多忙につき、ずいぶん長いこと放置してしまいましたが、 一応コツコツ作業は進めておりました。 またマイナーバージョンアップですが、公開します。
ver.0.3.02での修正点は以下の通りです。
見ての通り、結構あちこちいじっています。
GLOBALをかましたソースは こちらから参照可能です。
ダウンロードは、UNIX版がこちら、 Windows版がこちら。
※掲示板で不具合の報告をいただきましたので、9/27夜、ファイルを入れ替えました。 毎度ポカが多くすみません。
従来のcrowbarでは、 関数内で新たに代入された変数名がグローバル変数と衝突していると、 グローバル変数と解釈されました。この仕様では、 現在宣言(ていうか代入)されているグローバル変数名を全て把握していないと、 関数を書けないことになります。 関数は局所性を高めるために書くわけですから、この仕様は致命的です。
さて、この問題を回避する方法としては、いくつかの方法が考えられます。
一般に、プログラミングにおいてグローバル変数はやたらと使うものではなく、 可能な限りローカル変数にして局所性を保つのが良いとされます。 その意味でPerl式はよろしくないと思うのでボツ(まあ、 使い捨てのスクリプトではこれで良いかもしれませんが)。 また、Ruby式は、合理的だとは思うのですが、 この方針を推し進めるとプログラムが記号ばかりになって 私的には美しくないと感じます。 というわけで、crowbarでは、 PHP風にglobal文を導入することにしました。
global文は、以下のような形式で使用します。
global 変数名, 変数名, …;
たとえば関数内で「global a;」のように宣言すると、 以後、その関数内ではグローバル変数のaが参照可能になります (もしグローバル変数aが存在しなければ実行時エラーです)。
たとえば以下のプログラムを実行すると、
1: a = 10; ←グローバル変数aの宣言
2:
3: function func() {
4: global a;
5: a = 20; ←ここではグローバル変数のaが見える
6: }
7:
8: function func2() {
9: a = 30; ←ここではローカル変数のaが見える
10: print("a.." + a + "\n");
11: }
12:
13: func();
14: func2();
15: print("a.." + a + "\n");
実行結果は以下のようになります。
a..30 a..20
1行目の「a..30」を表示しているのは、10行目のprint文です。 ここでは、func2()の中で代入された、ローカル変数のaの値を表示しています。
2行目の「a..20」を表示しているのは、15行目のprint文です。 ここではグローバル変数のaの値を表示しています。
global文により、5行目の代入ではグローバル変数のaが参照されていること、 9行目ではローカル変数が参照されており、 代入してもグローバル変数には影響を与えていないことがわかります。
さて、実装についてですが、まず構文規則はこう(crowbar.yより)。
global_statement
: GLOBAL_T identifier_list SEMICOLON
;
globalトークンについて、GLOBAL_Tのように「_T」と付けているのは、 NULLなどと同様、何かとかち合うのではないかと考えたためです。
これにより、以下の構造体が生成されます。 これはStatement構造体中の共用体のひとつであり、 IfStatementやWhileStatement構造体と同列にあります。
typedef struct {
IdentifierList *identifier_list;
} GlobalStatement;
これが実行されると、変数ごとにGlobalVariableRefという構造体が生成され、 CRB_LocalEnvironmentにリストで繋がれます。 つまりglobalは「実行される文」であり、条件分岐などにより実行されないと、 そのグローバル変数は使えないことになります。 また、同一の変数について複数回globalを実行した場合、 2回目以降は無視されます。 よってループの内側にglobal文を置くことも可能です。
typedef struct GlobalVariableRef_tag {
char *name;
CRB_Value *value;
struct GlobalVariableRef_tag *next;
} GlobalVariableRef;
struct CRB_LocalEnvironment_tag {
char *current_function_name;
CRB_Object *variable; /* ScopeChain */
GlobalVariableRef *global_variable;
struct CRB_LocalEnvironment_tag *next;
