crowbar ver.0.1では配列が使えませんが、 いくらなんでもこれでは実用に耐えないので、 配列を導入することにします。
crowbar ver.0.2では、以下のような形で配列が使えるようになりました。
# 配列の生成
a = {1, 2, 3, 4, 5, 6, 7, 8};
# 配列の表示
for (i = 0; i < a.size(); i++) {
print("(" + a[i] + ")");
}
print("\n");
# 掛け算九九の表の生成
a99 = new_array(9, 9);
for (i = 0; i < 9; i++) {
for (j = 0; j < 9; j++) {
a99[i][j] = (i+1) * (j+1);
}
}
# 掛け算九九の表の表示
for (i = 0; i < a99.size(); i = i + 1) {
for (j = 0; j < a99[i].size(); j = j + 1) {
print("[" + a99[i][j] + "] ");
}
print("\n");
}
# おまけ:文字列の長さ
print("len.." + "abc".length() + "\n");
GLOBALをかましたソースは こちらから参照可能です。
ダウンロードは、UNIX版がこちら、 Windows版がこちら。
Cではできませんが、たいていのスクリプト系の言語では、 配列(またはリスト)のリテラルを記述することができます。
たとえばPerlなら、
(1, 2, 3)
と書けば1, 2, 3を要素とする配列(リスト)が生成されます。
RubyやPythonならこうです。
[1, 2, 3]
Tclはこう。
{1, 2, 3}
言語ごとに記号が違って眩暈がしてきますが、 crowbarはどことなくCに似た言語ですし、 Cでは配列の初期化子で{}を使うので、crowbarでは{}を使うことにしました。
{1, 2, 3}
と記述することで配列が生成されます。当然これは
a = {1, 2, 3};
として変数に代入することもできますし、 (そう書きたければ)以下のように直接添字を指定することもできます。
{1, 2, 3}[1]
この式全体の値は、整数型の2となります。
また、配列の要素には、配列を含め、あらゆるデータ型を格納できます。 要素ごとに型が違っていても構いません。
a = {true, 1, "abc", {5, 10.0}};
こう書けば、aには、論理型と整数型と文字列型と配列を要素に含む、 要素数4の配列が格納されます。 a[3]は配列を返しますから、a[3][1]と書けば、10.0を返します。 このように、crowbarには多次元配列はありませんが、 「配列の配列」により実質的に多次元配列を実現できます。
既に上で例として出していますが、[]を適用することで、 配列の要素にアクセスできます。 当然、添え字はゼロから始まります。
b = a[i];
と書けば、bに、配列aのi番目の要素が代入されますし、
a[i] = 5;
と書けば、配列aのi番目の要素に5が代入されます。
このとき、aが配列でなければ実行時エラーです。 また、[]の中は必ず整数型でなければなりません。
crowbarの配列は自動拡張しません。 言語によっては、現状の配列のサイズに関係なく 「a[100] = 10;」 のように書けば自動的に配列が拡張されるものがあります(Perlなど)。 また、あらゆる配列を連想配列(添字として文字列(等)を使える配列) で表現している言語(JavaScriptなど)でも、 任意の時点でa[100]への代入が可能です。 しかしこのような言語仕様は、 私には、単にバグの発見を遅らせるだけのように見えます. crowbarでは、現在のaの要素数が5であれば、 a[10]への代入も、a[10]の参照も、実行時エラーです。
crowbarの配列は参照型です。 参照型とは何かというと、何かを「指し示す」ための値を保持する型です。 要するにポインタです。 もちろんCとは異なり、不正なメモリアクセスはできないようになっていますが。
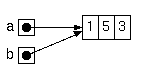
変数aに配列を代入したとき、実際にaに格納されるのはその配列を 「指し示す」値ですから、それを別の変数に代入すると、 ふたつの変数が同じ配列を指すことになります。 よって、以下のプログラムは、「a[1]..5」と表示します。
a = {1, 2, 3};
b = a;
b[1] = 5;
print("a[1].." + a[1] + "\n");
これは、bにaを代入することにより、変数aと変数bが、 下図のように、どちらも同じ配列を指し示すようになったためです。
crowbarの配列は、単なる要素への代入では自動拡張しませんが、 明示的に要素を追加することで伸長させることはできます。 以下のように書けば、配列の末尾に要素を追加することができます。
a = {1, 2, 3};
a.add(4);
こうすることで、aの指す先の配列は、「{1, 2, 3, 4}」となります。
状況によっては、ある一定のサイズの配列を一気に確保したい、 というケースがあるでしょう。たとえば、 「生徒40人の身長を配列で管理したい。出席番号をインデックスとする。 ただし、データがやってくる順番はランダムである」 というケースでは、最初にあらかじめ40個分の配列を確保しておきたいはずです。
構文をいじるほどのことではないと思うので、 ネイティブ関数を使うことにしました。 ネイティブ関数new_array()により一定サイズの配列が取得できます。
a = new_array(40);
初期状態ではすべての要素にnullが格納されています。
複数の引数を渡すことで、多次元配列(配列の配列)も作成可能です。
a = new_array(5, 10);
上の例では、a[4][9]までの要素を持つ配列が作成されます。
crowbar ver.0.2における、上で書いた以外の修正点は以下の通りです。
配列のリテラルを{}で囲んで表現するようにしようとしたら、 for文の構文とで衝突(conflict)を起こしました。
for i = 0; i < 10; {
と書いたとき、この中括弧が
が判定できないためです。 yaccに怒られるまで気付かない私が間抜けだ、というレベルの問題ですが。
んで、結局ifやらwhileやらforやらでは、Cと同様、 ()が必要ということにしてしまいました。 もともと迷っていたことなので、背中を押された、というところです。
従来のcrowbarは、参照カウンタ式のGCを使っていました。
しかし、参照カウンタ式のGCは循環参照を開放することができません。 以前はGC対象が文字列だけだったため、循環参照が起きることはなく、 問題にならなかったのですが、 配列は配列を指すことができるので、循環参照が発生し得るわけです。 循環参照があると、それ全体がどこからも参照されていなくても、 参照カウンタはゼロにならないために解放されず、 メモリリークとなってしまいます 。
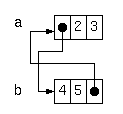
たとえば
a = {1, 2, 3};
b = {4, 5, a};
a[0] = b;
と書けば、下図のような循環参照となります。
そこで、参照カウンタ型のGCは廃止し、mark-sweep型のGCを導入しました。
上に書いたように、配列への要素の追加は、 メソッド呼び出しのような構文で行うことができます。
a.add(3);
このため、メソッド呼び出し(っぽい記法)をサポートできるよう構文を修正しました。
従来、代入式の左辺に来るものは変数名以外あり得なかったので、 構文規則もそれ相応にしていましたが、配列を導入したことで、
a[i][func(b[i])] = 5;
というようなコードにも対応しなければならなくなります。
左辺値の扱いの変更のついでに、 インクリメント/デクリメント演算子も導入しました。 「i++」と書くことで、iが1増加します。 もちろん--も使えます。
インクリメント/デクリメント演算子は、後置のみです。 前置の++, --はありません。
私としては、インクリメントやデクリメントはそれだけを1行で書け、 と常々主張しているわけですし、式の中に混在させるのでなければ、 前置も後置も意味は同じです。だったら片方だけで良いだろう、 ということで、私が普段使っている後置だけにしました。
それだけを1行で書け、というのなら、 インクリメントやデクリメントを、式ではなく文にすれば良かろう、 という意見もあるかもしれませんが、そうすると、for文の第3式に i++が書けなくなるので、今のところは式にしています。
GCの話に入る前に、crowbar ver.0.2における参照データ型の扱いについて説明します。
crowbarにおいて、参照型のデータ型は以下のふたつです。
もっとも、文字列は、 その内容を変更することができない(immutableな)オブジェクトなので、 ユーザは、それが参照であることを意識する必要はありませんけれど。
crowbarでは、あらゆる値は、CRB_Valueに格納されています。 crowbar ver.0.1では、CRB_Valueが直接CRB_String へのポインタを保持していましたが、 文字列と配列というふたつの参照型をまとめて扱うため、 CRB_Objectという型を新設し、CRB_Valueはこれへのポインタを持つようにして、 CRB_StringとCRB_ArrayはCRB_Object側で保持するようにしました。
typedef struct {
CRB_ValueType type;
union {
CRB_Boolean boolean_value;
int int_value;
double double_value;
void *native_pointer_value;
CRB_Object *object;
} u;
} CRB_Value;
CRB_Objectの定義は以下の通り。
typedef enum {
ARRAY_OBJECT = 1,
STRING_OBJECT,
OBJECT_TYPE_COUNT_PLUS_1
} ObjectType;
struct CRB_Object_tag {
ObjectType type;
unsigned int marked:1;
union {
CRB_Array array;
CRB_String string;
} u;
struct CRB_Object_tag *prev;
struct CRB_Object_tag *next;
};
CRB_Value側で型の区別は付くのに、CRB_Object側でも列挙型ObjectType を保持しているのは、GCの際、 CRB_Object単体で型の区別を付ける必要があるためです。
markedは、後述するmark-sweep GCにおいて、 オブジェクトにマークを付けるためのフラグです。 1ビットで済むので、ビットフィールドを使用しています。
いやその私もこういうことをする際は、unsigned intで「flags」 といった変数を保持し、その中に、 自力でビット演算して1ビット単位でフラグを持たせる、 というようなことをすることが多かったのですが (世間のフリーソフトの類いでもそうしているものが多いようですが)、 その方法とビットフィールドを比べて、 ビットフィールドが劣っている所が色々考えても見当たらないので、 今回はビットフィールドを使うことにしました。
まあ、富豪的プログラミングの感覚からすれば、 1ビットのフラグでも、CRB_Boolean型ひとつ割り当てるべきなのかもしれませんけど。
CRB_Objectは、共用体で、CRB_ArrayかCRB_Stringのいずれかを保持していますが、 それぞれの型の定義は以下の通りです。
struct CRB_Array_tag {
int size; /* 表向きの要素数 */
int alloc_size; /* 確保している要素数 */
CRB_Value *array; /* 配列要素(可変長配列) */
};
struct CRB_String_tag {
CRB_Boolean is_literal;
char *string;
};
配列が、sizeの他にalloc_sizeを保持しているのは、 配列に要素を追加する際に、ある程度まとめて領域を拡張することで 速度の向上を図っているからです。
CRB_Stringの定義は、以前CRB_dev.hにありましたが、カプセル化を考慮して crowbar.hに引越しました。 現在、CRB_dev.hで公開しているのはCRB_Object、CRB_Array, CRB_Stringの 不完全型宣言だけです。が、実際にはこれだけでは役に立たないので、 native.cはcrowbar.hを#includeしてしまっています(だめじゃん)。
このあたり、実行時エラーの出し方なども含めて、 そのうちに整理しようと思っています。
ガベージコレクタ(GC)というのは、 不要なオブジェクトのメモリを自動で解放してくれる機構のことです。
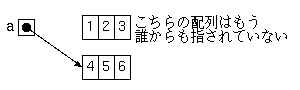
では、「不要なオブジェクト」はどのように定義されるのかというと、 「どう参照を辿っても決して行き着けないオブジェクト」です。 たとえば
a = {1, 2, 3};
a = {2, 3, 4};
というコードがあれば、2行目の代入が実行された時点で、 「{1, 2, 3}」の方の配列はどこからも参照できなくなるので、 GCの対象になります。
オブジェクトが「どこからも参照されていない」ことを判定するために、 ver.0.1では参照カウンタを使用していましたが、 既に説明したようにこの方法では循環参照があると困るので、 今回はmark-sweep GCを導入しています。
mark-sweep GCというのは、GCのアルゴリズムのひとつです。 このアルゴリズムは、以下のような戦略をとります。
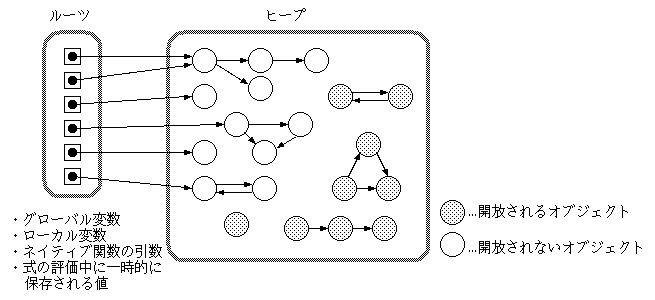
crowbarにおいて、「参照の起点」となり得るのは、以下の箇所です。 なお、これらの「参照の起点」のことを、ルーツと呼ぶことがあるようです。
これらのルーツから間接的にでも辿れるオブジェクトは生き残りますが、 それ以外のオブジェクトは解放されてしまうわけです(下図)。
さて、ルーツの中で扱いが厄介なのは、 「式の評価中に一時的に保持される参照」です。
たとえば「"abc" + "def" + "ghi"」という式があったとき、 crowbarのインタプリタは、まず「"abc" + "def"」を評価し、 「"abcdef"」という文字列を生成します ※1。 この文字列は、 グローバル変数からもローカル変数からもネイティブ関数の仮引数からも 参照されていませんが、必要な文字列です。GCで捨てられてしまっては困ります。
「なにもわざわざそんなクリティカルなタイミングでGCしなきゃいいのでは?」と 思う人がいるかもしれません。 しかしたとえば以下のような記述もcrowbarでは許されるわけで、
print("abc" + "def" + long_long_fuction());
もし「式の評価中はGCしない」という規則を採用するとすると、 このケースではlong_long_function()が動いている間中GCできないことになり、 現実的ではありません。 よって、GCは式の評価途中でも動く可能性があるわけです。
crowbarでGCが動くタイミングについては後述しますが、 大筋では「新たにメモリを割り当てるときにはGCが動く可能性がある」ということに なっています。
さて、「式の評価途中に一時的に保持される参照」 の扱いが厄介だという話の続きです。
「式の評価途中に一時的に保持される参照」が具体的にどこにあるかと言えば、 crowbar ver.0.1では、eval.c内の各関数のローカル変数です。
たとえば文字列連結は、crb_eval_binary_expression()を超簡略化して書けば、 以下のような手順で行なわれています。
CRB_Value left_val;
CRB_Value right_val;
CRB_Value result;
/* 左辺を評価 */
left_val = eval_expression(inter, env, left);
/* 右辺を評価 */
right_val = eval_expression(inter, env, right);
(中略)
result.type = CRB_STRING_VALUE;
/* chain_string中でGCが動くかも */
result.u.string_value = chain_string(inter,
left_val.u.string_value,
right_str);
(中略)
return result;
「"abc" + "def" + "ghi"」のような式の場合、 解析木は以下のようになり、これが深さ優先で評価されていきますから、 "abcdef"という文字列への参照が、いったんローカル変数 left_valに格納されることになります。
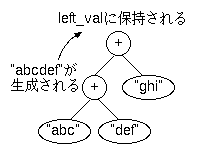
その後のchain_string()の呼び出しでは、 メモリの確保が起きるのでGCが動くかもしれません。このとき、 left_valが指す先のオブジェクトもmarkしなければならないのですが、 (chain_string()のさらに奥で呼び出されるであろう)GCの中からは、 単なるローカル変数でしかないleft_valは見えません。
ひとつの方法としては、Cのローカル変数の領域をスキャンする、 という方法があります(Rubyで使われている方法)。 Cのローカル変数は通常スタックに確保されますから、 式の評価の開始時に適当なローカル変数のアドレスを憶えておいて、 GCが呼び出された時、また適当なローカル変数のアドレスを取得すれば、 その間に確保されたローカル変数は、 このふたつのアドレスのどこかにあるはずです (最適化でレジスタに割り当てられたりしていない限り)。 そこで、領域全体をスキャンして、 オブジェクトを参照しているらしき領域があれば、 そこを起点にマークしていきます。
ただ、この方法は、
という欠点があり、私は使う気になれません。メモリリークの問題の方は、 (Rubyが実用になっている以上)実用上問題のない話なんだと思うんですが ※2、 いくらCだからって、 むやみやたらとポインタをアドレス扱いするのは私的にはどうも…
ではcrowbarではどうしたのかというと、 「Cのスタックを使うから悪いので、独自スタックで管理すればいいじゃん」 と考えて、「式の評価途中に一時的に保持される参照」は、 独自のスタック(CRB_Valueの配列)に積むことにしました。 GCは、このスタックから参照できるオブジェクトに対してマークを行ないます。
スタックは、Stack構造体で表現され、
typedef struct {
int stack_alloc_size;
int stack_pointer;
CRB_Value *stack;
} Stack;
この構造体をCRB_Interpreterに保持しています(CRB_Interpreter以外 これを保持しているものはいないので、 Stack構造体には、単に名前空間を区切る意味しかありません)。
このスタック(以後、「crowbarスタック」と呼ぶことにしましょう)は、 オブジェクトへの参照を含む含まないに関わらず、 式の評価中に一時的に算出される値全てを保持します。
今までは、eval.cの各評価関数は、評価した後その値を戻り値で返していましたが、 ver.0.2以降はスタック経由で返します。 そのため、今までCRB_Valueを返していたeval_xxx_expression() 系の関数は軒並みvoid型になりました。
たとえば、以下のような式は、
"1+2*3.." + (1 + 2 * 3);
こんな解析木に展開されるわけですが、
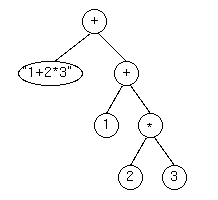
これが評価される際、スタックは下図のように変化します。
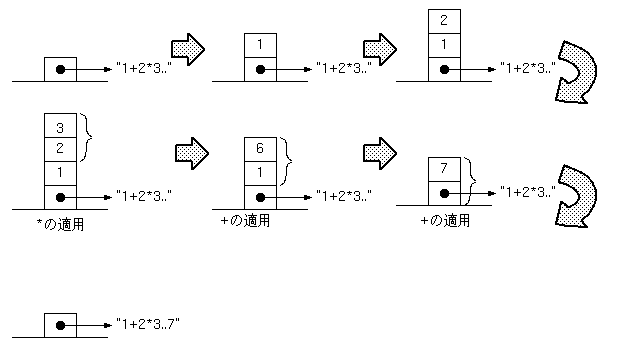
つまり、*とか+とかの演算子は、そのオペランドをスタックから取り、 演算結果の値をスタック上に残すわけです。
実のところこれは、JVMのようなスタックマシンが、 バイトコードを実行していく際のスタックの動きと同じです。 つまり、ここまでやってしまえば、バイトコードインタプリタまでもう一歩です。 まあ、crowbarのような型なし言語をバイトコードインタプリタにしたところで、 さして高速化は期待できませんが、パーサとVMを分離しやすくなるとか、 gotoの実装が容易になるといったメリットはあるでしょう。
ここでは、 上で挙げた4種類のルーツのうち「式の評価中に一時的に保持される参照。」 以外のものについて説明します。
グローバル変数は、CRB_Interpreterから連結リストで辿ることができますから、 これを起点にマークするのは容易です。
ローカル変数は、LocalEnvironment構造体で保持し、引数で持ち歩いていました。
GCでは、 現在有効なすべてのローカル変数からマークを行なわなければなりませんから、 すべてのローカル変数を追えるよう、LocalEnvironmentにメンバnextを追加し、 連結リストとしました。
typedef struct LocalEnvironment_tag {
Variable *variable;
struct LocalEnvironment_tag *next;
} LocalEnvironment;
そのトップをCRB_Interpreterで保持しています。 この場合の「トップ」とは、最後に呼ばれた最新の関数の LocalEnvironmentを指します。
struct CRB_Interpreter_tag {
(中略)
LocalEnvironment *top_environment;
};
ちなみにですが、現在のcrowbarでは、ローカル変数を検索する際、 引数で渡された最新のLocalEnvironmentのみから検索しますが、 nextを辿って、呼び出し経路すべてのLocalEnvironmentから検索するようにすると、 呼び出し元の変数を参照できるようになります。 このようなスコープをダイナミックスコープと呼びます。 が、正直わかりにくいので、最近の言語では流行らないようです (Emacs LispやPerlのlocal変数はダイナミックスコープ)。
crowbarで記述された関数の仮引数は、 呼び出しの際にローカル変数の中に押し込まれるので特に意識する必要はないですが、 ネイティブ関数の仮引数はネイティブ関数に配列として渡されます。 そして、ネイティブ関数の実行中にGCが動く可能性もありますから、 これもGCが辿れるようにしておかなければなりません。
そこで、ネイティブ関数の引数はcrowbarスタックに積んでおき、 ネイティブ関数には、その先頭アドレスを渡すことにしました。
crowbarのスタックはアドレスの大きい方に向かって伸びます。 よって、引数を前から順に評価していけば、 ネイティブ関数に渡す引数の配列が出来上がるという寸法です。
ここまで、mark-sweep GCの基本的な原理や、 crowbarにおけるオブジェクト参照の「ルーツ」について説明してきました。
ここでは、crowbarが実際にどのようにGCを行なうのか、 その実装について説明します。
なお、GC関連のソースは、主にheap.cに収められています。
crowbarにおいて、文字列や配列といったヒープ(任意の順序で確保 /解放可能な領域)に保持されるオブジェクトは、 CRB_Object構造体で保持されています。 CRB_Objectは、ひとつずつMEM_malloc()により確保されます。
CRB_Object構造体の定義は既出ですが、prev, next というポインタをメンバに持っています。 この名前から想像が付くように、CRB_Objectは双方向連結リストで管理されます。
その連結リストの根元は、CRB_Interpreterで保持しています。 ヒープ関連の情報をまとめるために、Heapという構造体が定義されています。
typedef struct {
int current_heap_size;
int current_threshold;
CRB_Object *header;
} Heap;
headerが、CRB_Objectのリストの先頭を押さえています。
current_heap_sizeとcurrent_thresholdは、GC起動のタイミングを制御します。 続きは次の項で。
mark-sweep GCは、プログラム実行中のあるタイミングで動いて、 不要なオブジェクトを解放しますが、どのタイミングで動くべきでしょうか。
ひとつの案としては、メモリが足りなくなったとき――すなわち、 malloc()がNULLを返した時、というのが考えられます。 しかし、現状のMEM_malloc()はmalloc()がNULLを返したらその場でexit()する、 という事実はさておくとしても、 malloc()がNULLを返すほど本当にメモリが不足した後、 おっとり刀でGCしたって手遅れという気がします。 後述するように、現状のmark-sweep GCはスタックを大量に必要とするので そんな状況で動けるかどうか心配ですし、 たいていのOSでは、free()したからといってOSにメモリを返すことはしません。 次のmalloc()で使えるようになるだけです。 GCがメモリをfree()しても他のアプリケーション(プロセス) はそれを使えないので、 ぎりぎり一杯までGCせずに粘るのは、他のプロセスに迷惑というものでしょう。
そこで、crowbarでは、「ある一定量のメモリを消費したら、GCを起動する」 ということにしました。 その一定量は、Heap構造体のcurrent_thresholdに保持されており、 初期値はマクロHEAP_THRESHOLD_SIZEに#defineされています。 ちなみにthresholdとは閾値という意味です。現状では256KBにしてあります。
crowbarは、オブジェクトが確保される度に、そのサイズを CRB_Interpreter中のHeap構造体のcurrent_heap_sizeに加算していきます。 このサイズは、MEM_malloc()に渡すサイズそのもので、 malloc()やMEMモジュールの管理領域は含みません(所詮目安ですので)。
そして、オブジェクト確保前には、check_gc()を呼び出します。
static void
