今回書こうとしていることは、私的には、「当然」のことだと思ってました。 ある程度以上の規模のシステムを書こうと思ったら、 あるいは自分のライブラリがある程度以上の規模のシステムで 使われることを想定したら、 こういうことは当然考えざるを得ない話なんじゃないかと。
でも...
最近仕事ではC使ってないんですが、故あってC/C++共用の某ライブラリを 調査しなきゃならないこととかもありまして。
はあ。GetFieldIDですか。GetArrayLengthですか。
# 2001/12/31 訂正: # JNIのライブラリは、関数へのポインタを構造体メンバに入れることで # 名前空間の問題を回避していますね。よって、この批判は全く的外れです。 # 撤回します。大変失礼しました。 # 実はこれはだいぶ前に知っていたのですが、ここの修正を忘れていました。 # 申し訳ありません。
そういえば、Windowsの時も、GetMessageとかSendMessageとか PostMessageとかだったなあ。
...あれえ?
UNIXで、普段は使いもしないシステムコールごときがopenとかcloseとかの 「一等地」の名前を使ってるのを知った時にも「あれえ?」と思いましたけど。 Cを始めたばかりの頃でしたが。
うーん...
当たり前ですが、Cでは、関数の名前空間って、2段階しかないんですよね。 すなわち、ひとつのソースファイル内で閉じるか、完全にまる見えかです。 そして、この手のライブラリをファイルスコープにできるわけがないので、 必然的にまる見えになっちゃいます。 何万行、何十万行、何百万行のプログラムであっても、 リンクしちゃえばみんなにまる見え、そしてその名前はもう誰も使えません。
なのに、よくこんな大胆な名前を使うなあ、と、 小心者の私なんかは思ってしまいます。
てなわけで、大規模プロジェクトでは、多少の流儀の違いはあれど 常識の範疇のことだろうと思うんですが、今回は、 モジュール分割とか、命名規則とか、ヘッダファイルの使い方について 書いてみようと思います。
人間の脳ミソは「複雑さ」の度合いが大きくなり過ぎると追い付かなくなるので、 大規模なプログラムを書く際には、プログラム全体をいくつかの 「モジュール」に分け、それぞれをブラックボックス化し、 最小のインタフェースで疎結合させるのが良い、とはよく言われることです。
でも、なんか、「モジュール」という言葉ほど、 ろくに定義されずに使われている言葉もないような気もします。
ちょっと古い本を見ると「モジュール == サブルーチン」の意味で 使われていたりします(対象言語はFORTRANだったり)。 サブルーチンと言えば、Cで言う所の関数ですね。 「大規模なプログラムは、きちんとモジュールに分けて設計しなければならない」 みたいなことが書いてあって、こりゃつまり「関数分割」しなさいってことですね。 平和な時代があったものです。
ちょっと前、某所で「うちのコーディング規約では 『1ファイルに 1モジュールを記述する』と決められているのですが、 この規則って妥当なものなのでしょうか」なんて質問が出たことがあったのですが、 この場合の「モジュール」は、1関数のことだったようです。
Cに特有の話になりますが、ひとつの.cファイル(あるいはそれに対応する.o ファイル)を「モジュール」と呼ぶ人もいるようです(Cの世界では、 これが一番一般的かも)。 先にも書きましたが、これが、C言語がサポートする情報隠蔽の最大の単位であり、 特に関数名については唯一の単位となります。 変数名については、ブロック毎にローカル変数を定義することも出来ますが、 複数の関数から参照しようと思うと、やっぱりファイル単位で閉じるか、 全体にまる見えかのどちらかになってしまいます。
念のために書いときますと、関数名や、関数ローカルでない変数名のスコープを、 ソースファイル内で閉じるには、宣言の時にstaticを付けます。 巨大なプログラムを開発する場合に staticを付けないと、「誰か他の人がこの名前を使ってたらどうしよう?」 と常に気を使わなければなりませんが、 staticを付ければ、名前空間がそのソースファイル内で閉じるので ソースファイル単位で好きな名前を付けることが出来ます。 こういう「名前の隠蔽」は、大規模プロジェクトでは、非常に重要なことです。