};
そして、eval_identifier_expression()において、 このリストからグローバル変数を検索するようにすればよいわけです。
なお、スコープの問題でもうひとつ気になっていたこととして、 グローバル変数と関数が別々のスコープを持っている、 という点がありました。 この規則は、致命的ではないにせよ、 (特にクロージャが使える言語では)混乱を招くと思います。
そこで、eval_assign_expression()にて新しいグローバル変数を生成する前に、 同名の関数がないかチェックを入れ、 存在していたらエラーになるようにコードを修正しました。
(前略)
/* 同名の関数がないかどうかチェック */
if (crb_search_function(inter, left->u.identifier)) {
crb_runtime_error(inter, env, expr->line_number,
FUNCTION_EXISTS_ERR,
CRB_STRING_MESSAGE_ARGUMENT, "name",
left->u.identifier,
CRB_MESSAGE_ARGUMENT_END);
}
/* グローバル変数の生成 */
crb_add_global_variable(inter, left->u.identifier, src);
(後略)
従来、ネイティブ関数のプロトタイプ宣言は、このようになっていました。
CRB_Value hoge_func(CRB_Interpreter *interpreter,
int arg_count, CRB_Value *args);
しかし、ネイティブ関数でクロージャを作る時のことを考え、 LocalEnvironment構造体を引数に追加しました。
CRB_Value hoge_func(CRB_Interpreter *interpreter,
CRB_LocalEnvironment *env,
int arg_count, CRB_Value *args);
この引数は、現状のver.0.3.02のソースでは、 エラーメッセージの生成に使われている程度なのですが、 この先、ネイティブ関数で各種ライブラリを作る場合には、 クロージャを使用してオブジェクト等を作りたくなる ことでしょう。 そして、ネイティブ関数でクロージャを書けるようにするのなら、 そこからスコープチェーンを辿って、 外側の関数のローカル変数を参照できなければいけないでしょう。 これを実現するにはLocalEnvironmentが必要になるわけです(現状では、 実際にそれを行なうインタフェースは存在していませんが)。
なお、LocalEnvironment構造体をネイティブ関数に公開するため、 命名規則に従って、名前に「CRB_」を追加しています。
また、従来は、native.cはcrowbar.hを#includeしていましたが、 今後、crowbar 本体とは独立してネイティブ関数の開発が行なわれることもあり得るわけで、 この#includeはcrowbarの実装詳細に対する侵食と言えます。 そのため、ネイティブ関数からはcrowbar.hを#includeしなくて良いように ※1、 以下の修正を行ないました。
ひとつめの、「各種インタフェースを、CRB_dev.hに追加した」 の方は特に説明する必要はないでしょう。 配列やassocに対する操作のためのインタフェースが追加されています(現状、 まだまだ足りませんが)。
エラーメッセージについてですが、従来は、 crowbar本体が出すエラーメッセージもネイティブ関数が出すエラーメッセージも、 どちらもerror_message.c内のひとつの配列で保持されており、 そのインデックスを、crowbar.hで定義された列挙型で保持していました。 これではネイティブ関数をcrowbar本体から独立させることはできません。
そこで、CRB_NativeLibInfoという構造体型を提供し、この型の中に、 ネイティブ関数のライブラリで必要な各種情報を保持してもらうことにしました。
typedef struct {
CRB_MessageFormat *message_format;
} CRB_NativeLibInfo;
現状では、この構造体は、 エラーメッセージだけを保持するようになっていますが、 他にもネイティブ関数ライブラリに固有の情報があるようならここに詰め込めばよいでしょう。
ネイティブ関数ライブラリの側では、通常、 この構造体の実体を、以下のようにstaticに定義することになります。
static CRB_NativeLibInfo st_lib_info = {
crb_native_error_message_format,
};
そして、いざエラーを検出した時には、CRB_error()を呼び出します。
void CRB_error(CRB_Interpreter *inter, CRB_LocalEnvironment *env,
