lに以下の修正を加えました。
(前略)[\x81-\x9f\xe0-\xef][\x40-\x7e\x80-\xfc] { crb_add_string_literal(yytext[0]); crb_add_string_literal(yytext[1]); } (後略)
Shift-JISの漢字は、1バイト目が0x81~0x9eまたは0xe0~0xef、 2バイト目が0x40-0x7eまたは0x80~0xfcまでと定められています( このページがわかりやすいでしょう) そこで、単純にその並びを文字列リテラルの一部として解釈するように したわけです。
こういう修正を加えて、じゃあEUCの時に問題が起きないのか、 という懸念もあるかもしれませんが、 Shift-JISの1バイト目である0x81~0x9eまたは0xe0~0xefは、 EUCの2バイト目とはかぶっていないので大丈夫でしょう。たぶん (もしこれがかぶっていると、文字列リテラルの終端や「\」を見逃す可能性がある)。
ということで、crowbarソース中の「0x5C問題」はどうやら解決したのですが、 Cソース中の0x5C問題はどうしたもんでしょうねえ。 crowbarでは日本語エラーメッセージをソース中に埋め込んでおり、 gccにはここで説明したのと同じ問題があるため、 現在はエラーメッセージ中に該当する文字を含まないようにすることで しのいでいます。 今までは「ソ」がだめなので「メソッド」を「method」と書く、 ということをしていましたが、今回正規表現を導入したところ、 「表」がだめなのでエラーメッセージ中では 「regular expression」と英語表記しています。 他の部分は日本語なので、どうにも変です。
gccだけに対応すればよいのなら、「正規表\現」と書くことで回避できますが (こう書くことで\がふたつ並ぶことになり、ひとつの\として解釈される)、 このような問題のないコンパイラを使う人もいるでしょうし。
正規表現とは何か…というようなことは、 このページを読んでいる人には説明不要と思われますので省略します (既にlexで正規表現を使っているわけですし)。
プログラミング言語で正規表現を扱う場合、 言語そのものを、どの程度まで正規表現に特化させるか、 ということが問題になってきます。
Perlあたりは、言語仕様そのものが、かなり正規表現に特化しています。 s///とかm///とか、s///gとか、=~とか、なんのこっちゃと思います。 AWKレベルでテキスト処理に特化した言語ならこれでよいのかもしれませんが、 crowbarをこうしようとは思いません。
逆にJavaやPHPでは、言語としては特に正規表現をサポートしません。 正規表現はライブラリで提供されます。 それでいいじゃん、と思う人もいるかもしれませんが、 その場合、正規表現は単なる文字列で表現されることになり、 正規表現で特別な意味を持つ文字(「\」など)は、 文字列リテラル中でもやはり特別な意味を持つため、 たとえばJavaで\にマッチする正規表現を書くためには、 「\\\\」と書く必要があります。これはかなりまぬけです。
この問題を解決するためかどうかは知りませんが、 Pythonでは、raw stringという概念を導入しています。 Pythonでは、
r"文字列"
のように文字列リテラルの前にrを付けて書くと、 この文字列の中では\が特別な意味を持たなくなるのです。 これなら、「\」にマッチする正規表現は、「\\」で済みます。
しかし、「\」が特別な意味を持たないとするなら、 「"」をリテラル中に埋め込まなければならない時はどうするんだろう、 という疑問が出てくることでしょう。 Pythonの リファレンスマニュアルによれば、
引用符はバックスラッシュでエスケープすることができますが、 バックスラッシュ自体も残ってしまいます; 例えば、r"\"" は不正でない 文字列リテラルで、 バックスラッシュと二重引用符からなる文字列を表します; r"\" は正しくない文字列リテラルです (raw 文字列を奇数個連なった バックスラッシュで終わらせることはできません)。 厳密にいえば、 (バックスラッシュが直後のクオート文字をエスケープしてしまうため) raw 文字列を単一のバックスラッシュで終わらせることはできない ということになります。
…なんかあんまり真似したくない仕様です。
また、正規表現は、効率よく解釈するためには事前にコンパイルする必要があります。 しかし、これを利用者側(crowbarプログラマ)が毎回やるのは面倒です。 たいていのプログラムでは、 正規表現を実行時に組み立てるということはないでしょうから、 ソースをコンパイルする時に、 同時に正規表現のコンパイルも済ませて欲しいものです。 そうなると、やはり言語として「正規表現のリテラル」を表現する書式が 必要になります。
Rubyの場合、 %!文字列!と書くことで、 Pythonのraw stringと同様のことが実現できるようです。 この「!」は、任意の文字を使用できます。 また、%r!正規表現!で正規表現のリテラルを表現できます。
ただ、crowbarでは%は剰余の演算子として既に使用されており、 「hoge %r + 3 」と書いたとき、%以降が「+ 3」という正規表現と 解釈されても困ります。