# JavaやAdaやModula2やC++では、名前空間を選択的にエクスポートしたり、 # 選択的に取り込んだりして、もっと柔軟な対応が出来るのですが。
するってえと、先程の『1ファイルに1モジュールを記述する』という規約は、 たった1階層しかないCの情報隠蔽の単位をわざわざ無駄に捨てる ということですね。 よって、こんなアホなことをしてはいけません。 いえ、「本当にそんなことしてるプロジェクトがあるのか?」と思う人も いるかも知れませんけど、実は結構見掛けるものです(私も経験あります)。
どうも、根拠は、「1ファイル1関数にして、 関数名とファイル名に同じ名前を付けるんだ。 そうじゃないと関数定義を探すのが大変じゃないか」 ということのようなんですが、 もし本当にそう思っているのなら、取り敢えず エディタがviならctags、 Emacsならetagsの使い方を覚えるべきでしょうね。 Windowsとかで統合開発環境使ってるならなおのことですし。
# Javaだと、「1ファイル1クラス」という規則が割と主流のようです。 # 確かに、Javaでは名前空間はパッケージで制御できるのでそれでも良さそうな # ものではありますが、例えば中身からっぽの例外クラスごときに1ファイルを # 当てるのはどうにも鬱陶しいので、私はこの規則はあんまり気に入ってません。
さて、Cでは、ソースファイル単位で名前空間の隠蔽が出来ますが、 プログラムの規模がさらに大きく、 ソースファイルの数自体が膨大になってくると、 今度は、いくつかのソースファイルをまとめて、 もう1段階大きな固まりを作る必要が出てきます。 以下、この文章中では、この固まりのことを「モジュール」と呼びます。
# こういうのは「ライブラリ」と呼ばれることもありますが、「ライブラリ」と # 言うとどうも「下請け」的なイメージがあって、私にはちょっとしっくり来ません。
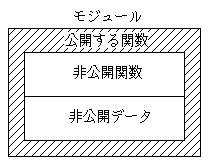
モジュールは、以下の要素から構成されます。
モジュールは、公開関数のみをインタフェースとして外界に提供します。 データ(今のところ大雑把に言えばグローバル変数か)は、 余程のことがない限り非公開にして、公開関数を用いてアクセスするようにします。
あ、そうそう、念のため。
「あ、知ってる。カプセル化だ。そういうのをオブジェクト指向って言うんでしょ。」 なんて思ってしまった人がひょっとしているかも知れませんが、 違います。
まあオブジェクト指向にもいろいろあるようなんですが、 今普通に使われているJavaやC++での考え方では、 「クラス」という定義を元にして、「オブジェクト」をばこばこ複数生成します。 ここでの「モジュール」は、1個だけ静的に存在するわけですから、 オブジェクトではありません。
もっとも、Javaでも、java.lang.Mathのようにstatic メンバで固めたクラスがあったりして、 ああいうのはどう見てもオブジェクト指向的ではないわけなんですが、 現実のプログラミングではそういうのも必要なんですよね。
それから、上記の「モジュール」だけを組み合わせてプログラム全体が 構成できればいいんですが、実際のCのプログラムでは(規模にもよりますが)、 隠蔽しない「グローバルなデータモデル」を用意したりもします。 で、モジュール毎に「参照権」と「更新権」を決めて、 「紳士協定」によりデータモデルの整合性を保つわけです。
オブジェクト指向的な考え方からすれば、 各クラスにその振舞いが定義されていて、それぞれのオブジェクトが 能動的に動いてどうこうなっていく、と考えるのでしょうけど、 私には「受動的に操作されるデータモデル」もやっぱり存在するように思えます。 というか、例えばMVCなんて、データモデルとその振舞いを分離する考え方なわけで、 MVCでは、Modelが、最低限、モデルとしてのデータの整合性を 自分で保証するんですが、 それが「紳士協定」でどうにかなるのなら、 「グローバルなデータモデル」も悪くないと思います。 ただし、更新権を持つモジュールは唯一にすべきでしょうけど。
さて、「ソースファイル」よりも大きな単位として「モジュール」という 概念を導入しようとしても、Cでは、名前空間が2段階しかないので、 どうしても命名規則に頼る必要が出てきます。
ま、Javaみたいに、言語が「パッケージ」を提供していたとしても、 現実に、java.awt.Listとjava.util.Listが衝突しちゃって使いにくいよう、 という事実もあったりして、 例えばSwingでは結局命名規則でAWTとの衝突を回避していたりするので、 命名規則ってのもそう馬鹿にしたものでもないのかも知れません。
