タイトルは「C言語 ポインタ完全制覇」。
このページの書籍化とはいえ、内容の大半は書き下ろしですので、 既にWebで読んでおられる方にも決して損はさせません。
詳細はこちらへどうぞ。
修正履歴は、このページの末尾にあります
全くもって僭越ながら、恐れおおくも偉そうにも、 こんな文書をWWWで公開させていただくことにしました。
この文書は、もともと社内向けの教科書として作成したものです。
私は、一介の文系出身プログラマであり、 特に情報関係の教育を受けたわけでもなく、 プログラミング言語に深い造詣を持っているわけではありません。 この文書にも多くの誤りや、誤解を招く表現があるかと思います。 そのような記述を見付けられた方は、ぜひ PXU00211@nifty.ne.jp 宛てに連絡願います。
C言語では、「ポインタが難しい」と良く言われますが、 実際に初心者がCを学習する過程を見ると、以下のことだけは すぐに理解しているようです。
「ポインタっつーのは、要するにアドレスのことなんだな」
ここまでは簡単、誰でもすぐに理解します。
# 大体、いつだって、低レベルな概念の方が理解が速いものです。 # アセンブラなんて、誰だってすぐに理解できますよね。 # それでまとまったプログラムを組むには別な才能が必要だ、 # というだけで。
問題はそこから先です。
結局、私自身の経験から言っても、 あるいは初心者がCの学習をするのを見ていても、 私は、以下のことは確信しています。
この辺について述べた書籍では、アスキーから出版されている 「エキスパートCプログラミング」が良書かと思います。 以下の文書も、この本の影響をかなり受けています。 しかし、頭が悪い私には、この本を繰り返し読んでも わからないところはやっぱりわからなかった。 結局、自分でCのサブセットのコンパイラを書いてみて、 始めて理解したことがいくつもあります。
そのような過程で理解したことを、私なりの文章で、 つまり、私があの時この説明を受けていれば、悩まなくて済んだのに、 という視点から書いてみました。
上級者の方が読めば、何だこんな当たり前のことを、 と思われるかも知れませんが、このレベルで引っかかっている Cプログラマは私の周りには大勢いたようです。
では、はじまりはじまり...
C言語は、現在広く使用されている言語である。しかし、Cは、 より良い言語を開発しようという目的の下に開発された言語ではなく、 UNIXを開発するために、いわば「いきあたりばったり」で 開発された言語である。ゆえに、ダーティな構文や、コンパイラの実装を 容易にするために手を抜いた部分が存在する。
本文では、そのような「Cの暗部」のうち、 「配列とポインタ」について述べる。
対象読者は、Cをそれなりに習得しており、かつ、 以下のような疑問を感じる人である。
このような点については、たいていの市販のCの参考書において、 記述されていないか、書いてあっても目立たないか、 著者が明らかに勘違いをしているかのどれかである。 Cのバイブルと呼ばれる「プログラミング言語C」(本文では以後K&Rと表記する。 ページ数等を付記する時は、第2版の日本語訳改訂版に従う)も例外ではない (というより、この本(の原書)が諸悪の根源かもしれない)。
Cの文法は、一見首尾一貫しているようで、実は数多くの例外が存在する。
本文は、上記の疑問に答え、Cの文法上の問題点を洗い出すことを目的とする。
Cの宣言の構文、とくに関数へのポインタを含む部分は 酷評を受けることがある。
---K&R P.148
K&R P.148には以下のような記述がある。
int *f(); /* f: intへのポインタを返す関数 */と
int (*pf)(); /* pf: intを返す関数へのポインタ */は、この問題のいい例である。ここで * は前置演算子であり、 () より低い優先度を持つから、正しい結合を行なわせるには カッコが必要なのである。
ちなみに、上記の文には嘘がある。 宣言の中の *, (), [] は演算子ではないし、優先順位も、 構文規則の中では演算子の優先順位とは別の箇所で定義されている。
これは、普通の日本人には、「逆じゃないか?」 と思えるのではないだろうか?