CRB_NativeLibInfo *info, int line_number, int error_code, ...);
見てわかるように、 この関数は引数としてCRB_NativeLibInfoへのポインタを受け取ります。 こうすることで、 各ネイティブ関数ライブラリごとに独立したエラーメッセージを表示することができるわけです。
なお、CRB_error()は、引数としてline_numberも受け取ります。 ここには、__LINE__を決め打ちで渡します。 __LINE__は、Cのプリプロセッサが予約しているマクロであり、 現在のCソース行番号に置換されます。 どうせ決め打ちで__LINE__を渡すのであれば、 CRB_error()をマクロにすればわざわざ書かなくても良さそうなものですが、 そして実際CRB_check_argument_count() という関数ではそのようにしているのですが、 CRB_error()が可変長引数を取る関数なのでマクロにするのはやめました。 DBG_debug_write()などで使っているように、可変長引数を持つマクロを C89(いわゆるANSI-C)で実現する方法はあるものの、 使いにくいと思われたためです。
さて、実際のところ、 crowbarを使ってアプリケーションを記述する開発者からすれば、 ネイティブ関数のどの行でエラーが起きたかなど興味はないかもしれません。 しかし、ネイティブ関数を開発する際にはこの情報は有用ですし、 「どの行のネイティブ関数の呼び出しでエラーが発生したか」 ということについては、 crowbar ver.0.3.02ではスタックトレースから知ることができます。
ところで、native.cのst_lib_infoに設定されている crb_native_error_message_formatというのは実はグローバル変数であり、 error_message.cで定義されています。 ネイティブ関数ライブラリをcrowbar本体から独立させる、 という観点からすればこれはまずいのですが、 native.cは標準ライブラリということでよいことにしておきます。 native.cのエラーメッセージをここに置いたのは、 日本語を含むCのソースを分散させたくなかったためです。
ネイティブポインタ型というのは、crowbar ver.0.1.01において、 fopen()などのファイル入出力関数を作りたくて追加したものです。 そこでは、
ネイティブポインタ型とは、 C#あたりでは「どうしてもメモリに直接アクセスしたい」 ケースで使用する型であるようですが、 crowbarのネイティブポインタ型は、そういう邪悪な型ではなく、 「ネイティブ関数からネイティブ関数へ、 Cレベルのポインタを持ち運ぶための型」です。
などと書いているわけですが… 実際には、現状のネイティブポインタ型では、 メモリに直接アクセスはできないものの、 今後いろいろな型が増えれば、 crowbarで書かれたプログラムだけでcrowbarのインタプリタを (Segmentation faultなどで)殺すことができるという点で、 邪悪な型であることに変わりはありません。 いやもう一瞬でもこれでうまくいくんじゃないかと思ってしまったことが 恥ずかしいというくらいのポカですすみません。
どういう場合に危険かといえば、たとえば今後GUIのライブラリが作られて、 ウィンドウを表現する型が作られたとき、
w = create_window(500, 300); ←ウィンドウを作成 str = fgets(w);
のように、ウィンドウを指すネイティブポインタ型を FILE*を渡すべきところに渡した場合、 fopen()の側ではそれをチェックする手段がなく、FILE*として扱う以外ない、 ということです。当然、 相当な高確率でインタプリタごとクラッシュすることでしょう。
これでは困りますから、ネイティブポインタ型に、 型の識別のためのメンバを追加しました。
typedef struct {
void *pointer;
CRB_NativePointerInfo *info;
} NativePointer;
CRB_NativePointerInfo型の構造体の実体は、NativeLibInfoと同じく、 ネイティブ関数ライブラリ側でstaticに保持します。 ネイティブポインタに含まれるポインタと、 その構造体へのポインタを比較することで、型チェックが可能であり、 そのためのユーティリティ関数がCRB_check_native_pointer_type()です。
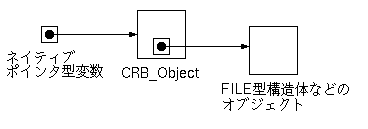
ところで、従来、ネイティブポインタ型は、 CRB_Value型に含まれる共用体のひとつのメンバとなっていました。
今回は、CRB_Object内の共用体メンバに引越しています。 CRB_Objectは、CRB_Valueから指される参照型ですから、 ネイティブポインタ型の変数がひとつあった時、 実際の(ネイティブな)オブジェクトは、 下図のように2段階のポインタで指されることになります。