さて、命名規則にも色々流儀はあるでしょうけど、 以下が、私流の命名規則です。 個人的に書くプログラムでは、今の所こうしてます。
例えば、XXXという名前のモジュールでは、公開する関数名は XXX_hoge_piyo()、非公開の関数名はxxx_hoge_piyo(), 公開する型名はXXX_HogePiyoとなります。
# この規則が適用「できない」唯一の関数があります。もちろん main ですね。
公開する識別子にプレフィクスを付けるのは、 他のモジュールと競合を起こさないためと、 どのモジュールが提供しているものか一目で分かるようにするためです。
非公開でも、Cの名前空間の都合上「隠せない」識別子については、 小文字のプレフィクスを付けます。
そういえば、細かいことを言うと、ANSI-Cでは、 外部リンケージを持つ識別子について大文字小文字の識別を することを保証していないのですが、 ま、大抵の処理系ではOKのようですし、この制限は時代おくれのものだと 見倣されているようなので、私は気にせず名前をぶつけています。
非公開の型名・マクロについては、プレフィクスを付けません。 これはヘッダファイルの切り分けにより隠蔽できるからです。
static関数にもプレフィクスを付けませんが、 関数外のstatic変数にはプレフィクスst_を付けます。 これは、関数内のローカル変数と区別を付けるためです。 ソースファイルのスコープを超える変数名には 小文字のモジュール名がプレフィクスとして付きますから、 これで3段階のスコープについて識別できることになります。
# 関係ないけど、Javaではローカル変数とメンバ変数の区別が付かなくてコードが # 読みにくいことが頻繁にあるので、命名規則で逃げる必要があると思います。 # Javaではあんまり一般的じゃないですが、MFCではメンバ変数に m_をプレフィク # スで付けるようになっていて、あれはあれで合理的だと思います。
そういえば、単語の切れ目を大文字小文字で表現するかアンダーバーで表現するかは、 ともすれば宗教戦争にもなるようなネタらしく、 手元の「Think GNU」(株式会社ビレッジセンター刊)の 「GNUコーディング規則」では、「6.名前の付け方」(P.67)に、
名前の付け方については、単語の区分に下線を使いなさい。
(中略)
例えば、ignore_space_change_flagのような名前を使いなさい。 iCantReadThisのような名前を使ってはならない。
なんて書いてありますが、大文字小文字で区切る流儀が、"I can't read this"と 言われる程読みにくいとは思わないんですけどねえ。 Javaではこっちが主流ですし。
てなわけで、私は特定の宗教にはまる素質もないようなんで、 この記法の違いを、型名と関数名・変数名の区別を付けるのに使っています。 ま、型名は出てくる所が決まってるので、 あまり識別を付ける必要もないのかも知れませんけど、 やっぱり気分的に違うような気がします。
ついでに、識別子の「長さ」についてですが、 規格では、外部リンケージを持つ識別子については6文字までしか 保証してないんですけれども、 実際問題、例えばXlibの関数に"XCreate"で始まる関数がいくつあるか、 なんて考えると、この制限を守ることに意味があるとは思えません。
ただ、外部リンケージを持たない名前についてのANSIの制限である、 32文字という制限は守るのもいいかもしれません。 32文字あれば、だいたい足りると思いますから。
入門書なんかだと、たいていひどく短い名前を付けたりするものですが、 入門書は所詮入門書、巨大なプログラムを、 ドキュメントやコメントに頼らずにすいすいと読めるようにするには、 長い名前が必須です。
最近は、Windowsのライブラリや、Javaなどで、長い名前が使われているので、 新人プログラマでは比較的長い名前に対する抵抗が薄れているように 思いますけど、どうも昔ながらのプログラマの間では、 可能な限り名前を短かくしようと、妙な省略に走る人が多いようです。
Xlibでウィンドウを作るのに通常使う関数は、 XCreateSimpleWindow()です。 わりあいよく使う関数で、XCreatePixmapFromBitmapData()なんてのもあります。 Xt(Motifなど)で、ボタンやらテキストフィールドなどを作るのに通常使うのは、 XtVaCreateManagedWidget()です。