check_gc(CRB_Interpreter *inter)
{
/* ヒープ消費量が閾値を超えていたら… */
if (inter->heap.current_heap_size > inter->heap.current_threshold) {
/* GCを起動 */
crb_garbage_collect(inter);
/* 次の閾値を設定 */
inter->heap.current_threshold
= inter->heap.current_heap_size + HEAP_THRESHOLD_SIZE;
}
}
この関数で、現状で消費しているヒープサイズが閾値を超えていたら、 GCを起動しています。 GCを行なうことで、current_heap_sizeは縮小するのですが、 次の閾値は、その縮小したcurrent_heap_sizeに、 HEAP_THRESHOLD_SIZEを加算することで算出しています。
さて、ここで呼び出しているcrb_garbage_collect()ですが、
void
crb_garbage_collect(CRB_Interpreter *inter)
{
gc_mark_objects(inter);
gc_sweep_objects(inter);
}
はい。見ての通り、markしてsweepしています。
crb_gargage_collect()から呼び出されている gc_mark_objects()が何をしているかといえば、以下の通り、 全オブジェクトのmarkをクリアした上で、ここまでに説明した各ルーツから、 gc_mark()を呼び出しています。
static void
gc_mark_objects(CRB_Interpreter *inter)
{
CRB_Object *obj;
Variable *v;
LocalEnvironment *lv;
int i;
/* markを全てクリアする。*/
for (obj = inter->heap.header; obj; obj = obj->next) {
gc_reset_mark(obj);
}
/* グローバル変数 */
for (v = inter->variable; v; v = v->next) {
if (dkc_is_object_value(v->value.type)) {
gc_mark(v->value.u.object);
}
}
/* ローカル変数 */
for (lv = inter->top_environment; lv; lv = lv->next) {
for (v = lv->variable; v; v = v->next) {
if (dkc_is_object_value(v->value.type)) {
gc_mark(v->value.u.object);
}
}
}
/* crowbarスタック */
for (i = 0; i < inter->stack.stack_pointer; i++) {
if (dkc_is_object_value(inter->stack.stack[i].type)) {
gc_mark(inter->stack.stack[i].u.object);
}
}
}
gc_mark()では、以下のように、 既にそのオブジェクトがマークされていたらreturnし (循環参照における無限ループを避けるため)、 そうでなければ、自分自身をマークして、 配列の場合は各要素の参照先について再帰的にgc_mark()を呼び出しています。
static void
gc_mark(CRB_Object *obj)
{
if (obj->marked)
return;
obj->marked = CRB_TRUE;
if (obj->type == ARRAY_OBJECT) {
int i;
for (i = 0; i < obj->u.array.size; i++) {
if (dkc_is_object_value(obj->u.array.array[i].type)) {
gc_mark(obj->u.array.array[i].u.object);
}
}
}
}
sweepフェーズは、連結リストで管理されているオブジェクトのうち マークされていないものを解放し、リストをメンテしているだけです ※3。
static void
gc_sweep_objects(CRB_Interpreter *inter)
{
CRB_Object *obj;
CRB_Object *tmp;
for (obj = inter->heap.header; obj; ) {
if (!obj->marked) {
if (obj->prev) {
obj->prev->next = obj->next;
} else {
inter->heap.header = obj->next;
}
if (obj->next) {
obj->next->prev = obj->prev;
}
tmp = obj->next;
gc_dispose_object(inter, obj);
obj = tmp;
} else {
obj = obj->next;
}
}
}
この中で呼び出しているgc_dispose_objectでは、 配列と文字列を見分けて、CRB_Objectの先についている領域を解放しています。
static void
gc_dispose_object(CRB_Interpreter *inter, CRB_Object *obj)
{
switch (obj->type) {
case ARRAY_OBJECT:
inter->heap.current_heap_size
-= sizeof(CRB_Value) * obj->u.array.alloc_size;
MEM_free(obj->u.array.array);
break;
case STRING_OBJECT:
if (!obj->u.string.is_literal) {
inter->heap.current_heap_size -= strlen(obj->u.string.string) + 1;
MEM_free(obj->u.string.string);
}
break;
case OBJECT_TYPE_COUNT_PLUS_1:
default:
DBG_assert(0, ("bad type..%d\n", obj->type));
}
inter->heap.current_heap_size -= sizeof(CRB_Object);
MEM_free(obj);
}