これはなんとも無駄に見えますが、もし、 CRB_Objectを挟まずに各CRB_Valueが直接FILE構造体を指していたとすると、 「こっちでfclose()したFILE構造体を、 別のネイティブポインタから参照していた」というケースで、 Cのdangling pointerと同様の現象が発生します。 その点、CRB_Objectを一階層挟んでやれば、 fclose()と同時にそのポインタを無効化できるだけでなく、 ファイナライザの実装も可能になります。
CRB_NativePointerInfo構造体の定義は以下のようになっていて、
typedef struct {
char *name;
CRB_NativePointerFinalizeProc *finalizer;
} CRB_NativePointerInfo;
nameは単にそのネイティブポインタ型の名前を指定しているだけですが (そして、 型の一致の判定には現状ではこの構造体のポインタしか使っていないので名前は不要なのですが)、 finalizerの方は、ネイティブポインタ型のCRB_Object への参照がなくなった時の挙動を定義するためのメンバです。 FILE構造体へのポインタでは、以下のような定義になっていて、
static CRB_NativePointerInfo st_file_type_info = {
"crowbar.lang.file",
file_finalizer
};
ここでfile_finalizerという関数へのポインタが設定されています。 その関数の内部では、以下のように、引数で渡されたCRB_OBject からネイティブポインタを取り出し、fclose()しているわけです。
void
file_finalizer(CRB_Interpreter *inter, CRB_Object *obj)
{
FILE *fp;
fp = (FILE*)CRB_object_get_native_pointer(obj);
if (fp) {
fclose(fp);
}
}
まあ、現実問題として「ファイナライザなんて当てにするものではない」 というのがJavaなどでプログラムを書く場合の鉄則ではありますが、 処理系やライブラリを作る側としては、 「保険」として用意しておくのも悪くはないでしょう。
配列に対してresize()とinsert()、remove()を追加、 文字列に対してsubstr()を追加しました。
位置指定は、すべてゼロから始まります。 remove()やsubstr()の第1引数では、配列の先頭要素、 または先頭の文字をゼロとして数えますし、 insert()の挿入個所は、先頭の要素のさらに前を0、 先頭の要素と2番目の要素の間を1と数えます。
# 配列のサイズを1000に変更
a.resize(1000);
# たとえば{1, 2, 3, 4, 5}にこれを適用すると、
# {1, 2, 3, "a", 4, 5}となる。
a.insert(3, "a");
# たとえば{1, 2, 3, 4, 5}にこれを適用すると、
# {1, 2, 3, 5}となる。
a.remove(3);
# たとえば"abcdefg"にこれを適用すると、
# "de"となる。
s.substr(3, 2);
現状では、文字列のメソッドは、length()、 substr()ともに日本語対応していません。 単純にバイト単位で数えますので、 substr()が漢字の途中をちょん切る可能性もあります。
さて、実装ですが、さすがにこれだけ「メソッドもどき」の数が増えてくると、 従来のように条件分岐をべたべたと書いていたのでは関数が大きくなりすぎるので、 以下のような関数テーブルを作り、ディスパッチするようにしました。
typedef struct {
ObjectType type;
char *name;
int argument_count;
void (*func)(CRB_Interpreter *inter, CRB_LocalEnvironment *env,
int line_number, CRB_Object *obj, CRB_Value *result);
} FakeMethodTable;
(中略)
static FakeMethodTable st_fake_method_table[] = {
{ARRAY_OBJECT, "add", 1, array_add_method},
{ARRAY_OBJECT, "size", 0, array_size_method},
{ARRAY_OBJECT, "resize", 1, array_resize_method},
{ARRAY_OBJECT, "insert", 2, array_insert_method},