正直言って、これ見て、「げっ、何だこのクソ長い名前は」なんて思う人は、 考えを改めるべきだと思います。 そんなことでは、ArrayIndexOutOfBoundsExceptionなんて名前を 平気な顔して使ってる言語に移行できませんぜ。
CreSimpleWinぐらいの省略なら、まあ何やってるか見当が付きますが、 CRSWINなんてレベルまで省略されるともう何が何だかわかりません (こういう名前を付けたがる人が、本当にいるんだってば)。 それどころか、関数名が全部「プレフィクス+番号」なんて プロジェクトもいまだにあったりして(本当だってば)、 そういう所にはできるだけ関わらずに生きていきたいと思う今日この頃です。
モジュールを構成する際、重要な役割を果たすのがヘッダファイルです。
ヘッダファイルの作り方としては、まず、一般的な規則として、
1の、「二重#include防止用のガード」ってのは、要するにこんな奴です。
#ifndef HOGEHOGE_H_INCLUDED
#define HOGEHOGE_H_INCLUDED
<ヘッダファイル本体>
#endif /* HOGEHOGE_H_INCLUDED */
こうしておけば、ヘッダファイルの依存関係の都合により 複数回 includeされても、二重定義のエラーを起こさないようにできます。
2の規則ですが、これはつまり、あるヘッダファイル(a.hとします)で、 別のヘッダファイル(b.h)を必要としている(b.hで定義している型やら マクロやらをa.hで使用している)のなら、 a.hの冒頭でb.hをincludeしてしまえ、ということです。
世間にはincludeのネストを嫌う人がちょくちょくいるようなんですが、 a.hでb.hを必要としているのなら、includeのネストをしなければ、 a.hを使う全ての個所で
#include "b.h" #include "a.h"
なんて書かなければなりません。こんなアホな話はないです。 めんどくさいこともさることながら、将来の変更で a.hがb.hに依存しなくなった後も、多分この2行は永久に残るんでしょうし。
依存関係がわかりにくくなるという説もあるようですが、 Makefileを書くにはどうせ何らかのツールを使って依存関係を自動生成するわけで、 .cを書く人全てに.hの依存関係を公開する意味があるとも思えません。
# 世間には、依存関係の自動生成ツールどころか、make自体を知らず、ccをいっぱい # 並べたシェルスクリプトを「めいくふぁいる」と呼び習わしているプロジェクトも # 実在するんだけどさ... 本当だってば。
そして、ヘッダファイルの依存関係が、 理解できないほどこんぐらがってしまったとしたら、 それはやっぱり設計に問題があると思います。
# 某プロジェクトにおいて、まあそのプロジェクトでは標準的な.cファイルについて、 # ヘッダファイルの依存関係を調べてみたら、300を超えるヘッダファイルに依存して # いたなんて話もあります。本当なんだからしょうがない。
てなわけで、ヘッダファイルの構成なんですけれども、 まず第一に、ヘッダファイルは、モジュール単位で パブリックとプライベートに分けるものです。
パブリックヘッダファイルには、そのモジュールが、 外部に対して公開するものを記述します。
具体的には、
程度を記述します。 かなり大きなモジュールでも、公開関数はそんなに多くはないでしょうから、 通常、パブリックヘッダファイルは、ごく短かいものになります。
プライベートヘッダファイルには、そのモジュール内部の.cファイルにて 共有する情報を記述します。
プライベートヘッダファイルは、内部でたいていパブリックヘッダファイルで 提供している型やらマクロやら関数やらを使用しますから、 プライベートヘッダファイルは多くの場合パブリックヘッダファイルを includeすることになります。
でも、パブリックヘッダファイルは、直接にも間接にも 絶対にプライベートヘッダファイルをincludeしてはいけません。 例えば会社で、社外に配布するパンフレットに書いてあるようなことを 社内向けの文書に書くのは全然問題ないですが、 社内向けの(社外秘の)文書に書いてあるようなことを 社外向けのパンフレットに書いてはいけないのと同じことです。
こうすれば、プライベートヘッダファイルに記述されている内容が そのモジュールの利用者まで漏曳することはないですし、 ヘッダファイルの依存関係の階層も、自ずと浅くなる筈です。
