新しいプログラミング言語を作る動機として考えられるのは、 以下のようなものでしょうか。
わざわざ新言語を作る動機としては、 これが一番「まっとう」なのだろうとは思います。
ただ、現実問題、CとかJavaとかPerlといった広く使われている言語に対し、 たとえ喧嘩を売ったところで、ほぼ勝敗は見えていると言ってよいでしょう。
プログラミング言語そのものの処理系を作ることは、さほど難しくはありません。 しかし、実行速度にこだわるなら、最適化にはかなりの技術が必要です。 また、スクリプト言語の類いなら実行速度にはこだわらないと思いますが、 そういう言語の強力さなんて 8割方ライブラリの量で決まると私は思います。 なぜみんなPerlやPHPやHSPを使うのかといえば、 文字列処理やWebアプリケーションや Windowsプログラミングに便利な機能やライブラリが、 最初から組み込まれている、という面がかなり大きいはずです。 今から新しい言語を作っても、 ライブラリの類いを充実させるには時間がかかるでしょうから、 追いつくのは困難です。
プログラミング言語の言語仕様について何か独自のアイディアがあって、 それを実際に作ってみたい、という人もいるかもしれません。
アイディアがあるのなら、実際にそれを実装してみるのはよいことだと思います。 そのアイディアが本当に実現可能かどうか、 本当に優れたものかどうかの検証になりますし、 他人に見せる際にも便利でしょう。
が、プログラミング言語ってのは、 斬新な機能を組み込めば組み込むほど普及しないってのも、 一面の真理ではありますよね。 たいていの人は 「自分が慣れている言語に似た言語」を使いたがるものです。
もちろん、アイディアの検証が目的なら、 特に人に使ってもらう必要はないかもしれませんが、 ひとりだけで使っているのでは、やっぱりちょっと寂しい気がします。 少なくとも私は。
エディタやCADなどでは、スクリプト言語を使って、 ユーザ独自の機能を組み込めるものがあります。 そういった、アプリケーションの組み込み用言語を作りたい、 というのが、実用的な意味合いとしては一番大きいかもしれません。
もちろん、そういう場合も既存の言語を使うことは可能です。 そのアプリケーションがCで書かれていたとして、 PerlやRubyなどは、Cから呼ぶことも、Cで書かれた関数を呼ぶこともできます。
ただ、自分で作ったアプリケーションであれば、 自分で作った言語を組み込むのが、 ライセンス等の都合から言っても気楽でよいかもしれません ※1。
とまあ、いくつか動機を挙げましたが、最終的には、動機なんてのは、
とにかく作ってみたい!
で充分なんじゃないかと思います。
プログラミング言語といえば、プログラマが毎日使う道具です。
同じように毎日使う道具である「エディタ」を作りたがる人が大勢いるように、 プログラミング言語も、 多くのプログラマが作ってみたいと思うものなんじゃないかと思います。
実際、そうしてたくさんの「俺言語」が作り出されています。
プログラマなら誰でも知っているように、プログラミング言語には、 コンパイラ方式の言語と、インタプリタ方式の言語とがあります。
コンパイラ方式の言語といえば、CやC++などが挙げられます。 これらの言語は、プログラマの書いたソースコードから、 最終的には機械語の実行形式を出力します。
が、ここで作る「俺言語」としては、 機械語を吐くコンパイラはちょっと不適当なように思います。 機械語を吐くためには、そもそも機械語を知らなければなりませんし、 機械語を勉強してコンパイラを書いたとしても、 そのコンパイラは、別のCPU用の実行形式を吐くことはできません。 機械語を生成するタイプの言語の利点は、実行が高速だということですが、 どっちみち今時のコンパイラの最適化技術に追い付くのは大変です。 また、言語を作る動機として 「アプリケーションの組み込み言語が欲しい」 というものを挙げましたが、 機械語を吐くコンパイラはこういう用途には不向きです。
というわけで、ここでは、インタプリタ型の言語を対象にしようと思うのですが、 ひとことで「インタプリタ型の言語」と言っても、 その実行の方法には、いくつか種類があります。
このあたりのことは「 センス・オブ・プログラミング」にも書いたので、 そっちを見てください――と言いたいところですが、まあ軽く。
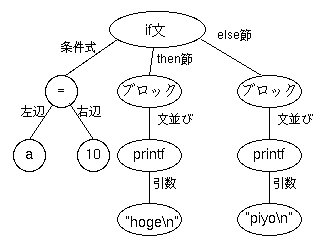
たとえば、以下のようなソースがあったとします。
if (a == 10) {
printf("hoge\n");
} else {
printf("piyo\n");
}
ソースプログラムは、そのまま見れば単なる文字の並びですが、 それでは実行しにくいので、現在のたいていの言語は、ソースを 解析木(parse tree)というものに変換します (構文解析木または構文木と呼ばれることもあります)。 上のソースの解析木は、たとえば下図のようになります。
Perl、Rubyなどでは、まず、ソースファイルを解析木に変換し、 以後はこの解析木をもとに実行を行ないます。
それに対し、Javaなどでは、この解析木をもとにバイトコードを生成し、 インタプリタはバイトコードを実行します。 バイトコード自体は単なる数字の並びですが、 人間にとって多少なりともわかりやすくするために、 各命令にはニモニックという文字列表現が与えられており、 それを使って上記のソースを表現するとこんな感じになります (上記のソースのprintfをSystem.out.printlnに変えてjavapで出力)。
0: bipush 10 2: istore_1 3: iload_1 4: bipush 10 6: if_icmpne 20 9: getstatic 12: ldc 14: invokevirtual 17: goto 28 20: getstatic 23: ldc 25: invokevirtual
さて、これから作る言語でどちらを採用するかですが、 ひとまずは、PerlやRubyのような、解析木を実行するタイプの言語にします。
いやその、実のところ私としては、 いずれバイトコードを実行するタイプの言語を作りたいと思ってはいるのですが、 そういう言語を作るにも、どうせ解析木は作らなければならないわけですし、 それなら、ひとまずは解析木を実行するタイプの言語を動かしてみようかと。
さて、今回作る言語は解析木実行型のインタプリタで作ることにしよう、 と決まりました。では、その言語の処理系(コンパイラとインタプリタ)は、 どんなプログラミング言語で作ればよいでしょうか。
インタプリタ型の言語は実行が遅いので、 インタプリタそのものを書くのに遅い言語を使うと、 その上で動く「俺言語」はさらに遅くなってしまいます。 そこで、それなりの処理速度が出る言語として思いつくのは、 C, C++, Java程度です。
また、ソースから解析木を作るプログラムのことを「パーサ」 と呼びますが、 CやJavaでは、パーサをある程度自動生成してくれるプログラムが存在します。 有名なのは、Cではyacc, JavaではJavaCCです。 これらを使わずパーサを手書きするのは、勉強にはなるのかもしれませんが、 正直、私はやる気になれません ※2。
んで、私はまだJavaCCをちゃんと使ったことがないので、 それを試すためにもJavaにしようかとも思ったのですが、 一応動機のひとつとしては「アプリケーションの組み込み言語が欲しい」 というのがあったはずで、 でももしそのアプリケーションがJavaで書かれているのなら、 組み込み言語だってJavaを使えばよい話です ※3。
そう考えると、Cで作るのが一番応用範囲が広いかなあ、ということで、 ここではCで作ることにしました。