{ARRAY_OBJECT, "remove", 1, array_remove_method},
{STRING_OBJECT, "length", 0, string_length_method},
{STRING_OBJECT, "substr", 2, string_substr_method},
};
さて、今回の目玉である例外処理機構です。
実行時エラーが発生すると、 インタプリタはcrb_runtime_error()という関数を呼び出しますが、 従来、この関数はその内部でexit()するという(乱暴な)仕様になっていました。 これでは、 何らかのアプリケーションの組み込み言語としてcrowbarを使おうとしたとき、 カスタマイズのためのスクリプトのバグひとつでアプリケーション全体がコケてしまうことになり、 使えません。
そこで、暫定的ですが、例外処理機構を作りました。 現在は以下のような仕様になっています。
3番目、4番目の制限でずっこけた人もいそうですが、 現状こうなっているのは、時間の都合もありますが、 例外オブジェクトがどうあるべきか、 ということについて私の中でまだ結論が出ていないというのもあります。 御意見等ありましたらお寄せください。
さて、crb_runtime_error()が呼び出されると、 エラーメッセージと、発生時点の関数名、行番号を詰め込んで、 下図のようなオブジェクト(assoc)が生成されます。
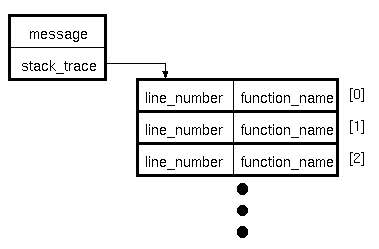
例外オブジェクトには、message, stack_traceというふたつのメンバがあり、 messageにはエラーメッセージ、 stack_traceには、 エラーの発生個所を示すスタックトレースが配列でセットされます。 スタックトレースは行番号と関数名からなるassocの配列で、 まさに実行時エラーが発生した個所の関数名、行番号が配列の先頭に格納され、 その関数を呼び出した個所が[1]に、さらにその関数を呼び出した個所が[2]に、 という形で格納されていきます。 そのまま誰もcatchしなければ、エラーメッセージとスタックトレースをダンプしてインタプリタは終了します。 Javaなどと同じ仕様ですね。 なお、スタックトレースの関数名部分は、 無名クロージャの場合は「anonymous closure」に、 トップレベルは「top level」となります。
さて、例外は、以下の構文でcatchすることができます。
1: function print_stack_trace(e) {
2: print(e.message + "\n");
3: for (i = 0; i < e.stack_trace.size(); i++) {
4: print(e.stack_trace[i].function_name
5: + " " + e.stack_trace[i].line_number + "\n");
6: }
7: }
8:
9: a = new_array(10);
10: try {
11: a[100] = 10;
12: } catch (e) {
13: print_stack_trace(e);
14: } finally {
15: print("finally_block\n");
16: }
「以下の構文でcatchすることができます」と言っておきながら何ですが、 1~7行目までは、スタックトレースの表示ルーチンです。 現状、スタックトレースを吐くメソッドやネイティブメソッドがないので、 テストではcrowbarで書きました。 いやその今は色々なものが足りてないです。
さて、10~16行目までが、try catch finallyです。 意味はJavaと同様で、例外が発生した場合、try節の実行が中断され、 catch節が実行されます。 ひとつのcatchがすべての例外を捕えるため、 catchが複数並ぶことはありません。 また、finally節は例外が起きても起きなくても必ず実行されます。
catch節では、発生した例外オブジェクトをeで拾っています。 Javaなどでは中括弧でスコープが閉じるため、 catchで例外を拾うのに使った変数は、そのcatch節の中だけで参照可能ですが、 crowbarでは、関数にはローカル変数がありますが、 中括弧で囲んだだけではスコープは形成されません。 そこで、「catch (e)」のような形で例外を拾うことは、 eという変数への例外オブジェクトの代入を意味する、という仕様になっています。 現状でeが存在せず、関数内なら、新たなローカル変数eが生成されますし、 トップレベルならグローバル変数です。 そして、既存の変数eが存在するのなら、 その変数への代入として解釈されます。
さて、このような例外処理機構をどのように実装するかですが。
crowbarでは、文や式を評価する際、
再帰呼び出しを使って解析木を再帰的に辿ります(execute.cとeval.c)。
よって、実行時例外が検出されるのは、