似た例として、モジュールが他のモジュール(標準ライブラリとか)を ラッピングするケースはよくあります。 例えば、独自の抽象的な描画モジュールを作って、 X Window Systemの描画ライブラリであるXlibを隠蔽しよう、 という例などです。
その「独自の抽象描画モジュール」の名前を仮に"DRW"としますが、 下図のように、"DRW"でXLIBを完全に隠蔽したいと思うなら、

"DRW"のパブリックヘッダファイル(仮に"DRW.h"とします)は、 直接にも間接にも、Xlib.hとかXutil.hとかの、Xlib関係のヘッダファイルを includeしてはいけません。
また、例えば"DRW"のパブリック関数の一部(たとえば初期化関数)の 引数の型として、どうしてもXlib.hで提供されている型を使用したいという場合は、 次の図のように、部分的にせよXlibの概念をアプリケーションに 見せていることになるわけですが、

こういう場合には、XLIBを必要とする関数のプロトタイプ宣言のみを 別のヘッダファイル(例えば"DRW_X.h")に分けてしまって、 "DRW.h"だけを見ていれば良い大部分のアプリケーションプログラムには、 Xlib.hの概念を流出させないようにすべきでしょう。
...ところでここでXlibを例に出したのは、 私が配属されて最初にいじり回したライブラリがXlibだからなんですが、 Cを覚えて間もないその頃、Xlibの命名規則が、
というようになっているのを見て、しばし理由を考え、
「あー、これは、関数名はグローバルなリンケージを持つから命名規則を 適用する必要があるけれど、型名やマクロはヘッダファイルを見せなければ 隠蔽できるわけだから、こういう規則になっているんだろうなあ」
と素人ながらに推測したものです。
「と、いうことは、XLIBなんて実際低レベルなライブラリだから、 実際の大規模プログラムでは、抽象化したライブラリで隠蔽して 使うということを前提にしているんだろうなあ。 でなきゃ、DisplayとかWindowなんて大胆な名前、 普通使わないよなあ。」
なんて思っていたのですが...
その後、Motif(というかXt)を使うことになったのですが、 これ、下位ライブラリとしてXlibを使ってはいるものの、 例えば画面にボタンを並べて、 そのコールバックルーチンを書いたりしている範囲では、 Xlibなんて意識する必要は全くないのです(DrawingAreaでも使うならともかく)。
なのに、Xtの最も基本となるヘッダファイルIntrinsic.hで Xlib.hをincludeしてくれているせいで、結局全員にもれなくXlib.hが プレゼントされ、DisplayだのWindowだのScreenだの、 誰でも使いそうな名前が軒並み使えなくなる、 という事態に陥っていたのでした。
その後、Sun PHIGSを使う機会もあったのですが、これも同様で、 Sun PHIGSの関数の中でXlibの概念が必要なものはごく一部(ほんの1関数かそこら) しかなかったにも関わらず、Sun PHIGSを使うためのヘッダファイルを includeすると全員にもれなくXlib.hがプレゼントされたのでした。
Windowsは... もう何を考えているかわからんというか。
あと、Xtがらみで特にはまったのが、Booleanです。
命名規則の類がまともに適用されていなかったプロジェクトで、 他の人が書いた関数を呼ぶためにヘッダファイルをincludeしたら、 そこにBooleanが定義されていて、XtのIntrinsic.hで提供されている Booleanと衝突してしまったわけです。
幸い、その時は、問題のヘッダファイルを修正する権限はあったのですが、 そのヘッダファイルはあちこちでincludeされているので、 ヘタにいじるわけにもいかない状況でした。
昔々、typedefが使える保証がなかった頃には、#defineで代用していたので、 #ifdef TRUE とかやって逃げることも可能だったわけですが、 今時そういうわけにもいかず、泣く泣く
#ifndef _XtIntrinsic_h
typedef enum {
TRUE = 1,
FALSE = 0
} Boolean;
#endif /* _XtIntrinsic_h */
と回避した記憶があります。
こういうことをすると、XtのBooleanはcharで、 こっちのヘッダで定義してあるBooleanはenumなので、問題が起きる可能性があります。 integral promotion様々、なんて喜んでる場合じゃなくって、 配列渡してたりしたらヤバヤバなんですが(ま、 今はコンパイラがチェックしてくれますね)。
