コンピュータというものは内部的には数値しか扱えません。「でも、文字も画像も扱えているのでは?」と思うかもしれませんが、文字や画像も内部的には数値で扱っています。画像についてはまた別途話すとして、文字については、コンピュータは内部的には文字コード(character code)で扱っています。つまり、それぞれの文字に番号を振り、内部的にはその番号(文字コード)で処理しているのです。
コンピュータはアメリカで発達してきたという都合もあり、昔のコンピュータは、アルファベットと数字、および一部の記号しか扱えませんでした。その当時に決められた文字コードのひとつがASCIIコード(アスキーコード/American Standard Code for Information Interchange)です※1。下の表が、ASCIIコードの一覧です。
| 10進 | 16進 | 文字 | 10進 | 16進 | 文字 | 10進 | 16進 | 文字 | 10進 | 16進 | 文字 | 10進 | 16進 | 文字 | 10進 | 16進 | 文字 | 10進 | 16進 | 文字 | 10進 | 16進 | 文字 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | NULL | 16 | 10 | DLE | 32 | 20 | SP | 48 | 30 | 0 | 64 | 40 | @ | 80 | 50 | P | 96 | 60 | ` | 112 | 70 | p |
| 1 | 1 | SOH | 17 | 11 | DC1 | 33 | 21 | ! | 49 | 31 | 1 | 65 | 41 | A | 81 | 51 | Q | 97 | 61 | a | 113 | 71 | q |
| 2 | 2 | STX | 18 | 12 | DC2 | 34 | 22 | " | 50 | 32 | 2 | 66 | 42 | B | 82 | 52 | R | 98 | 62 | b | 114 | 72 | r |
| 3 | 3 | ETX | 19 | 13 | DC3 | 35 | 23 | # | 51 | 33 | 3 | 67 | 43 | C | 83 | 53 | S | 99 | 63 | c | 115 | 73 | s |
| 4 | 4 | EOT | 20 | 14 | DC4 | 36 | 24 | $ | 52 | 34 | 4 | 68 | 44 | D | 84 | 54 | T | 100 | 64 | d | 116 | 74 | t |
| 5 | 5 | ENQ | 21 | 15 | NAK | 37 | 25 | % | 53 | 35 | 5 | 69 | 45 | E | 85 | 55 | U | 101 | 65 | e | 117 | 75 | u |
| 6 | 6 | ACK | 22 | 16 | SYN | 38 | 26 | & | 54 | 36 | 6 | 70 | 46 | F | 86 | 56 | V | 102 | 66 | f | 118 | 76 | v |
| 7 | 7 | BEL | 23 | 17 | ETB | 39 | 27 | ' | 55 | 37 | 7 | 71 | 47 | G | 87 | 57 | W | 103 | 67 | g | 119 | 77 | w |
| 8 | 8 | BS | 24 | 18 | CAN | 40 | 28 | ( | 56 | 38 | 8 | 72 | 48 | H | 88 | 58 | X | 104 | 68 | h | 120 | 78 | x |
| 9 | 9 | HT | 25 | 19 | EM | 41 | 29 | ) | 57 | 39 | 9 | 73 | 49 | I | 89 | 59 | Y | 105 | 69 | i | 121 | 79 | y |
| 10 | A | LF | 26 | 1A | SUB | 42 | 2A | * | 58 | 3A | : | 74 | 4A | J | 90 | 5A | Z | 106 | 6A | j | 122 | 7A | z |
| 11 | B | VT | 27 | 1B | ESC | 43 | 2B | + | 59 | 3B | ; | 75 | 4B | K | 91 | 5B | [ | 107 | 6B | k | 123 | 7B | { |
| 12 | C | FF | 28 | 1C | FS | 44 | 2C | , | 60 | 3C | < | 76 | 4C | L | 92 | 5C | ⧵ | 108 | 6C | l | 124 | 7C | | |
| 13 | D | CR | 29 | 1D | GS | 45 | 2D | - | 61 | 3D | = | 77 | 4D | M | 93 | 5D | ] | 109 | 6D | m | 125 | 7D | } |