crowbarのGCは、最も素朴な形態のmark-sweep GCです。 とても素朴な実装なので、以下のような問題があります。
まず1の問題です。 mark-sweepアルゴリズムの素朴な実装では、mark-sweepを行なっている間、 プログラムの実行は完全に停止します(crowbarもそうなっています)。 これを避ける(軽減する)には、大きく以下のふたつの方法があります。
GCをプログラム本体の実行と並行して行なえば、GCにトータルで食われる CPU時間は変わらなくても、「プログラムが停止する」という事態は 避けることができます。 しかし、実際にGCを並行して行なおうとすると、 なにしろマークを行なっている間にも本体側のプログラムで オブジェクトの参照関係が変更されるわけですから、 マーク漏れが起きる可能性があります。 これを避ける方法はあるわけですが( 参考ページ)、実装はそこそこ大変そうです。
世代別GCというのは、「ある程度の期間生き抜いたオブジェクトは、 その後ずっと生き残ることが多い」という経験則に基づき、 オブジェクトを世代ごとに管理する手法です。 一定期間生き残ったオブジェクトは、「旧世代」として別扱いとし、 旧世代については、あまり頻繁にはGCを行なわないようにするわけです。
たとえばワープロで巨大な文書を編集している時、 実際にいじりまわしているのは全体のごく一部ですが、 素朴な実装のGCでは、文書全体のマークを行います。 これはいかにも無駄であり、世代別GCはこの無駄を回避できるので、 GCに要する時間そのものを短縮でき、スループットの向上が見込めます。
問題は、旧世代のオブジェクトから新世代のオブジェクトへの参照があると、 旧世代をマークしない限り新世代のオブジェクトがマークされないため、 マーク漏れが起きる、ということです。当然これは許されないので、 何らかの対処をする必要があります。
さて、mark-sweep GCのふたつめの問題点は、 再帰呼び出しがスタックをバカ食いする点です。 実際、メモリがないからGCするのに、 GCがスタックをバカ食いするというのは本末転倒な気がします。 どの程度スタックを消費するかはデータ構造に依存するわけですが、 「巨大なファイルをひたすら連結リストに取り込み、 なんらかの処理を行なう」というプログラムは、結構ありそうな気がします (特にスクリプト言語で作るようなプログラムでは)。 小さなオブジェクトが大量に連なる連結リストを再帰的にマークするには、 そのオブジェクトの数だけスタックを食うことになりますから、 馬鹿になりません。
この問題を回避するために、 リンク反転法と呼ばれる方法が考案されています。 オブジェクトをマークする際、再帰を使うと便利なのは、 あるオブジェクトのマークが終わったら、 元のオブジェクトに容易に戻れることと、 オブジェクト中のどの参照まで処理したか、 ということをローカル変数でスタック中に記録しておけることですが、 リンク反転法は、以下の方法でそれをオブジェクト内に記録します。
今回の修正では、
というように、式の後ろに何かを付けるという修正が多いので、 構文規則にpostfix_expressionという非終端子を導入しました(この名前は K&R付録のCの構文規則からパクリ)。
unary_expression
: postfix_expression
| SUB unary_expression
;
postfix_expression
: primary_expression
/* 配列要素の参照 */
| postfix_expression LB expression RB
/* メソッド呼び出し */
| postfix_expression DOT IDENTIFIER LP argument_list RP
| postfix_expression DOT IDENTIFIER LP RP
/* インクリメント・デクリメント */
| postfix_expression INCREMENT
| postfix_expression DECREMENT
;
これらによって構築される構造体は以下の通り(crowbar.h)。 どれも式なので、Expression構造体の共用体部分に格納されます。
/* 配列要素の参照 */
typedef struct {
Expression *array;
Expression *index;
} IndexExpression;
/* メソッド呼び出し */
typedef struct {
Expression *operand;
} IncrementOrDecrement;
/* インクリメント/デクリメント */
typedef struct {
Expression *expression;
char *identifier;
ArgumentList *argument;
} MethodCallExpression;
crowbarの配列には、以下の「メソッドのようなもの」が装備されています。
# 配列への要素の追加 a.add(3); # 配列のサイズの取得 size = a.size();
また、今回、ついでなので文字列にもメソッドを付けました。
# 文字列の長さの取得 len = "abc".length();
メソッド「もどき」と言っているのは、現状のcrowbarでは、 型(またはオブジェクト)にメソッドを割り当てる汎用的な手段がなく、 以下のようにソース中の埋め込みでベタに処理しているからです(eval.c)。
static void
eval_method_call_expression(CRB_Interpreter *inter, LocalEnvironment *env,
Expression *expr)
{
CRB_Value *left;
CRB_Value result;
CRB_Boolean error_flag = CRB_FALSE;
eval_expression(inter, env, expr->u.method_call_expression.expression);
left = peek_stack(inter, 0);
if (left->type == CRB_ARRAY_VALUE) {
if (!strcmp(expr->u.method_call_expression.identifier, "add")) {
CRB_Value *add;
check_method_argument_count(expr->line_number,
expr->u.method_call_expression
.argument, 1);
eval_expression(inter, env,
expr->u.method_call_expression.argument
->expression);