この疑問の答えは実は簡単である。C言語はアメリカで開発された 言語なのだから、英語で読めばよいのである。
Cの宣言を解釈するには、以下の手順に従う。ここでは問題を簡単に するため const は考えない(constを考えた版は、 こちらへどうぞ)。
| C言語 | 英語的表現 | 日本語的表現 |
| int a; | a is int | a は intである |
| int a[10]; | a is array(要素数10) of int | a は、intの配列(要素数10)である |
| int a[10][3]; | a is array(要素数10) of array(要素数3) of int | a は、intの配列(要素数3)の配列(要素数10)である |
| int *a[10]; | a is array(要素数10) of pointer to int | a は、intへのポインタの配列(要素数10)である。 |
| double (*a)[3]; | a is pointer to array(要素数3) of double | a は、doubleの配列(要素数3)へのポインタである |
| int func(int a); | func is function(引数は int a) returning int | funcは、intを返す関数(引数は int a)である |
| int (*func)(int a); | func is pointer to function(引数は int a) returning int | funcは、intを返す関数(引数は int a)へのポインタである |
# この辺のことは、K&R P.149に載っている dclの出力結果、お # よびそのソースを見ればよく理解できるのではないかと。
このように、Cの宣言は、(日本語・英語に関わらず)左から右に順に 読み進むことはできず、右に行ったり左に行ったりしなければならない。
K&Rによれば、Cの宣言は、「変数が現われ得る式の構文を真似た(P.114)」 そうである。しかし、本質的に全く異なるものを無理に似せようとしたため、 結局わけのわからない構文になってしまっている。 「宣言の形と使用時の形を似せる」というのはC(およびCから派生したC++, Javaなどの言語)に特有の「変な構文」である。
例えばPascalでは、Cにおける int a[10]; を以下のように書く。
var
a : array[0..9] of integer;
この構文であれば、左から右に、英語順で全く問題なく読める。
# Cの作者Dennis Ritchieが最近開発した新しい言語 Limboは、一見 # C like だが、宣言の構文はしっかりPascal風のものに直してある... # ずるい(^^; # switch caseも Ada風になって、fall throughじゃなくなってるし... # それにひきかえ、Javaときたら、なんで悪い所だけしっかり真似して # くれるんだか。どうせ互換性はかけらもないくせに。
他にも、「宣言の形と使用時の形を似せる」という方針のために、 宣言の中の * と式の中の * とでは意味が全く異なるにも関らず 同じ記号が使われている。前者はポインタを意味し、後者は間接参照を 行なう演算子である。
また、この宣言の読み方を見ればわかるように、 C言語には多次元配列は存在しない。 int a[10][10]; という宣言は、多次元配列ではなく、 「配列の配列」を意味する。
# Cの規格書では、脚注に「多次元配列」という言葉が最初に出現し、 # それ以後はちょこちょこ使われているから、「多次元配列は存在しない」 # という言い方はきつ過ぎるかも知れませんが、Cの宣言を理解するには、 # そう考えた方が得なのは間違いないと思います。
constは、ANSI-Cで追加された型修飾子であり、 型を修飾して「読み出し専用」であることを意味する。
その名前とは裏腹に、constは必ずしも 定数を意味するものではない。 constの最も重要な用途として、関数の引数があるが、 関数の引数が「定数」であるのなら、渡す価値がないことになってしまう。 constは、あくまで識別子(変数名)の型を修飾して、それが 「読み出し専用」であることを意味するだけである。
char *strcpy(char *dest, const char *src); /* const引数の代表例 */
さて、strcpyは、const指定された引数を持つ関数の代表例だが、 この時、何が「読み出し専用」なのか? 実験すればすぐに分かるが、上記の例では、srcという変数は、 読み出し専用にはなっていない。
char *
my_strcpy(char *dest, const char *src)
{
src = NULL; /* srcに代入しているのにコンパイルエラーにならない */
}
この時、読み出し専用になっているのは、「src」ではなく、 「srcが指す先にあるもの」である。
char *
my_strcpy(char *dest, const char *src)
{
*src = 'a'; /* エラー!! */
}
「src」そのものを読み出し専用にするのなら、
char *
my_strcpy(char *dest, char * const src)
{
src = NULL; /* エラー!! */
}
と書かなければならない。
「src」と、「srcの指す先にあるもの」の両方を読み出し専用にしたければ、 以下のように書く。
char *
my_strcpy(char *dest, const char * const src)
{
src = NULL; /* エラー!! */
*src = 'a'; /* エラー!! */
}
しかし、実際には、constは、引数がポインタである時に、 その「ポインタの指す先にあるもの」を読み出し専用にする用途で 用いられることが多い。
通常、Cの引数は全て値渡しである。よって、呼び出された側で、 引数をどんなに変更しても、それが呼び出し元に影響を与えることはない。 呼び出し元に影響を与えたい---関数から何らかの値を、引数を使って 返したい場合には、ポインタを渡す。
そして、上記の例(my_strcpy)では、srcというポインタを渡している。 これは、本当なら文字列、すなわちcharの配列を値渡ししたかった所だが、 Cでは配列は引数として渡せないので、やむを得ず先頭のポインタを 渡しているわけである(配列は巨大かもしれないので、 ポインタを渡すのは効率上も好ましい)。 問題は、これが、関数から値を返してもらう目的でポインタを渡すケースと まぎらわしいということである。
そこで、プロトタイプ宣言にconstを入れておけば、 「この関数は引数としてポインタを受け取るけれど、 その指す先は書き変えないよ」 つまり、 「ここではポインタを受け取っているけれど、呼び出し元に何らかの値を 返そうとしているわけではないよ」 ということを主張できる。 strcpyは、<string.h>の中で、「strcpyにとってsrcは入力であり、 その指す先は書き換えないよ」と主張しているのである。
# 関数の「ヘッダコメント」で、(i)とか(o)とか(i/o)とか印を付けている # プロジェクトを見たことがありますが、そんなことを人間系に頼るよりは、 # constを使うべきです。 ## 引数がconst char *の時、その引数は(そのままでは)constでない ## char *の変数に代入できません(警告が出る)。 ## ただ、キャストすると、代入できてしまいます。これは、呼び出され側の ## 契約違反であると言えます。
constを含む宣言の解読は、以下の規則に従えば良い。
よって、
char * const src
は、
src is read-only pointer to char → srcは、charへの、読み出し専用のポインタである。
となり、
const char *src
は、
src is pointer to read-only char → srcは、(読み出し専用のchar)へのポインタである。
となる。
そして、(まぎらわしいことに)
const char *src と char const *src
は、全く同じ意味である。
constは、引数に対してだけでなく、グローバル変数やstatic変数に 対しても用いられる。この場合、その値は、読み出し専用の領域に 配置される可能性がある。 さらに、プログラム中で&などでポインタを取得しなければ、 領域が確保されない(つまり、#defineと同じように定数として働く) 可能性もある(処理系による)。
補足: typedefについて
K&Rの付録には、BNFに近い文法で記述されたCの文法の要約がある。 これを見ると、typedef は、以下のように定義されている(P.295)。
storage-class-specifier one of
auto register static extern typedef
typedef が storage-class-specifier(記憶クラス指定子)で、 auto や register や staticや externと同等だというのは、 普通に考えれば理解しがたい。 これは、typedef がCにとって後から追加されたものであり、 その時に新しい構文規則を追加するのを嫌って便宜的に記憶クラス 指定子に押し込んだためであるであると思われる。
typedef 宣言は、通常の識別子の宣言と同様の順序で読む。 構文自体は宣言なので、ひとつの宣言文で複数の識別子が宣言できるのと同様、 一度に複数の型名を宣言することも可能である。
| C言語 | typedef double Point[2], (*Polyline)[2]; | |
|---|---|---|