関数呼び出しの階層のとてもとても深いところ、ということになります。
そういう深い所で、実行を中断し、かなり上の方、
すなわち最寄りのcatch
または関数呼び出し(そこでスタックトレースを配列に詰める)
まで戻ってこなければなりません。
こういうことは、
関数の戻り値でちまちまとステータスを返すことでも実現できますが
(そしてbreak文とかでは実際そのように実装したのですが)、
式の評価は複雑なので、正直、やってられません。面倒すぎて。
ということで、今回はsetjmp/longjmpを使用しています。
普段Cを使っているような人でも、setjmp()/longjmp()にはあまり馴染みがない、 という人が多いかもしれません。 というより、「ただのgotoでさえ邪悪だと言われるのに、 関数の境界を越えられるlongなjumpなんてとんでもない!」 と思っている人もいるかもしれません。
でも、何事も、良いか悪いかはちゃんと調べてみなければわかりません。 自分で使いもしないうちから、「こんなのダメだ」と否定するのも、 頭の悪い話ですよね。
てなわけで、setjmp()/longjmp()を簡単に説明すると、
setjmp()は、環境を保存した時にはゼロを返し、 longjmp()から戻って来た時には、longjmp()の第2引数を返します。 とりあえず今は、longjmp()の第2引数には、 ゼロ以外の適当な値を渡せばよいと思っておいてください。
これらを使うと、以下のように書くことで、 関数呼び出しの深いところから一気に戻ってくることができます。
/* 呼び出し元の環境を保持するために、変数をひとつ用意する */
jmp_buf recovery_environment;
if (setjmp(recovery_environment) == 0) {
/* setjmp()は、最初の呼び出しでは0を返すので、ここに来る。
* ここで、正常な場合の処理を行なう。
* この中でlongjmp()を呼び出すと、
* 下のelse節が実行される。
* longjmp()を呼ぶのは、ここから呼び出された関数の
* 深いところでもかまわない。
*/
long_jmp(recovery_environment, 1);
} else {
/*
* longjmp()が実行されると、処理がここに来る。
*/
}
setjmp()で引数として渡したjmp_bufに、「現在の環境」が保存されます。 「現在の環境」には、 現在のレジスタの値などいろいろなものが含まれますが、 ひとまず、setjmp()を呼び出したこの場所を憶えておいてくれる、 と思ってください。 longjmp()でそのjmp_bufを引数として渡すことで、 jmp_bufに保存されていた場所に戻ることができるわけです。
なお、「setjmp()では引数に&も付けずに渡しているが、 なぜそこに環境を保存することができるのか。 Cの引数は値渡しだろ」という疑問を持つ人もいるかもしれませんが、 それは、jmp_bufという型が配列をtypedefしたものだからです。 是非お手元の環境にて確認してみてください。 私としては、「なぜこんな混乱を招くような仕様にするかなあ」 と思いますけれど。
実際のcrowbarのソースでは、try catch finallyの構文は、 以下のように表現されています(excecute.cより)。
1: /* 現状のcrowbarスタックのスタックポインタ、
2: およびjump_bufのバックアップ */
3: stack_pointer_backup = crb_get_stack_pointer(inter);
4: env_backup = inter->current_recovery_environment;
5: if (setjmp(inter->current_recovery_environment.environment) == 0) {
6: /* try節 */
7: result = crb_execute_statement_list(inter, env,
8: statement->u.try_s.try_block
9: ->statement_list);
10: } else {
11: /* catch節 */
12:
13: /* スタックポインタとjump_bufの復元 */
14: crb_set_stack_pointer(inter, stack_pointer_backup);
15: inter->current_recovery_environment = env_backup;
16:
17: if (statement->u.try_s.catch_block) {
18: CRB_Value *dest;
19: CRB_Value ex_value;
20: /* 例外を保持するCRB_Valueの生成。
21: エラーの発生時に、例外オブジェクトがinter->current_exceptionに
22: 保持されている。 */
