「プログラミング言語を作る」正誤表
このページは、拙著「プログラミング言語を作る」技術評論社 ISBN978-4-7741-3895-4 の正誤表です。
プログラムソースについては本に載っていない部分もありますので、 こちらに掲載します。
p.18側注
誤)
そのようなノウハウの蓄積ない時点で
正)
そのようなノウハウの蓄積がない時点で
p.21上から3行目
誤)
可般性があるともいえます
正)
可搬性があるともいえます
p.28「1. Cコンパイラ」の4行目
誤)
MinGW(Minimalistic GNU for Windows)
正)
MinGW(Minimalist GNU for Windows)
公式サイトによると正式名称は こちらのようです……
p.33図2-2の6行目
誤)
「Compiler Complier」というのは
正)
「Compiler Compiler」というのは
また、 公式っぽいページによれば、正しくはCompiler-Compilerのように ハイフンを入れるようです。
p.43~44下から3行目から
「もし、演算子の優先順位(掛け算は足し算よりも先にやる)を考慮しなくてよいのなら、上記の構文規則は以下のようになります」とありますが、ここにある構文規則だとyaccがshift/reduce conflictを出し、かつ、結合規則が右から順になります。よって、「1-2-3-4」の結果は、-8ではなく-2になります。
この規則は、「優先順位を考えるとtermとかを導入しなければいけなくて難しいので、ひとまず考えなければこう書ける」というサンプルなのですが、結合規則まで考慮しないとは書いていないこと、yaccが警告を出すのはそれ自体いかがなものかと思いますので、ここで補足します。
以下の掲示板の議論も参照してください。
http://kmaebashi.com/bbs/list.php?boardid=kmaebashibbs&thread=1509
p.58lexicalanalyzer.c
このレキシカルアナライザは、改行なしで行が終わってしまうと 「BAD_TOKEN」というトークンを返すのですが、末尾のテストドライバは BAD_TOKENを解釈しないので、再度get_token()を呼び出して 無限ループに入ります。
改行なしの行を食わせるためにはファイルからリダイレクト等しなければ ならないのでまず問題にはならないと思うのですが、補足しておきます。
p.61側注
誤)
LexicalAnalyserStatusであるべきかもしれませんが
正)
LexicalAnalyzerStatusであるべきかもしれませんが
どちらも正しいようですが、他の箇所ではanalyzerなので。
p.68parser.cの28行目
parse_expression()のプロトタイプ宣言が入っています。
以後の改良でparse_expression()をparse_primary_expression() から呼ぶようになるのですが、そちらのソースを先に書いてから 機能を削ったところ痕跡が残ったようです。
もちろんあって問題があるわけではないですが、 混乱の元かと思いますので挙げておきます。
p.70parser.cの89~90行目
このelse節に来る前に、token.kindがADD_OPERATOR_TOKENまたは SUB_OPERATOR_TOKENであることは79~80行目のif文で保証されているので、 ここは通りません。
p.74 7行目以降
lexで「(」と「)」のトークンを追加するため、以下のように記載していますが、
"(" return LP; ←追加
")" return RP; ←追加
ここのコンパイルを通すためには、 mycalc.y側で、LPとRPのトークンを宣言しておく必要があります。
p.40のmycalc.yの11行目が該当箇所になります。
11: %token ADD SUB MUL DIV CR LP RP
p.75parse_primary_expression() 18~20行目
primary_expression()で数値か「(」以外のトークンがきたとき、 unget_token()していますが、ここはエラーにすべきところです。
p.77parse_primary_expression() 25~27行目
primary_expression()で数値か「(」以外のトークンがきたとき、 unget_token()していますが、ここはエラーにすべきところです。
p.106上の囲みリストの下3行目
誤)
アクションにて、crb_crete_binary_expression()…
正)
アクションにて、crb_create_binary_expression()…
「a」が抜けていました。
p.146 6~7行目
誤)
a = {1, 2, 3};
a = {2, 3, 4};
正)
a = {1, 2, 3};
a = {4, 5, 6};
コード片と図が食い違っています。図のほうに合わせます。
「4-4-5 ネイティブポインタ型の改修」ですが、この改修が入っているのは book_ver.0.2ではなく、0.4からです。
「プログラミング言語を作る」は、もともとWeb上の連載で、 いろいろ試行錯誤しながら作っておりました。 書籍化にあたり、後になって失敗したと思い改修した箇所を、 前のバージョンに取り込む作業をしており、この件も、 ver.0.4からver.0.2に移動させたつもりだったのですが、 勘違いをしていたようです。申しわけありません。
p.17815行目
誤)
mbstate_をmemset()等でゼロクリアしたものを
正)
mbstate_tをmemset()等でゼロクリアしたものを
p.186下のリスト
誤)
/* ソースがShift-JISで、その1文字目を食ったのであれば、
SHIFT_JIS_2ND_CHARに遷移する */
if (enc == SHIFT_JIS_ENCODING
&& ((unsigned char*)yytext)[0] >= 0x81
&& ((unsigned char*)yytext)[0] <= 0x9e) {
正)
/* ソースがShift-JISで、その1文字目を食ったのであれば、
SHIFT_JIS_2ND_CHARに遷移する */
if (enc == SHIFT_JIS_ENCODING
&& ((((unsigned char*)yytext)[0] >= 0x81
&& ((unsigned char*)yytext)[0] <= 0x9e)
|| (((unsigned char*)yytext)[0] >= 0xe0
&& ((unsigned char*)yytext)[0] <= 0xef))) {
本文中にもあるとおり、Shift-JISの文字コードは
と定められていますが、2バイト目の範囲の後半部分が抜けていました。
p.189下から6行目
誤)
それに対し、CSIだと(N-1)必要になります。
正)
それに対し、CSIだとN(N-1)必要になります。
p.206ふたつめのカコミのリスト
誤)
$$ = dkc_close_block($<block>2, $3);
正)
$<block>$ = dkc_close_block($<block>2, $3);
代入される側の$$も型指定をしないと、 環境によりエラーが出るようです。 掲示板の以下の投稿も参照してください。
http://kmaebashi.com/bbs/list.php?boardid=kmaebashibbs&thread=1430
私のところでは$$の型指定をしなくても (なぜか)動いているようですが、これは指定するのが正しいと思います。
p.281図8-5
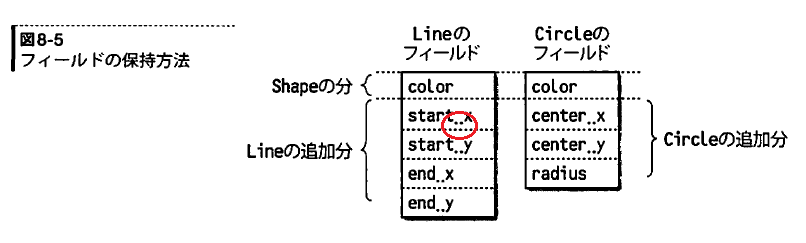
start_xであるべきところがstart..xになってしまっています。 start_y等も同様です。
p.282図8-6

p.281と同様です。
p.303補足の2行目
誤)
具体的には、オブジェクト消滅のタイミングで、Javaならデストラクタ、 C++やC#ならデストラクタというメソッドが呼び出されます。
正)
具体的には、オブジェクト消滅のタイミングで、Javaならファイナライザ、 C++やC#ならデストラクタというメソッドが呼び出されます。
p.417下から3行目
誤)
ラルフ・ジョンション
正)
ラルフ・ジョンソン
書籍情報のページに戻る | 著者のWebページトップはこちら
ご意見、ご質問、不具合連絡等は掲示板にお願いいたします。