| 英語的表現 | Point is array(要素数2) of double | |
| Polyline is pointer to array(要素数2) of double | ||
| 日本語的表現 | Point は double の配列(要素数2)である | |
| Polyline は、double の配列(要素数2)へのポインタである | ||
本章では、主に以下の点について述べる。
式の中では、配列は「先頭要素へのポインタ」に 読み換えられる。
int a[10];
の時、式の中では、a と &a[0]は同じ意味となる。
ただし、以下の個所は例外である。
単項演算子 * を、間接参照演算子と呼ぶ。
* は、ポインタをオペランドとして取り、その指し示すオブジェクト または関数を返す。 その型は、オペランドの型からポインタをひとつ剥がした型となる。
| 宣言 | aの型 | *aの型 |
| int *a; | a は、int へのポインタ | *a は、int |
単項演算子 & を、アドレス演算子と呼ぶ。
& は、左辺値をオペランドとして取り、そのアドレスを値とする。 その型は、オペランドの型にポインタをひとつ付け加えた型となる。
| 宣言 | aの型 | &aの型 |
| int a; | aは、int | &aは、intへのポインタ |
左辺値を持たない式をオペランドとして取ることはできない。
後置演算子 [] を、添字演算子と呼ぶ。
[]は、ポインタと整数をオペランドとして取る。
以下のふたつの式は、全く同等である。
p[i] *(p+i)
ポインタへの 1 加算は、「そのポインタが指すオブジェクトのサイズだけ アドレスを進める」ことを意味する。
int a[10]; のように宣言した配列を a[i] のようにして アクセスする場合、a は式の中なので、ポインタに読み換えられている。 そのため(ポインタと整数をオペランドとして取る)添字演算子で アクセスできるのであり、文法上は、演算子[]は配列とは全く無関係である。 p[i] は、*(p+i) の簡略記法(構文糖 --- syntax sugar)に過ぎない。
Cには、文法上多次元配列はないが、 配列の配列を使用することにより多次元配列が実現できる。
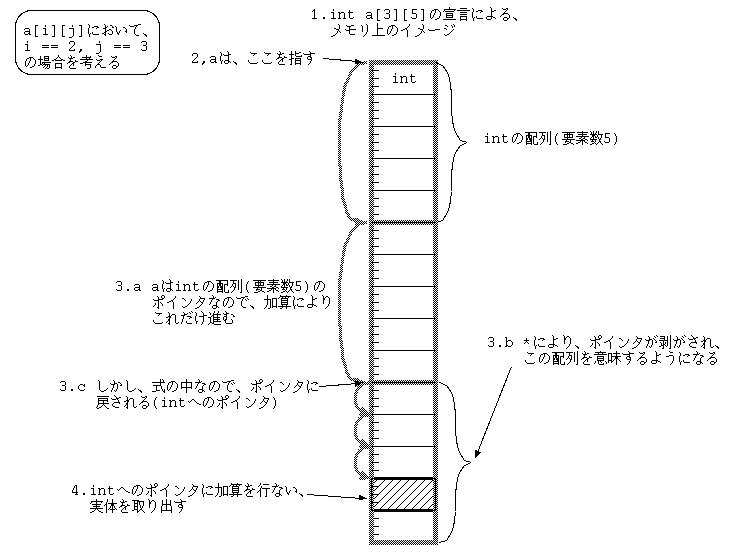
int a[3][5];
のとき、
式の中の
a[i][j]
を考えると、
Cには、数多くの演算子があり、しかもその優先順位が15段階もある。 これは、他言語と比べて極端に多いため、Cの参考書には、以下のような 演算子の優先順位表がたいてい記載されている。
| 演算子 | 結合規則 |
| () [] -> . | 左から右 |
| ! ~ ++ -- + - * & (type) sizeof | 右から左 |
| * / % | 左から右 |
| + - | 左から右 |
| << >> | 左から右 |
| < <= > >= | 左から右 |
| == != | 左から右 |
| & | 左から右 |
| ^ | 左から右 |
| | | 左から右 |
| && | 左から右 |
| || | 左から右 |
| ?: | 右から左 |
| = += *= /= %= &= ^= |= <<= >>= | 右から左 |
| , | 左から右 |
この中で、優先順位が「最強」である ()について、
()は、プログラマが、文法で規定された優先順位を無視して 強制的に優先順位を設定する時に使用する括弧だ。だから、 これの優先順位が最強なのは当然だ。
と考えている人は意外に多いが、それは 間違いである。 もし、この ()がそのような意味なら、わざわざ優先順位表に載せる 必要はないはずである。
この表の() は、(K&Rにもあるように)関数呼出しを意味する 演算子であり、この場合の優先順位とは func(a, b) のような 関数呼出しにおいて、func と (a, b) との間の結び付きの強さを表現している。 Cでは、「関数へのポインタ」という型があり、以下のような記述が可能なので、 このような優先順位が必要なのである。
/* func_p_pが、関数へのポインタのポインタであったとして、 */
(*func_p_p)(); /* 関数へのポインタのポインタから、
ポインタをひとつたぐり寄せて関数呼出し */
*func_p_p(); /* こうすると、func_p_p に対して()を適用し、
その戻り値に*を適用するという意味になってしまう */
同様に、[]の優先順位は、a[i] の場合、a と [i] の間の 結び付きの強さを意味する。
ところで、私は、優先順位が15段階あること自体は 悪いことだとは思わないが、 いくつかの演算子の優先順位が「間違っている」のは問題である。 特に問題なのは、ビット演算子(& |)演算子が比較 演算子(== != など)に比べて優先順位が低いことである。 これは、歴史的な理由によるそうである。