| 14 | E | SO | 30 | 1E | RS | 46 | 2E | . | 62 | 3E | > | 78 | 4E | N | 94 | 5E | ^ | 110 | 6E | n | 126 | 7E | ~ |
| 15 | F | SI | 31 | 1F | US | 47 | 2F | / | 63 | 3F | ? | 79 | 4F | O | 95 | 5F | _ | 111 | 6F | o | 127 | 7F | DEL |
ASCIIコードは0から127まであり、その番号を「10進」の列に記載しています。「10進」というのは10進数のことで、これはつまり我々が数値を表すのに普通に使っている表記のことです。その右の「16進」の列は、同じ値を16進数で表現したものです。ASCIIコードは16進数で表記することも多いので併記しています(「16進数って何だ?」という人はこちらを参照のこと)。その右の「文字」の列が、そのASCIIコードで表現される文字です。ASCIIコード10進の0~31および127の、背景がピンクになっているところは、「制御文字」と言われるもので、普通の文字ではありません。今ではほとんど使われないものが大多数ですが、9のHTはHorizontal Tabulation――水平タブ、要するにTABキーを押すと挿入されるタブのことですし、10と13のLF, CRは改行コードとして使われています。また、32のSPは、空白を意味しています。
制御文字以外の、背景白の文字を見てみると、0~9の数字、アルファベットの大文字小文字のほか、!とか"とかの記号もだいたい揃っていて、これだけあれば、英文ならまず不自由なく書けそうです。ASCIIコードは1963年に制定されたのでもう半世紀以上昔のコードですが、今でも「ASCII文字だけを基本としている」ケースが散見されるのは、英語圏の人にはこれで必要十分だからでしょう。
――そして、JavaScriptを含め、いまどきのたいていのプログラミング言語※2も、ユーザに表示するメッセージとか、コメントとか以外の、プログラムの動作を決めるような部分はすべてこのASCIIコードの範囲内の文字で書きます。実は変数名とかは漢字やひらがなが使えることもありますが、実際に使っている人はほぼ見かけません。
ASCIIコードでは数字とアルファベットと一部の記号しか表現できませんから、アメリカ人はこれでよくても、日本人には不便です。そこで、日本では、まずカタカナを表示できるようにしました。もちろんひらがなや漢字も表示したかったのでしょうが、昔のショボいコンピュータではあまり多くの文字を扱うことができなかったのです。日本では、ASCIIの文字にカタカナを加えたJIS X 0201という規格が1969年に決められました。そこで加えられたカタカナおよび句読点等が以下です。
| 10進 | 16進 | 文字 | 10進 | 16進 | 文字 | 10進 | 16進 | 文字 | 10進 | 16進 | 文字 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 160 | A0 | 176 | B0 | ー | 192 | C0 | タ | 208 | D0 | ミ | |
| 161 | A1 | 。 | 177 | B1 | ア | 193 | C1 | チ | 209 | D1 | ム |
| 162 | A2 | 「 | 178 | B2 | イ | 194 | C2 | ツ | 210 | D2 | メ |
| 163 | A3 | 」 | 179 | B3 | ウ | 195 | C3 | テ | 211 | D3 | モ |
| 164 | A4 | 、 | 180 | B4 | エ | 196 | C4 | ト | 212 | D4 | ヤ |
| 165 | A5 | ・ | 181 | B5 | オ | 197 | C5 | ナ | 213 | D5 | ユ |
| 166 | A6 | ヲ | 182 | B6 | カ | 198 | C6 | ニ | 214 | D6 | ヨ |
| 167 | A7 | ァ | 183 | B7 | キ | 199 | C7 | ヌ | 215 | D7 | ラ |
| 168 | A8 | ィ | 184 | B8 | ク | 200 | C8 | ネ | 216 | D8 | リ |
| 169 | A9 | ゥ | 185 | B9 | ケ | 201 | C9 | ノ | 217 | D9 | ル |
| 170 | AA | ェ | 186 | BA | コ | 202 | CA | ハ | 218 | DA | レ |
| 171 | AB | ォ | 187 | BB | サ | 203 | CB | ヒ | 219 | DB | ロ |
| 172 | AC | ャ | 188 | BC | シ | 204 | CC | フ | 220 | DC | ワ |
| 173 | AD | ュ | 189 | BD | ス | 205 | CD | ヘ | 221 | DD | ン |
| 174 | AE | ョ | 190 | BE | セ | 206 | CE | ホ | 222 | DE | ