前回までで、Webサーバの最低限の基本機能、 HTMLや画像を送ることができるようになりました。
最初に作ったのは、TCPサーバでした。 TCPを使うことで、サーバとクライアントの間でバイト単位で データをやりとりすることができるようになりました。
TCPは、このように、単なるバイト列を送るための仕組みなので、 Webサーバに限らず、多くのアプリケーションが使用しています。 たとえばメールクライアントとメールサーバのやり取りなども、 通常はTCPの上に構築されたプロトコル(SMTPとかPOP3とかIMAP4とか)を 使用しています。
Webサーバがページを配信するのに使うプロトコルは、 HTTP(HyperText Transfer Protocol)です。 「プロトコル」というのは要するに「取り決め」のことで、 全然別の会社や団体が作っているWebサーバとブラウザが通信できるのは、 双方がこの取り決めに従っているからです。 前回Webサーバを作ったとき、ApacheやFirefoxの動きを見ながら リクエストヘッダやレスポンスヘッダを参照したり出力したりしましたが、 あれを規定しているのがプロトコルです。 インターネットの世界では、プロトコルを文書化したものはRFC (Request For Comments)としてまとめられています。
HTTP――はいぱあてきすととらんすふぁーぷろとこる、などと言うと なにやらすごいもののように思えるかもしれませんが、 通常のWebページの閲覧で使う範囲であれば、 前回実際に作ってみたように、それほどたいしたものでもありません。
とはいえ前回の実装はあまりに手抜き過ぎです。 たとえばリクエストされたファイルがなかった場合、 正しい対応は皆さんおなじみ「404 Not Found」を返すことですが、 前回作ったWebサーバはそのスレッドが例外を出して死にます。 これではあんまりだ、ということで、 今回はそういった細かい対応を行います。
まずはリクエストされたファイルがない場合の対応です。
例によって、このページで作った Client01.javaでローカルのApacheを叩いて反応を見てみます。 念のためClient01.javaを再掲のうえ、 クライアントからサーバに送付するデータ(client_send.txt)も掲載します。
まずはClient01.java。
import java.io.*;
import java.net.*;
public class Client01 {
public static void main(String[] args) throws Exception {
try (Socket socket = new Socket("localhost", 80);
FileInputStream fis = new FileInputStream("client_send.txt");
FileOutputStream fos = new FileOutputStream("client_recv.txt")) {
int ch;
// client_send.txtの内容をサーバに送信
OutputStream output = socket.getOutputStream();
while ((ch = fis.read()) != -1) {
output.write(ch);
}
// 終了を示すため、ゼロを送信
// output.write(0);
// サーバからの返信をclient_recv.txtに出力
InputStream input = socket.getInputStream();
while ((ch = input.read()) != -1) {
fos.write(ch);
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
こちらがclient_send.txtです。
1: GET /xxxx.html HTTP/1.1 2: Host: localhost:80 3: User-Agent: Mozilla/5.0 (Windows NT 6.0; rv:22.0) Gecko/20100101 Firefox/22.0 4: Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 5: Accept-Language: ja,en-us;q=0.7,en;q=0.3 6: Accept-Encoding: gzip, deflate 7: Connection: keep-alive 8:
client_send.txtの1行目で、存在しないファイル(xxxx.html)を指定しています。
このリクエストでApacheを叩いてみたところ、 私の環境では以下のレスポンスが返りました。
1: HTTP/1.1 404 Not Found 2: Date: Mon, 05 Aug 2013 15:28:10 GMT 3: Server: Apache/2.4.6 (Win32) 4: Content-Length: 207 5: Keep-Alive: timeout=5, max=100 6: Connection: Keep-Alive 7: Content-Type: text/html; charset=iso-8859-1 8: 9: <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> 10: <html><head> 11: <title>404 Not Found</title> 12: </head><body> 13: <h1>Not Found</h1> 14: <p>The requested URL /xxxx.html was not found on this server.</p> 15: </body></html>