add = peek_stack(inter, 0);
crb_array_add(inter, left->u.object, *add);
pop_value(inter);
result.type = CRB_NULL_VALUE;
} else if (!strcmp(expr->u.method_call_expression.identifier,
"size")) {
check_method_argument_count(expr->line_number,
expr->u.method_call_expression
.argument, 0);
result.type = CRB_INT_VALUE;
result.u.int_value = left->u.object->u.array.size;
} else {
error_flag = CRB_TRUE;
}
} else if (left->type == CRB_STRING_VALUE) {
if (!strcmp(expr->u.method_call_expression.identifier, "length")) {
check_method_argument_count(expr->line_number,
expr->u.method_call_expression
.argument, 0);
result.type = CRB_INT_VALUE;
result.u.int_value = strlen(left->u.object->u.string.string);
} else {
error_flag = CRB_TRUE;
}
} else {
error_flag = CRB_TRUE;
}
if (error_flag) {
crb_runtime_error(expr->line_number, NO_SUCH_METHOD_ERR,
STRING_MESSAGE_ARGUMENT, "method_name",
expr->u.method_call_expression.identifier,
MESSAGE_ARGUMENT_END);
}
pop_value(inter);
push_value(inter, &result);
}
ところで脱線しますが、配列の要素数の取得メソッドは、 当初「get_size()」としていました。getter系のメソッドは 統一的にget_xxx()という名前にするのがよかろう、と思ったからです。
しかし、このメソッドは、きわめて頻繁に、 しかもfor文とかの込み入ったところで使われるであろうことを考えると、 あまり長いメソッド名はどうかなあ、と思ったので結局size()にしました。
統一性も大事だけれど利便性も大事、言語とかライブラリとかを作る時には、 このへんの兼ね合いが難しいんだよなあ、と常々思っています。
もっとも、配列のサイズ取得がなぜかメソッドでもないただのlengthで、 文字列はlength()で、VectorやArrayListはsize()である某言語なんかは、 兼ね合い以前の単なる不統一だと思いますけれど。
ver.1.0では、代入の左辺に来るものは変数以外あり得なかったので、 代入の構文規則は以下のようになっていました。
expression
: IDENTIFIER ASSIGN expression
;
しかし、配列の導入により、 代入の左辺にややこしい式が書けるようになったので、 構文規則を以下のように変更しました。
expression
: postfix_expression ASSIGN expression
;
左辺がpostfix_expressionになっているのは、 現状で代入の対象になるのは、primary_expression(変数名)と postfix_expression(配列の要素)しかないからです。
そして、eval.cの中では、
static void
eval_assign_expression(CRB_Interpreter *inter, LocalEnvironment *env,
Expression *left, Expression *expression)
{
CRB_Value *src;
CRB_Value *dest;
/* まず右辺を評価 */
eval_expression(inter, env, expression);
src = peek_stack(inter, 0);
/* 左辺のアドレスを取得 */
dest = get_lvalue(inter, env, left);
*dest = *src;
}
まず右辺を評価した上で、get_lvalue()という関数を呼び出して、 左辺の式のアドレスを取得しています。 なお、ここで呼び出しているpeek_stack()とは、 スタックの内容を除去せずに値を読み取る関数です。 こうすることで右辺の値がスタックに残り、 それが代入式全体の値となって、具合がよいわけです。
では、そのget_lvalue()がどのようになっているかといえば、
CRB_Value *
get_lvalue(CRB_Interpreter *inter, LocalEnvironment *env,
Expression *expr)
{
CRB_Value *dest;
if (expr->type == IDENTIFIER_EXPRESSION) {
dest = get_identifier_lvalue(inter, env, expr->u.identifier);
} else if (expr->type == INDEX_EXPRESSION) {
dest = get_array_element_lvalue(inter, env, expr);
} else {
crb_runtime_error(expr->line_number, NOT_LVALUE_ERR,
MESSAGE_ARGUMENT_END);
}
return dest;
}
このように、識別子と配列で処理を分けた上で、たとえば配列なら、 以下の手順で要素のアドレスを返しています。
CRB_Value *
get_array_element_lvalue(CRB_Interpreter *inter, LocalEnvironment *env,
Expression *expr)
{
CRB_Value array;
CRB_Value index;
/* []の左の式を評価 */
eval_expression(inter, env, expr->u.index_expression.array);
/* []の中の式を評価 */