そこでcrowbarでは、 「%%r"正規表現"」という書式を採用しました。 正規表現中に"を使いたいこともあるでしょうから、 %%rの後ろには任意の文字を指定できます。 つまり、「%%r"hoge"」と書いても、「%%r!hoge!」と書いても、 同じ意味になります。
――でも、いざ書いてみると、これはこれで美しくないような気も…
ということで正規表現がリテラルで表現できるようになったので、 以下の公開関数を用意しました。
これらの関数の仕様は、おおむねPHPのそれに似ていると思います。
なお、鬼車には「名前付き捕獲式」という機能があり、 これを使うと、後方参照(括弧で囲んだ部分を、 後方で\1, \2のような形式で参照する機能)について、 \1, \2のような番号でなく、名前で参照することができます。 便利な機能だとは思いますが、 現状のcrowbarのreg_replace()では対応していません。 また、正規表現パターン文法定義は、デフォルトのRubyではなく、 Perlにしてあります(私自身はどう違うのかすらわかっていませんが、 Perlの方がユーザが多いかな、という程度の理由によります)。
ということでVer.0.4から、crowbarのコンパイルには鬼車が必須となりました。 もちろんスタティックリンクすれば「実行形式単独で実行できる」という crowbarの利点は損われません。
鬼車のインストール方法は、公式ページを参照すれば、 UNIX、cygwin環境、およびWindows上のVC++環境についてはわかると思います。 ただしこの企画では以前からMinGWを使っているわけで、 configureを実行できないMinGWユーザ向けに、 うちのcygwin環境で作成したMakefileを置いておきます (ここ)。 このMakefileは鬼車のver.3.9.1に対応しており、 これをoniguruma直下に置いてmakeを実行するだけで、 libonig.aが生成されるはずです。
コンパイルできたら、UNIXの場合はmake installすればよいでしょう。 ヘッダファイルがデフォルトで/usr/local/includeにインストールされるため、 -Iを追加する必要があります。
Windowsの場合、(cygwinが入っていなければ)installコマンドがなくて make installは動かないので、 libonig.aと関連ヘッダファイルをしかるべき場所に置いてやることになります。 私の場合、MinGWを使っていますから、 libonig.aをC:\MinGW\libに、 onigposix.h, oniggnu.h, oniguruma.hをC:\MinGW\includeに それぞれ放り込んでしまいました。
また、UNIX, Windowsともに、鬼車をリンクするために-lonigの指定が必要です。
鬼車のインストールができたところで、 実際に鬼車を使ってネイティブ関数を作っていきます。
――が、正直、私には、鬼車の付属ドキュメントを読んでも いま5つくらい使い方がわかりませんでした。 まあ私に正規表現一般の知識がないせいなんでしょうけど。
今回は、鬼車のサンプルソースsimple.cを参考に crowbarのregexp.cを書きました。以下、その説明です。
正規表現の文字列から、 コンパイル済みの正規表現オブジェクトを作成するには、 onig_new関数を使用します(crb_create_regexp_in_compile()より)。
r = onig_new(®, pattern,
pattern
+ onigenc_str_bytelen_null(ONIG_ENCODING_UTF16_BE, pattern),
ONIG_OPTION_DEFAULT, ONIG_ENCODING_UTF16_BE,
ONIG_SYNTAX_PERL, &einfo);
第1引数のregに、生成された正規表現オブジェクトへのポインタが返されます。 第2, 第3引数で、正規表現の文字列の範囲を渡しています。 patternが開始位置なのはよいとして、 終了位置でonigenc_str_bytelen_null()を呼び出しているのは、 ここで渡している正規表現文字列は、char*でもwchar_t*でもなく、 UTF16_BEにエンコードされたものであるため、 終了位置を単純にstrlen()などでは判定できないからです (このあたりのソースは鬼車付属ソースのencode.cを参考にしました)。
UTF16_BEとはなにものか、という点については後述します。
こうして作成された正規表現オブジェクトは、 CRB_Regexp構造体に保持されます。
struct CRB_Regexp_tag {
CRB_Boolean is_literal;
regex_t *regexp; /* 鬼車の正規表現オブジェクト */
struct CRB_Regexp_tag *next;
};
CRB_Regexp構造体自体は、ネイティブポインタ型から参照されます。 CRB_Valueに正規表現型を追加するのではなく、 ネイティブポインタ型を使っているあたり、 crowbarと正規表現の「距離感」がそこはかとなく出ている気がしますが w それはさておき、現状ではできませんが、正規表現を実行時にコンパイルするような 関数ができたとしたら、正規表現の解放は、 ネイティブポインタ型のファイナライザで行なわれることになります。