# でも、Limboでも、直ってないような... 見掛けが似てるのに細 # かい所をこっそり直すと問題が大きいからかなあ。補足:ポインタは配列より高速か?
Cには、ポインタに対し直接演算を行なうという、(他に類を見ない)機能がある。 この機能により、他言語であれば配列の添字で行なうような作業を ポインタ演算で代用できるが、ほとんどの人にとって添字で記述する方が 理解しやすい。にも関らず、ポインタ演算を使用する根拠として挙げられるのが、 K&R P.119の「ポインタを使う方が一般に高速である」という記述である。
結論から先に言えば、現行のたいていのCコンパイラについて、 これは嘘である。
最適化を全く考えない処理系であれば、配列を使用した場合、 確かに効率は悪くなる。下記のようなプログラムについて、 array[i] を参照する度に、機械語レベルで array + i * (1要素のサイズ) という演算を行なっていたとすれば、遅くなって当然である。
for (i = 0; i < LOOP_MAX; i++) {
/* array[i]を使った色々な処理。array[i]は、何度も出現する。 */
}
これに対し、以下のようにポインタを使用したプログラムでは、 ループの末尾以外、p を何度参照しても、加算を行なう必要はない。
for (p = 初期値; ループ継続条件; p++) {
/* pを使った色々な処理。pは、何度も出現する。 */
}
これが、K&Rの「ポインタを使う方が一般に高速である」という記述の 根拠であると思われる。
しかし、ループの中の共通部分式の括り出しという作業は、 コンパイラの最適化の基本である。現在の通常のコンパイラであれば、 配列・ポインタのいずれを使用しても、ほとんどの場合全く同じコードを出力する。 この場合、効率に差が出ることはあり得ない。 また、仮に異なるコードを生成していたとしても、 その差はたいしたものではない。
これは推測であるが、Cに「ポインタ演算」という「妙な」機能が 存在する理由は、単にDennis Ritchieが最初の処理系を作成する際に、 手を抜いて最適化の機能を組み込まなかったためではないかと思われる。
CはもともとUNIXを記述するために、かつ自分達で使うためだけに 開発された言語であるから、コンパイラに最適化ルーチンを組み込むより先に、 とにかく高速なコードが書ける機能が必要だったのではないか。 UNIX以前にはOSはたいていアセンブラで書いていたことを考えれば、 多少の読み難さは問題にはならなかったに違いない。
記憶クラス指定子 registerも、「本来コンパイラが行なうべき最適化を プログラマに押し付けた」例であると言える。
Cでは、以下の場合、要素数を省略した[] を書くことができる。
以下のケースは全て、コンパイラによって特別に解釈されている。 これらの規則が一般に適用できると思わないこと。
関数の仮引数では、最外周の配列に限りポインタに読み変えられる。 要素数は書いても書かなくても良い(書いても無視される)。
void func(int *a)
{
}
と
void func(int a[])
{
}
は全く同一である。引数 a は、配列に見えるが、実は単なるポインタの 宣言である(a++などの操作も可能である)。要素数は書いても無視されるので、 a[] と書いても、a[10] と書いても、a[100]と書いても全く同一の意味となる。
Cの文法中で、配列の「宣言」がポインタに読み換えられるのは、 唯一このケースだけである。つまり、int *a と int a[] が同一の意味となるのは、 「関数の仮引数」という限られたケースにおいてのみである。
#'99 6/23追記... # この部分、以前までは「関数定義の仮引数」と書いてました。 # でも、ある人から、「関数の宣言の場合でも同じではないか」というご指摘を # 受けました。 # 確かにその通りです。そういえば、関数へのポインタにキャストする時のキャスト # の中でもそうです。 # というわけで、「関数の仮引数の定義」と改めました # ...ら、今度はまた別の方から、「関数宣言の場合、仮引数は定義ではなく # 宣言ではないか」という御指摘を受けました。 # お詫びして修正いたします。
関数定義の仮引数としては
char s[];
および
char *s;