1行目で、HTTPステータスコードとして404が指定されています。 以前確認した「200」 は成功を表すステータスコードでしたが、(時々ブラウザに表示されるおなじみの) 404はファイルが見つからないときのステータスコードであるわけです。
見る限り、レスポンスヘッダはだいたい200のときと同じで、 8行目の空行の後、9行目からは、 404のときにブラウザに表示するHTMLが入っています。
なお、ここでは表現できていませんが、8行目までは改行コードがCR+LF、 9行目以降はLFになっていました。 レスポンスヘッダまでは改行がCR+LFであることが HTTPの規格で決められていますが、 ボディについてはそれこそ画像ならバイナリが入っていたりするわけで、 テキストであっても、改行コードの保証はありません。 ここはつまり、事前に用意した404用の HTMLファイルをそのまま返せばよいということでしょう。
それでは実装します。まずはmain()メソッドのあるMain.javaですが、 これは前回のものと同じです。
import java.io.*;
import java.net.*;
import java.util.*;
public class Main {
public static void main(String[] argv) throws Exception {
try (ServerSocket server = new ServerSocket(8001)) {
for (;;) {
Socket socket = server.accept();
ServerThread serverThread = new ServerThread(socket);
Thread thread = new Thread(serverThread);
thread.start();
}
}
}
}
また、404に対応するための修正ではありませんが、 前回作ったいくつかのユーティリティメソッドをUtil.javaに切り出しました。
import java.io.*;
import java.util.*;
import java.text.*;
class Util {
// InputStreamからのバイト列を、行単位で読み込むユーティティメソッド
static String readLine(InputStream input) throws Exception {
int ch;
String ret = "";
while ((ch = input.read()) != -1) {
if (ch == '\r') {
// 何もしない
} else if (ch == '\n') {
break;
} else {
ret += (char)ch;
}
}
if (ch == -1) {
return null;
} else {
return ret;
}
}
// 1行の文字列を、バイト列としてOutputStreamに書き込む
// ユーティリティメソッド
static void writeLine(OutputStream output, String str)
throws Exception {
for (char ch : str.toCharArray()) {
output.write((int)ch);
}
output.write((int)'\r');
output.write((int)'\n');
}
// 現在時刻から、HTTP標準に合わせてフォーマットされた日付文字列を返す
static String getDateStringUtc() {
Calendar cal = Calendar.getInstance(TimeZone.getTimeZone("UTC"));
DateFormat df = new SimpleDateFormat("EEE, dd MMM yyyy HH:mm:ss",
Locale.US);
df.setTimeZone(cal.getTimeZone());
return df.format(cal.getTime()) + " GMT";
}
// 拡張子とContent-Typeの対応表
static final HashMap<String, String> contentTypeMap =
new HashMap<String, String>() {{
put("html", "text/html");
put("htm", "text/html");
put("txt", "text/plain");
put("css", "text/css");
put("png", "image/png");
put("jpg", "image/jpeg");
put("jpeg", "image/jpeg");
put("gif", "image/gif");
}
};
// 拡張子を受け取りContent-Typeを返す
static String getContentType(String ext) {
String ret = contentTypeMap.get(ext.toLowerCase());
if (ret == null) {
return "application/octet-stream";
} else {
return ret;
}
}
}
次はServerThread.javaです。
import java.io.*;
import java.net.*;
class ServerThread implements Runnable {
private static final String DOCUMENT_ROOT = "C:\\maebashi\\homepage";