ネイティブポインタ型から鬼車のregex_tを指すのではなく、 わざわざ間にCRB_Regexpをはさんでいるのは、 コンパイル時に生成された正規表現オブジェクトは インタプリタの破棄時に破棄しなければならないため 連結リストで保持していること(これがnextメンバ)、 およびコンパイル時に生成された正規表現オブジェクトは 参照がなくなったからといって解放できないので、 それが正規表現リテラルであるかどうかを保持するフラグ(is_literal) が必要なためです。
正規表現ができたら、それを文字列に適用するわけですが、 パターンマッチを行なう関数として、鬼車には onig_search()とonig_match()のふたつの関数があります。 crowbarでは、simple.cに使用例のある、 onig_search()だけを使用しています(Rubyもそうらしい)。
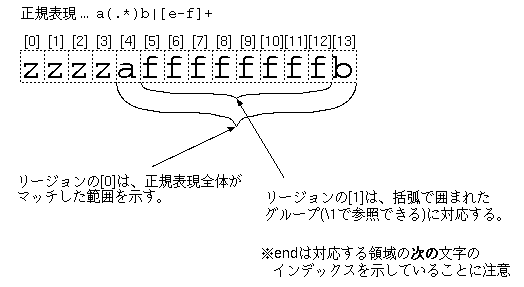
simple.cの使用例を見ると以下のようになっていて(コメントは前橋が追加)、
/* 正規表現の文字列 */
16: static UChar* pattern = (UChar* )"a(.*)b|[e-f]+";
/* マッチ対象の文字列 */
17: static UChar* str = (UChar* )"zzzzaffffffffb";
(中略)
33: r = onig_search(reg, str, end, start, range, region, ONIG_OPTION_NONE);
/* onig_search()により得られた「リージョン」の
内容を出力*/
34: if (r >= 0) {
35: int i;
36:
37: fprintf(stderr, "match at %d\n", r);
38: for (i = 0; i < region->num_regs; i++) {
39: fprintf(stderr, "%d: (%d-%d)\n", i, region->beg[i], region->end[i]);
40: }
41: }
onig_search()実行後、 得られたリージョン(型はOnigRegion)の内容を表示しています。 そして、実際にこれを実行すると、実行結果は以下のようになります。
% simple match at 4 0: (4-14) 1: (5-13)
これを見ると、 region->beg[n], region->end[n] がそれぞれ下図のような領域を指していることがわかります。
鬼車にはreplaceやsplitといった関数はありません(正規表現ライブラリとしては 当然でしょうが)。そこで、そういった機能については自分で作る必要があります。 onig_search()でパターンマッチができてしまえば、 reg_split()あたりは簡単に実装できますが、 reg_replace()は、後方参照が使えなければならないため、多少面倒です。
crowbarでは、replacementの方の「\1」といった表現は、 crowbar側で自力で解釈し、 そこにregionで返された範囲の文字列を埋め込んでいます。 このやり方が正しいのかどうか、いまいちわかっていませんが…
ところで、それではさっそくregexp.cを読んでみよう、 と思った人向けに補足説明ですが、 match, replace, split共に、「match_crb_if()」のように、 「crb_if」と付けられた関数があります。 これは、処理が複雑なので関数の階層を分けているわけですが、 「この階層ではCRB_xxxという型を受け渡している」という意味で、 「CRB階層のインタフェース」の意味でcrb_ifと付けています。 これより下の階層だと、鬼車の型を使っているわけです。
もうちょっとよい名前はなかったものかと自分でも思いますが…
さて、上の方で 「UTF16_BEとはなにものか、という点については後述します。」 と書きましたので、ここではそれを説明します。
ver.0.4では、crowbarの文字列の内部表現はwchar_tの配列になりました。 では鬼車はwchar_t*を引数として受け取ってくれるかというと、 これが受け取ってくれません。 鬼車では、文字列は基本的にunsigned char *です。 じゃあキャストして渡せばいいのか、と思うかもしれませんが、 そもそもwchar_tの配列といっても、 1バイト単位のデータ形式までは規定されていないのです。 だいたいWindows(VC++)とgccではwchar_tのサイズ自体違うわけですし、 CPUによってはバイトオーダも違います。
そこで、UNICODE※2 を「バイトの並び」に変換する方式として、UTF-8, UTF-16といった方式が定められています。 UTF-16はバイトオーダによりUTF-16BE(ビッグエンディアン)と UTF-16LE(リトルエンディアン)の2種類があります。 このあたりのことは、以下のページが参考になるでしょう。