はまったく同一である。われわれは後者がよいと思うが、それはこのほうが引数が ポインタであることをより明確に示しているからである。
--- K&R P.121
アーグググググググ! アーグブイ! アーグシー! K&R第2版から、 この部分だけは破り捨ててしまえ! これが通用するのは、 関数定義の引数定義という特殊な状況だけだという点を 読み飛ばす危険が高すぎる...
---エキスパートCプログラミング P.238
---それにしても、後者の書き方の方がいいなら、なんで引数の時に限り
配列の宣言がポインタに読み換えられるなんていう変な規則
を入れたんだ?
---よく考えたら、上記のふたつの宣言で、後ろにセミコロンが付いてるのは
何なんだろうね。ANSI-Cの関数定義では、
仮引数の後ろには、セミコロンは付かんと思うんだけど。
ここだけ昔のCか?
念のため、原書も確認したけど、やっぱりセミコロンが付いてるんだよなあ。
int a[] = {1, 2, 3, 4, 5};
char str[] = "abc";
double matrix[][2] = {{1, 0}, {0, 1}};
char *color_name[] = {
"red",
"green",
"blue"
};
char color_name[][6] = {
"red",
"green",
"blue"
};
配列の配列を初期化する場合、一見、初期化子を見れば最外周でなくても コンパイラが要素数を確定できるように見える。しかし、Cでは、 以下のような不揃いの配列初期化が許されているため、最外周以外の 要素数は簡単には確定できない。
int a[][3] = { /* int a[3][3]の省略形 */
{1, 2, 3},
{4, 5},
{6}
};
char str[][5] = { /* char str[3][5]の省略形*/
"hoge",
"hog",
"ho",
};
最大数を取れば良いようにも思えるが、Cの文法はそうなっていない。 その目的がプログラマのミスを検出することなら、「不揃いの配列」 全てをエラーにすべきであるが、そうでもない。 何故こうなっているのか、私には今ひとつ理解できない(単なる手抜き?)。
ちなみに、上記のような不揃いの配列初期化を行なうと、対応する 初期化子のない要素は0で初期化される。
file_1.c: int a[100]; file_2.c: extern int *a;
" で囲まれた文字列を、文字列リテラルと呼ぶ。
通常は、文字列リテラルは、「char の配列」を意味する。 よって、式の中では「charへのポインタ」に読み換えられる。
しかし、char の配列を初期化する場合は例外である。 (こちらを参照のこと) この場合の文字列リテラルは、中括弧内に文字を区切って書く初期化子の 省略形として、コンパイラに特別に解釈される。
char str[] = "abc"; /* この宣言は、下の宣言と同義 */
char str[] = {'a', 'b', 'c', '\0'};
/* 配列の最外周なので、要素数は省略できる */
次の例は、char の配列ではなく ポインタを初期化しているので、 上記の例外には当てはまらない。
char *str = "abc";
より複雑な宣言の場合も、識別子の宣言と初期化子の中括弧の対応を 順に見ていけば、解釈できる。
char *color[] = { /* 文字列リテラルは、「charへのポインタ」に対応 */
"red",
"blue",
"green"
};
char color2[][6] = {/* 文字列リテラルは、「charの配列」に対応 */
"red",
"blue",
"green"
};
文字列リテラルは、通常は書き込み禁止の領域に確保される (正確には実装依存)。しかし、char の配列を初期化している場合は、 単に中括弧内に文字を区切って書く初期化子の省略形に過ぎないので、 配列自体に const 指定がない限り書き込みが可能である。
キャスト演算子では、() の中に型名を入れる。この型名は、 宣言から識別子名を抜くことで機械的に作成できる。
| 宣言 | 宣言の意味 | キャスト | キャストの意味 |
| int a; | aはint | (int) | intに型変換するキャスト |
| int *a; | a はintへのポインタ | (int*) | intへのポインタに型変換するキャスト |