ところで、私の命名規則では、モジュールプライベートな型名では Booleanを使ってもいいですが、モジュールパブリックな型名では プレフィクスを付けることになっているので、XXX_Booleanみたいな 型名になるはずです。
でも... Booleanなんていうどっちがどっちだかよくわからん型を 引数の型にするより、明示的にenumを作った方が利用者に親切なので、 パブリックヘッダファイルではBooleanを書きたいと思ったことがありません。
プライベートヘッダファイルでは、私の場合毎度のようにBooleanを作っていますが、 これはまず問題を起こさないと思います。
先に書いた定義では、モジュールは、内部に「非公開データ」を抱えています。
ということは、モジュールが何らかの「状態」を持つということですから、 使い始める前に、
XXX_initialize(void);
のような関数を呼んでやって、初期化する必要があります。
まあ、グローバル変数には初期化子が書けますし、 グローバル変数のポインタの先にもっと複雑な構造を構築するのだとしても、 グローバル変数が初期状態かどうかをフラグに lazy initializationを行なえばどうにかなりはしますが、 そのような方法では、モジュールを一度使い始めたら2度とリセットできないわけで、 やはり外部から初期化関数を呼んでやった方が良いでしょう (場合によっては終了関数も)。
ところで、モジュールが状態を持ち、 そしてその状態をグローバル変数で押さえているということは、 そのモジュールが同時にはひとつしか存在し得ない、 ということを意味します。
こういうモジュールは、同時(必ずしもマルチスレッドを意味しない)に 複数の個所から使えませんし、外部仕様にも重大な制限を加えたりします。 例えば、なんかの台帳を管理するモジュールを書きました、 でも、その台帳をグローバル変数で押さえちゃったので、 同時に複数の台帳を開いて見比べながら作業したりできるように プログラムを拡張することは、実質不可能になっちゃいました、 といったように。
てなわけで、どうせなら、 モジュールは「初期化関数」を呼んでやるんじゃなくて 以下のような「構築関数」を呼んでやるようにして、
XXX_Instance XXX_create(void);
以後、そこで取得したポインタを 第1引数として持って回るようにした方が良さそうです。
XXX_hoge(XXX_Instance xxx, 第2引数, 第3引数);
敢えて大雑把な言い方をすれば、 要するにこれがオブジェクト指向です。
継承を考えない限りにおいては、 C++でもJavaでも、要するにやってることはインスタンスのポインタを 第1引数に持って回ってるだけのことであって、 あとは、表記法が若干異なるのと、メソッドの名前空間が異なる程度の話です。
# Cで、継承とメソッドオーバーライドを実現する方法... ってのは、次回以降の # ネタにしようかな。
当然、このXXX_Instanceという型は、パブリックヘッダファイルには 不完全型宣言のみを記述し、内部情報は公開しないようにします。
パブリックヘッダファイル: typedef struct XXX_Instance_tag *XXX_Instance;
プライベートヘッダファイル:
struct XXX_Instance_tag {
/* 実装詳細 */
};
こんな感じで書いていけば、Cでも、相当なレベルでの情報隠蔽と、 オブジェクト指向っぽいコーディングが可能になります。
今回ここで書いた流儀は、あくまで我流です。 文中に、MotifとかSunPHIGSなんかを例に出しましたけど、 そういうメジャーなライブラリさえ、私の考える規則からすれば、 「あれえ?」と思わざるを得ない構造になっています。 冒頭に挙げたGetFieldIDなんてのは、今をときめく某クソ言語の ネイティブインタフェースです。
こういう状況では、はっきり言って、私自身、自分流のやり方に さほど自信が持てるわけではありません。 その辺のCの入門書を買ってきても、こんなことは書いてないですし。
でも... Cの名前空間の規則を考えれば、合理的な方法なのでは、と 自分では思うんですが、どんなもんでしょう?
ひとつ上のページに戻る | ひとつ前の話 | ひとつ後の話 | トップページに戻る