crowbarでは、鬼車に渡す直前に、正規表現文字列や対象とする文字列を、 すべてUTF-16BEに変換しています。 その変換関数が、以下のencode_utf16_be()です。
1: static OnigUChar *
2: encode_utf16_be(CRB_Char *src)
3: {
4: OnigUChar *dest = NULL;
5: int dest_size;
6: int src_idx;
7: int dest_idx;
8:
9: dest_size = CRB_wcslen(src) * 2 + 2;
10: dest = MEM_malloc(dest_size);
11:
12: for (src_idx = dest_idx = 0; ; src_idx++) {
13: if (dest_idx + 1 >= dest_size) {
14: MEM_free(dest);
15: return NULL;
16: }
17: dest[dest_idx] = (src[src_idx] >> 8) & 0xff;
18: dest[dest_idx+1] = src[src_idx] & 0xff;
19: dest_idx += 2;
20: if (src[src_idx] == L'\0')
21: break;
22: }
23:
24: return dest;
25: }
見ての通り、単純にwchar_tの上位 8ビットと下位8ビットを順に詰めているだけなので、 UCS-4にもサロゲートペアにも対応していません。 でもそもそも入力がShift-JISやEUCしか対象にしていないのなら、 これで充分かとも思いますが。
たとえばPythonでは、matchとかsplitとかsub(置換(substitute)。replaceと同じ) といった関数は、RegexpObjectのメソッドとして実装されています。 それに対し、crowbarでは、 reg_match()とかreg_split()とかreg_replace()とかは単なる関数です。 おかげでreg_というプレフィクスを付ける必要が出てきていますし、 なんというか、「crowbarはオブジェクト指向的でない」 という声がどこかから聞こえてきそうです。
crowbarだってクラスらしきものは作れるのだから、 Pythonのような実装にすることは可能です。
しかし、たとえばJavaでは、replace()やsplit()はStringのメソッドです。 そして、match()(matches())はMatcherクラスのメソッドです。 JavaとPython、どちらかの設計が「間違っている」とは私には言えません。
よく、オブジェクト指向のメリットとして、 「従来は分厚いリファレンスマニュアルから 一所懸命関数を探さなければならなかったが、 オブジェクト指向では、クラスごとにメソッドが整理されたおかげで 探すのが楽になった」 という説明がなされることがありますが、 JavaとPythonでメソッドの存在する場所が違うなら、 やっぱり探すのに苦労するのではないでしょうか。 「ポケットひとつの原則」を破っているのでなおのこと。
とはいえ、 フラットな名前空間に大量の関数が転がっているのもやっぱり問題です。 これを解決するのは(Javaで言えばpackageに相当する)名前空間であり、 クラスではなかろう、というのが私の考えです ※3
――と言いつつ、現状のcrowbarには名前空間を分割する機能がないので、 今回は、プレフィクスreg_で逃げてグローバルな関数としました。 これまたcrowbarをどこまで正規表現に特化させるかという問題になってくる わけですが、「プレフィクス付きグローバル関数」というのは、 正規表現からそれなりに距離を保ちつつ、 「Perlのようなもの」であることも維持する、 という、なかなか微妙な、しかしcrowbarらしい位置付けかなあ、 と思います。
前バージョンまでに存在した以下の不具合を修正しました。
まずは、鬼車の開発者である小迫さんに感謝いたします。 まだ私の方が使いこなせていませんが、 あっさりとcrowbarに正規表現を組み込むことができました。
mbrtowc(), wcrtomb()関数を使用することについては、 掲示板でのkitさんの投稿を元にしています。
正規表現リテラルの表記法や、ビルトインスクリプトについては、 2ちゃんねるのスレッド「 コンパイラ・スクリプトエンジン相談室」が参考になりました。 ただこのスレッド、勉強になるときもありますが、いかんせんS/N比が…
testディレクトリの中にワイド文字/マルチバイト文字変換テスト用の テキストファイルがふたつ入っていますが(code.txt, code2.txt)、 これらはそれぞれ以下のページを元にしています。
http://ash.jp/code/codetbl2.htm
http://home.a03.itscom.net/tsuzu/programing/tips07.htm
ver.0.3で挙げた「することリスト」は、 「モジュール」を除いて達成しましたから、 新しいリストを作るとします。
それではまた気長にお待ちくださいませ。