private static final String ERROR_DOCUMENT = "C:\\webserver\\error_document";
private Socket socket;
@Override
public void run() {
OutputStream output;
try {
InputStream input = socket.getInputStream();
String line;
String path = null;
String ext = null;
while ((line = Util.readLine(input)) != null) {
if (line == "")
break;
if (line.startsWith("GET")) {
path = line.split(" ")[1];
String[] tmp = path.split("\\.");
ext = tmp[tmp.length - 1];
}
}
output = socket.getOutputStream();
try (FileInputStream fis
= new FileInputStream(DOCUMENT_ROOT + path);) {
SendResponse.SendOkResponse(output, fis, ext);
} catch (FileNotFoundException ex) {
SendResponse.SendNotFoundResponse(output, ERROR_DOCUMENT);
}
} catch (Exception ex) {
ex.printStackTrace();
} finally {
try {
socket.close();
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
ServerThread(Socket socket) {
this.socket = socket;
}
}
基本的な構造は前回と変わりませんが、28〜33行目のtry catchにて、 FileNotFoundExceptionに対する例外処理をしています。 また、レスポンスを返す部分を、SendResponseクラスに分離しました。
そして、そのSendResponse.javaが以下です。
import java.io.*;
import java.net.*;
class SendResponse {
static void SendOkResponse(OutputStream output, FileInputStream fis,
String ext) throws Exception {
Util.writeLine(output, "HTTP/1.1 200 OK");
Util.writeLine(output, "Date: " + Util.getDateStringUtc());
Util.writeLine(output, "Server: Server04.java");
Util.writeLine(output, "Connection: close");
Util.writeLine(output, "Content-type: "
+ Util.getContentType(ext));
Util.writeLine(output, "");
int ch;
while ((ch = fis.read()) != -1) {
output.write(ch);
}
}
static void SendNotFoundResponse(OutputStream output,
String errorDocumentRoot)
throws Exception {
Util.writeLine(output, "HTTP/1.1 404 Not Found");
Util.writeLine(output, "Date: " + Util.getDateStringUtc());
Util.writeLine(output, "Server: Server04.java");
Util.writeLine(output, "Connection: close");
Util.writeLine(output, "Content-type: text/html");
Util.writeLine(output, "");
try (FileInputStream fis
= new FileInputStream(errorDocumentRoot + "/404.html");) {
int ch;
while ((ch = fis.read()) != -1) {
output.write(ch);
}
}
}
}
共通部分が結構あってプログラムとしては汚いのですが、 今は気にしないことにします。
32行目からのコードで、errorDocumentRoot(これはSenderThread.javaの中で "C:\webserver\error_document"と定義されています。 環境に合わせてフォルダを作成してください)以下の404.htmlという htmlファイルを読み出して返すようにしています。
404.htmlも各自用意してください。 私は、シンプルに以下の内容のファイルを配置しました。
1: <html> 2: <head> 3: <meta HTTP-EQUIV="Content-Type" CONTENT="text/html;charset=Shift_JIS"> 4: <title>ファイルが見つかりませんでした</title> 5: </head> 6: <body> 7: <p> 8: ごめんなさい。ファイルが見つかりませんでした。 9: </p> 10: </body> 11: </html>