23: ex_value.u.object = inter->current_exception;
24: ex_value.type = CRB_ASSOC_VALUE;
25: CRB_push_value(inter, &ex_value);
26: inter->current_exception = NULL;
27:
28: /* 例外オブジェクトを変数に代入(変数がなければ作る) */
29: dest = crb_get_identifier_lvalue(inter, env,
30: statement->u.try_s.exception);
31: if (dest == NULL) {
32: if (env != NULL) {
33: crb_add_local_variable(inter, env,
34: statement->u.try_s.exception,
35: &ex_value);
36: } else {
37: if (crb_search_function(inter,
38: statement->u.try_s.exception)) {
39: crb_runtime_error(inter, env, statement->line_number,
40: FUNCTION_EXISTS_ERR,
41: CRB_STRING_MESSAGE_ARGUMENT, "name",
42: statement->u.try_s.exception,
43: CRB_MESSAGE_ARGUMENT_END);
44: }
45: crb_add_global_variable(inter,
46: statement->u.try_s.exception,
47: &ex_value);
48: }
49: } else {
50: *dest = ex_value;
51: }
52: /* catch節の文の実行 */
53: result = crb_execute_statement_list(inter, env,
54: statement->u.try_s.catch_block
55: ->statement_list);
56: CRB_shrink_stack(inter, 1);
57: }
58: }
59: inter->current_recovery_environment = env_backup;
60: if (statement->u.try_s.finally_block) {
61: /* finally節 */
62: finally_result
63: = crb_execute_statement_list(inter, env,
64: statement->u.try_s.finally_block
65: ->statement_list);
66: /* finally 節でbreakしていたらbreak, returnしていたらreturnする */
67: if (finally_result.type != NORMAL_STATEMENT_RESULT) {
68: result = finally_result;
69: }
70: }
71: /* 例外がcatchされていなければ、再度投げる */
72: if (!statement->u.try_s.catch_block && inter->current_exception) {
73: longjmp(env_backup.environment, LONGJMP_ARG);
74: }
75:
76: return result;
crowbarは自前のスタックを使って式の評価を行ないますが、 そのスタックポインタを3行目でバックアップしています。 式の深いところでエラーが発生した場合、 その分のスタックを破棄しなければならないためです。
また、4行目ではenv_backupという変数へのバックアップも行なっていますが、 この変数の型はRecoveryEnvironment型で、 その定義はこうなっています(crowbar.h)
typedef struct {
jmp_buf environment;
} RecoveryEnvironment;
つまり事実上jmp_buf型と同じです(将来的な追加に備え、 一応構造体を用意しました)。
ここで、jmp_bufのバックアップを行なうのは、 try catchのネスティングを可能にするためです。
5行目でsetjmp()しています。longjmp()にjmp_bufを引き渡すため、 CRB_Interpreterにjmp_bufを保存しています。 また、22行目を見るとわかるように、発生した例外オブジェクトも CRB_Interpreter経由で受け渡ししています。