eval_expression(inter, env, expr->u.index_expression.index);
/* それぞれの値を取得 */
index = pop_value(inter);
array = pop_value(inter);
/* 型チェック */
if (array.type != CRB_ARRAY_VALUE) {
crb_runtime_error(expr->line_number, INDEX_OPERAND_NOT_ARRAY_ERR,
MESSAGE_ARGUMENT_END);
}
if (index.type != CRB_INT_VALUE) {
crb_runtime_error(expr->line_number, INDEX_OPERAND_NOT_INT_ERR,
MESSAGE_ARGUMENT_END);
}
/* 添字の範囲チェック */
if (index.u.int_value < 0
|| index.u.int_value >= array.u.object->u.array.size) {
crb_runtime_error(expr->line_number, ARRAY_INDEX_OUT_OF_BOUNDS_ERR,
INT_MESSAGE_ARGUMENT,
"size", array.u.object->u.array.size,
INT_MESSAGE_ARGUMENT, "index", index.u.int_value,
MESSAGE_ARGUMENT_END);
}
/* アドレスを返す */
return &array.u.object->u.array.array[index.u.int_value];
}
ちなみに、左辺値でなく、配列の要素に格納された値が参照された際には、 eval_index_expression()が呼び出されるわけですが、 この関数は内部的にget_array_element_lvalue()を使用しています。
static void
eval_index_expression(CRB_Interpreter *inter,
LocalEnvironment *env, Expression *expr)
{
CRB_Value *left;
left = get_array_element_lvalue(inter, env, expr);
push_value(inter, left);
}
インクリメント/デクリメント演算子でも、同様に get_lvalue()を使用して対象のアドレスを取得しています。
既に説明したように、配列は{1, 2, 3}のようにリテラルで生成するほか、 ネイティブ関数new_array()で生成することもできます。 そのためのネイティブ関数の定義は以下のとおりです。
/* 再帰で呼び出される下位ルーチン */
CRB_Value
new_array_sub(CRB_Interpreter *inter,
int arg_count, CRB_Value *args, int arg_idx)
{
CRB_Value ret;
int size;
int i;
if (args[arg_idx].type != CRB_INT_VALUE) {
crb_runtime_error(0, NEW_ARRAY_ARGUMENT_TYPE_ERR,
MESSAGE_ARGUMENT_END);
}
size = args[arg_idx].u.int_value;
ret.type = CRB_ARRAY_VALUE;
ret.u.object = crb_create_array(inter, size);
# GCされないようにおまじない
CRB_push_value(inter, &ret);
if (arg_idx == arg_count-1) {
for (i = 0; i < size; i++) {
ret.u.object->u.array.array[i].type = CRB_NULL_VALUE;
}
} else {
for (i = 0; i < size; i++) {
ret.u.object->u.array.array[i]
= new_array_sub(inter, arg_count, args, arg_idx+1);
}
}
CRB_pop_value(inter);
return ret;
}
/* ネイティブ関数本体 */
CRB_Value
crb_nv_new_array_proc(CRB_Interpreter *interpreter,
int arg_count, CRB_Value *args)
{
CRB_Value value;
if (arg_count < 1) {
crb_runtime_error(0, ARGUMENT_TOO_FEW_ERR,
MESSAGE_ARGUMENT_END);
}
value = new_array_sub(interpreter, arg_count, args, 0);
return value;
}
見てのとおり、処理としては再帰的に配列の配列を作っていってるだけなのですが、 new_array_sub()において、作成した配列への参照を、 CRB_push_value()関数を使用してcrowbarスタックに押し込んでいます。 これをやらないと、多次元配列の確保の際は、途中でGCが動き、 取得途中の配列が解放されてしまう可能性があるためです。
これを忘れてバグを入れてしまうと、再現性が非常に薄いバグとなります (GCがちょうどそのタイミングで動かない限りバグが発現しない)。
Rubyだと、GCがCスタックをスキャンするので、 ネイティブ関数のローカル変数もGCがスキャンしてくれ、 こういうことを意識する必要がありません。 Ruby作者のまつもとゆきひろさんは、 その利点は結構大きいと認識されているようですが、 確かにそんな気はします。
ネイティブ関数のデバッグ時は、heap.cのcheck_gc()をいじって、 メモリの確保時には常にGCが動くようにする、 といった工夫をする必要があるでしょう。 ていうかcrowbar自体、そのようにしてデバッグしました。
配列が導入されたことで、言語のコアとしては、 最低限の機能は実装されたんじゃないかと思います。
ではここからライブラリの充実を図って…と言いたいところですが、 ハンパな言語仕様の上にライブラリを載せても ライブラリまでハンパになるだけですので、 次回は、OO的な機能を実装しようと思います。 その上でなら、そこそこちゃんとした形でライブラリが書けるんじゃないか、 と思っています。
てなわけで、また気長にお待ちくださいませ(_o_)