上記プログラムを動かし、404.htmlを配置してFirefoxで存在しないファイル (xxxx.html)を指定したところ、ちゃんとエラーページが出ました。
ただし、IEの場合、以下のような画面になることがあります。
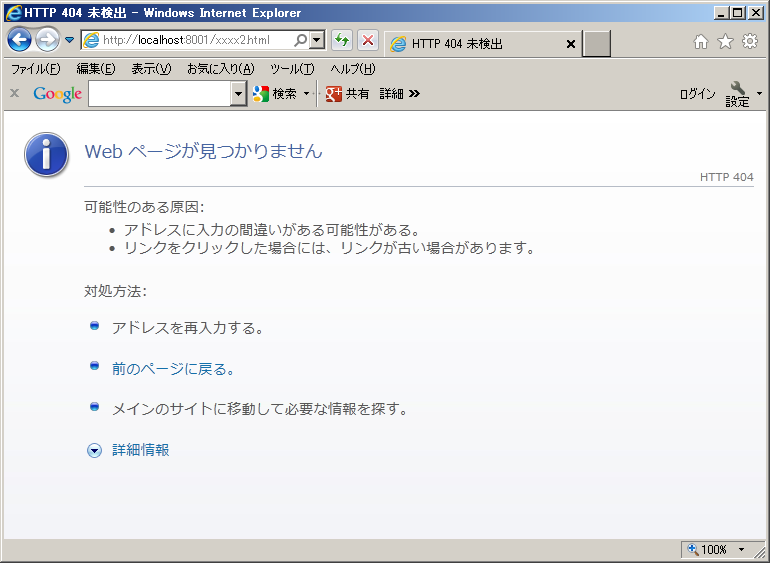
これは、Internet Explorerは、サーバの返したエラーページのサイズが 512バイト以下のとき、ブラウザ側で用意したエラーページを表示するという 仕様になっているためです。Wikipediaの記事(2013年8月14日時点)を見るとIE6以前の話のように読めますが、 今、うちのIE9で試してもこの仕様になっていました。
IEでエラーページが出ることを試したい場合は、 ファイルを大きくする等工夫してください。
たとえば私のWebサイトといえば http://kmaebashi.comであり、ブラウザにそのように入力すれば トップページが見えます。
また、この「本当の基礎からのWebアプリケーション入門」を見るときには http://kmaebashi.com/programmer/webserver/で http://kmaebashi.com/programmer/webserver/index.htmlが見えます。
これは、ファイル名まで指定しなかったときにはWebサーバ側で index.htmlというファイル(どんなファイル名かはサーバの設定による)を 返してくれるからです――と言えれば作るのも簡単なのですが、 ここは実際はもうちょっと複雑です。見ていきましょう。
ところで、ここまでWebサーバの挙動を見るときには、 Client01.javaにてApache等を叩いていました。 しかし、いちいちclient_send.txtをいじるのも面倒ですし、 「HTTPを生で見る」という目的はそろそろ達したと思いますので、 ここらで便利なツールに頼ります。 私は自分のブラウザ(Firefox)に HttpFox というアドオンを入れました。
これを使うと、HTTPのリクエストやレスポンスを確認できます (下がキャプチャ。クリックで拡大)※1。

アドオンでなく、プロキシとして通信に割り込む方式のツールとして Fiddlerあたりも有名です。 今の目的ではこれでもよいですが、 この手のツールだとSSLの通信を見ることができません( 途中経路が暗号化されているのがSSLなのだから当たり前)。
では、kmaebashi.com以下のページをいくつか参照し、 HttpFoxでその動きを見ていきます。
| ブラウザに入力したURL | リクエスト・ライン | ステータス・ライン |
|---|---|---|
| http://kmaebashi.com | GET / HTTP/1.1 | HTTP/1.1 200 OK |
| http://kmaebashi.com/ | GET / HTTP/1.1 | HTTP/1.1 200 OK |
| http://kmaebashi.com/programmer/webserver | GET /programmer/webserver HTTP/1.1 | HTTP/1.1 301 Moved Permanently |
| http://kmaebashi.com/programmer/webserver | GET /programmer/webserver/ HTTP/1.1 | HTTP/1.1 200 OK |
まず、トップページを参照する場合、ブラウザに http://kmaebashi.comと入力しても、末尾にスラッシュをつけて http://kmaebashi.com/と入力しても、ブラウザが投げるリクエストは同じです。 これに対してサーバはトップに存在するindex.htmlを返しています。
問題は、「http://kmaebashi.com/programmer/webserver」のように、 下位のディレクトリを末尾のスラッシュをつけずに参照したときです。 サーバはステータスコードとして200を返すのではなく、 「301 Moved Permanently」というステータスを返しています。
Moved Permanentlyという言葉からわかるように、 ステータスコード301は、サーバからの「ページの本体は(今は)こちらにあるから こっちを見ろ」という指示を意味します。このような指示を リダイレクトと言います。 以下にHttpFoxの画面を載せます(クリックで拡大)が、 ブラウザは、301を受け取った後、http://kmaebashi.com/programmer/webserver/ というスラッシュをつけたURLを取りに行っていることがわかります。

上の画像にも写っていますが、レスポンスのLocationヘッダが、 ブラウザが参照すべき正しいURLを示しています。
念のため、Client01.javaを使って生のレスポンスを取得してみました。
1: HTTP/1.1 301 Moved Permanently 2: Date: Thu, 15 Aug 2013 17:42:40 GMT 3: Server: Apache/2.2.14 (Unix) mod_ssl/2.2.14(長いので後略) 4: Location: http://kmaebashi.com/programmer/webserver/ 5: Content-Length: 250 6: Keep-Alive: timeout=5, max=100 7: Connection: Keep-Alive 8: Content-Type: text/html; charset=iso-8859-1 9: 10: <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> 11: <html><head> 12: <title>301 Moved Permanently</title> 13: </head><body> 14: <h1>Moved Permanently</h1> 15: <p>The document has moved <a href="http://kmaebashi.com/programmer/webserver/">here</a>.</p> 16: </body></html>