| double (*p)[3]; | pは、doubleの配列(要素数3)へのポインタ | (double (*)[3]) | doubleの配列(要素数3)へのポインタに型変換するキャスト |
| void (*func)(); | funcは、voidを返す関数へのポインタ | (void (*)()) | voidを返す関数へのポインタに型変換するキャスト |
最後のふたつの例のアスタリスクを囲む括弧 (*) は一見無駄に 見えるが、これを無くすと意味が変わってしまう。
(double *[3]) は double *p[3] から識別子名を抜くと 作成できるので、このキャストは「double へのポインタの配列」への キャストという意味になってしまう。
Cでは、関数名を() を付けずに書くことにより、関数へのポインタを意味する。 これは、シグナルのハンドラや、event-drivenプログラムでの コールバック関数で頻繁に使用される。
/* SIGSEGV(Segmentation falut)が発生した場合、
関数segv_handlerがコールされるように設定する */
signal(SIGSEGV, segv_handler);
通常は、この書き方を使用すると思われる。
しかし、Cの宣言をここまでに述べた規則に基いて解釈すれば、 例えば int func(); という宣言において func は、 「int を返す関数」であり、func だけを取り出して「intを返す関数へのポインタ」に なるのは変である。関数へのポインタが必要なら、& を付けて & func としなければならない。そこで、上記のシグナルハンドラの設定を、
signal(SIGSEGV, &segv_handler);
と書いても、実は全く問題なく動作する。
逆に、
void (*func_p)();
のように、関数へのポインタとして宣言された func_p を使用して 関数呼出しを行なう時には、多くの場合
func_p();
のように書く(と思う)が、int func(); と宣言した func について func() のように呼出しを行なうことを考えれば、対称性から言って、 以下のように記述しなければならない。
(*func_p)();
これもまた、全く問題なく動作する。
このように、関数へのポインタについてのCの文法は混乱している。 この混乱の原因は、「関数名を() を付けずに書くことにより、 関数へのポインタを意味する」という、意図のよくわからない (配列と同じようにしたかった?)規則である。
これをカバーするため、ANSI規格では以下のように文法に例外を設けている。
「関数へのポインタ」に対し、間接参照演算子 * を適用すると、 一旦「関数」になるが、式の中なので即座に「関数へのポインタ」に変換される。 結果として、* 演算子を「関数へのポインタ」に適用しても、 何もしない(ように見える)。
このため、以下のような記述も全く問題なく動作する。
(**********printf)("hello world!\n"); /* どうせ*は何もしない */
補足:externについて
Cでグローバル変数を使用する場合、単純にヘッダファイルで、
int global_variable;
のように宣言し、それを使用する(複数の) .c ファイルで #include している例は多い。
しかし、本来は、グローバル変数は、プログラム全体のどこか一箇所で 定義し、残りの個所では extern すべきである。
とはいうものの、現状の(UNIXの)Cの処理系の大半は、 グローバル変数の定義が複数の個所で行なわれていても、 何の警告も発しない。 これは、Cの処理系の欠陥である。extern を付けない 変数定義が複数の個所で行なわれていたら、 リンクの段階で multiple define(多重定義)エラーを出すべきである。
大規模なプログラムの開発は、複数の人間により行なわれる。そのような状況で、 たまたまグローバル変数の名前がバッティングした場合、 現状のUNIXの処理系では何の警告も発しない。結果として、 「グローバル変数の値がいつの間にか破壊されている」という、 極めてたちの悪いタイプのバグに悩まされることになる。
もちろん、グローバル変数には命名規則を適用するのが当然であるが、 機械的な重複チェックは人間系に頼るよりも機械が行なうべきである。