そしていざエラーが発生するとelse側が実行されます。 14~15行目では、例外状態から復帰するため、 スタックポインタとjmp_bufを復元しています なお、 jmp_bufの復元は、エラーが発生しなかった場合も行なわなければならないため、 59行目でも行なっています。
62行目からがfinally節の実行です。 ところで、finally節は、 たとえば以下のようなコードでも実行されなければなりません。
for (;;) {
try {
break;
} finally {
print("hoge\n");
}
}
crowbarでは、breakなどのジャンプ的な挙動をする文については、 文の実行結果(CRB_StatementResult)を戻り値として返すことで制御しています (こちらを参照)。 上のソースでは、 try節の実行結果(7行目でresultに代入されている)を無視して finally節を実行していますから、 「finallyが必ず実行される」ことは保証できますが、 一方、try節でbreakしていたら、 finally実行後にはやっぱりbreakしなければなりません。 また、try節でbreakし、finallyでreturnしていた場合には、 最終的にはやっぱりreturnするのが正しいのではないかと思います (ちなみにJavaでこういう変態的なコードを書くと、 javacは警告を出すようです。
for (;;) {
try {
break;
} finally {
return;
}
}
# ここは実行されない。
ということで、try文の最終的な戻り値としては、 「finally節がNORMAL_STATEMENT_RESULTでなかったら、 finally節の戻り値を優先する」ということにしました。 Javaだと、try節のreturnをfinally節のbreakより優先するようで (面倒なので仕様確認してません)、 その挙動とはちょっと違うんですけど。
なお、関数呼び出し部分は以下のようになっています。
stack_pointer_backup = crb_get_stack_pointer(inter);
env_backup = inter->current_recovery_environment;
if (setjmp(inter->current_recovery_environment.environment) == 0) {
do_function_call(inter, local_env, env, expr, func);
} else {
/* スタックトレースへの追加 */
add_stack_trace(inter, env, expr->line_number);
dispose_local_environment(inter);
crb_set_stack_pointer(inter, stack_pointer_backup);
/* さらに呼び出し元へ復帰 */
longjmp(env_backup.environment, LONGJMP_ARG);
}
inter->current_recovery_environment = env_backup;
dispose_local_environment(inter);
return_value = pop_value(inter);
pop_value(inter); /* func */
push_value(inter, &return_value);
構造的には同じようなものですが、 スタックトレースへの追加(11/15追記: 戻るほうでスタックトレースに詰めてちゃだめじゃん… ってことで次バージョンで修正します(_o_))と LocalEnvironmentの解放を行なっていること、 および、エラーが発生した際には、 さらにlongjmp()して呼び出し元へ復帰している点が異なります。
以前挙げた修正点の現在の状態はこんな感じです。
例外処理周りは、throw文の追加程度はわけもなくできますが、 そもそも何をthrowできるようにすべきか、 現状のようになにもかもひとつのcatchで受けるなら、 例外の識別はどのようにすべきか、 それともJavaなどのように選択的なcatchをできるようにすべきなのか、 等々、仕様上考えなければならないところがまだまだあります。
日本語関連の問題は、 単にSJISのリテラルを読めるようにするだけなら レキシカルアナライザの修正だけで済むのですが、 length()メソッドやsubstr()メソッドがバイト単位でしか動作しないというのもやはり問題ですので、 同時に解決するならやっぱりUnicode(UCS-2)かなあ (サロゲートペアとかはあきらめるとして)、とか考えています。
また、モジュールは、 各種のライブラリを用意するために必要になるわけですが、 crowbarが実用言語になるためには、やはりライブラリの充実が最重要なので、 ネイティブライブラリの拡充を併せて考えていかなければならないな、 と思っています(まあ、実際に実用に使われるかどうかはともかくとして)。
それではまた気長にお待ちくださいませ。