7行目にLocationヘッダがありますね。
考えてみれば、「http://kmaebashi.com/programmer/webserver」 というURLからは、 末尾のwebserverがファイル名であるのかディレクトリ名であるのかが判定できません (拡張子がついていませんが、特にUNIXでは、 ファイルに拡張子は必須ではありません)。 そこでWebサーバは、「ファイルはないけどディレクトリならあるのでこっちを見ろ」 という指示を返しているわけです※2。
インターネットにおける古典的なFAQに、 「URLの末尾のスラッシュは要るの? 要らないの?」というものがあります。
ここまで読んできた方ならお分かりのように、この質問に対する回答は、
では実装してみます。まずはServerThread.javaです。
import java.io.*;
import java.net.*;
import java.nio.file.*;
class ServerThread implements Runnable {
private static final String DOCUMENT_ROOT = "C:\\maebashi\\homepage";
private static final String ERROR_DOCUMENT = "C:\\webserver\\error_document";
private static final String SERVER_NAME = "localhost:8001";
private Socket socket;
@Override
public void run() {
OutputStream output = null;
try {
InputStream input = socket.getInputStream();
String line;
String path = null;
String ext = null;
String host = null;
while ((line = Util.readLine(input)) != null) {
if (line == "")
break;
if (line.startsWith("GET")) {
path = line.split(" ")[1];
String[] tmp = path.split("\\.");
ext = tmp[tmp.length - 1];
} else if (line.startsWith("Host:")) {
host = line.substring("Host: ".length());
}
}
if (path == null)
return;
if (path.endsWith("/")) {
path += "index.html";
ext = "html";
}
output = new BufferedOutputStream(socket.getOutputStream());
try (InputStream fis
= new BufferedInputStream(new FileInputStream(DOCUMENT_ROOT
+ path))) {
SendResponse.SendOkResponse(output, fis, ext);
} catch (FileNotFoundException ex) {
FileSystem fs = FileSystems.getDefault();
Path pathObj = fs.getPath(DOCUMENT_ROOT + path);
if (Files.isDirectory(pathObj)) {
String location = "http://"
+ ((host != null) ? host : SERVER_NAME)
+ path + "/";
SendResponse.SendMovePermanentlyResponse(output, location);
} else {
SendResponse.SendNotFoundResponse(output, ERROR_DOCUMENT);
}
}
} catch (Exception ex) {
ex.printStackTrace();
} finally {
try {
if (output != null) {
output.close();
}
socket.close();
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
ServerThread(Socket socket) {
this.socket = socket;
}
}
まず、35行目からのif文で、パスの末尾がスラッシュのときは その後ろにindex.htmlを付け足しています。 これで、スラッシュつきでディレクトリが指定された場合に対応できます。
スラッシュなしでディレクトリが指定された場合の対応は、 FileNotFoundExceptionのハンドラの中に書いています(45行目から)。 せっかくのJava7なので、java.nio.fileパッケージを使って パスがディレクトリであることを判定しています。