付け加えると、現実のプロジェクトでは、 関数名には命名規則を適用していながら、グローバル変数には無頓着、 という変なプロジェクトも多い。 関数に命名規則を適用するのは良いことだと思うが、 関数名のバッティングはリンクの段階でエラーにされるため、 危険度はグローバル変数の方が上である。
extern のない宣言がプログラム全体で複数個所あった場合、 リンカがエラーにしてくれれば、このような問題は発生しなくなる。 Cは、文法上は、いかにもこのような点を考慮しているように見えるが、 現実の処理系はほとんど対応していない。これは単に過去の処理系が 多重定義エラーを出さなかったため、後方互換性を維持するために エラーにできないだけであると思われる(推測)。
ちなみに、C++では、この欠点は解消されており、extern のない 変数の定義が複数の個所で行なわれるとエラーになる。 これはつまり、C++がCの上位互換でないことを意味する。
C++は、この点だけではなく、いろいろな意味でCの上位互換ではないが、 Cのソースをそのままコンパイルしても動くように誤解している人が (意外に---特に管理職には)多いようなので敢えてここに記述した。
なお、グローバル変数の定義は一箇所で行ない、 残りの個所では extern するといっても、 そのためにわざわざ同一の記述を複数の個所で行なうのは間違いのもとである。 この問題は、以下のようにマクロを使用することで解決できる。
#ifdef GLOBAL_VARIABLE_DEFINE #define GLOBAL /* "無"をdefine */ #else #define GLOBAL extern #endif GLOBAL int global_variable;
ヘッダファイルにこのように記述した上で、プログラムのどこか一箇所で GLOBAL_VARIABLE_DEFINE を #define して #include すれば、 自動的に定義は一箇所で残りの個所は extern になる。
Leptonさんのページで紹介されてしまった (といっても、こちらからメイルを書いたのですが)結果、 このページを読んだ方から非常に詳細な訂正をいただきましたので、 反映致しました。
> * こうして、「ポインタは難しい」という伝説が蔓延する。 /UL>
→タグミスを修正
> 3. 派生型を解釈したら、それを"of"または"to"または"returns"で
→K&Rに合わせて、returningに修正。
# returnsはどっから出てきたんだろう? > 自分
→「~のポインタ」「~の関数」を、「~へのポインタ」「~を返す関数」に統一。
> constは、ANSI-Cで追加された型修飾子であり、識別子の型を修飾し、
→キャストや関数宣言の引数を考えると、識別子は常にあるとは限らないので、
「識別子の型」→「型」に修正
> * は、ポインタをオペランドとして取り、その指し示す内容を値とする。
→左辺値を返すこともあるので、「値」を「オブジェクトまたは関数」に修正。
> ! ~ ++ -- + - * ^ (type) sizeof 右から左
→ ^ を & に修正(typo)
> Cでは、「関数のポインタ」という型があり、以下のような記述が可能
> なので、 このような優先順位が必要なのである。
>
> dispatch_table[index](); /* テーブルによる関数のディスパッチ */
> determin_function(a)(); /* 関数のポインタを返す関数 */
→この場合、()や[]は後置演算子であり、結合規則とは無関係に左からしか
結合できないわけで、例として不適切なので、訂正。これについては私自身
完璧に思い違いをしていたようです。
> # というわけで、「関数の仮引数の定義」と改めました。
→「関数の仮引数の宣言」に修正。
> 1. 関数名は、式の中では「関数のポインタ」に自動的に変換される。
> ただし、アドレス演算子 & のオペランドである時は例外である。
→sizeof演算子のオペランドの場合も例外なので、カッコ付きで追加。
> 3. 間接参照演算子 * は、そのオペランドが「関数のポインタ」であ
> る場合に限り、 何もしない。
→削除。* は、「関数指示子」を返すので、その型は「関数」であり、
式の中なので即刻「関数へのポインタ」に読み換えられて、何もしない
ように見えるだけですね。