ディレクトリだった場合、301を返すわけですが、その際、 Locationヘッダを返さなければなりません。 Locationヘッダで返すのはhttp://から始まる完全なURLですから、 サーバ名が必要です。ここでは、8行目でSERVER_NAMEに定義しています (Apacheなら、httpd.confのServerNameディレクティブで設定します)。 また、バーチャルホストの機能があるわけでもないので特に役には立ちませんが、 Hostヘッダがあるときはそちらを使うようにしています。
51行目でSendResponseクラスのSendMovePermanentlyResponse()を呼び出しています。 SendResponse.javaはこちらです。
import java.io.*;
import java.net.*;
class SendResponse {
static void SendOkResponse(OutputStream output, InputStream fis,
String ext) throws Exception {
Util.writeLine(output, "HTTP/1.1 200 OK");
Util.writeLine(output, "Date: " + Util.getDateStringUtc());
Util.writeLine(output, "Server: Server05.java");
Util.writeLine(output, "Connection: close");
Util.writeLine(output, "Content-type: "
+ Util.getContentType(ext));
Util.writeLine(output, "");
int ch;
while ((ch = fis.read()) != -1) {
output.write(ch);
}
}
static void SendMovePermanentlyResponse(OutputStream output,
String location)
throws Exception {
Util.writeLine(output, "HTTP/1.1 301 Moved Permanently");
Util.writeLine(output, "Date: " + Util.getDateStringUtc());
Util.writeLine(output, "Server: Server05.java");
Util.writeLine(output, "Location: " + location);
Util.writeLine(output, "Connection: close");
Util.writeLine(output, "");
}
static void SendNotFoundResponse(OutputStream output,
String errorDocumentRoot)
throws Exception {
Util.writeLine(output, "HTTP/1.1 404 Not Found");
Util.writeLine(output, "Date: " + Util.getDateStringUtc());
Util.writeLine(output, "Server: Server05.java");
Util.writeLine(output, "Connection: close");
Util.writeLine(output, "Content-type: text/html");
Util.writeLine(output, "");
try (InputStream fis
= new BufferedInputStream(new FileInputStream(errorDocumentRoot
+ "/404.html"))) {
int ch;
while ((ch = fis.read()) != -1) {
output.write(ch);
}
}
}
}
見ての通り、301 Moved Permanentlyを返しています。
上で、kmaebsahi.comをClient01.javaで叩いて得たレスポンスでは、 301の場合もレスポンスボディを返しています。これについては、 RFC2616には、 「レスポンスのエンティティは新しい URI へのハイパーリンクを持った 短いハイパーテキストの注釈を含むべきである。」 と記載されているので本来返すべきなのでしょうが、 「べきである」レベルの規定なので今のところ放置しています。
Main.javaとUtil.javaには変更点はありません。
その他、細かい修正として、 レスポンスの出力およびレスポンスを返す祭のファイルの読み込みについて、 BufferedOutputStream/BufferedInputStreamをかませてバッファリングを 行うようにしました。 以前は「これ本当にローカルで動いてるのかよ」レベルの遅さでしたが、 これによりページの表示は圧倒的に高速化できました。
「落ち穂拾い」と称して足りない機能を追加しましたが、 まだ足りない機能はあります。たとえば現状、 ファイル名やディレクトリ名に空白が入ると、ブラウザからはURLエンコード (パーセントエンコード)されたパスが来ますがサーバが対応していないので 表示できません。また、「../」を含むパスが来ると、上位ディレクトリが 参照できてしまうので、ドキュメントルート外のファイルが参照できてしまいます。 これはディレクトリトラバーサル というセキュリティホールです。
次回以降、上記のような問題を直した上で、次はPOSTを実装し、 Webアプリケーションが作れるようにしていきたいと思います。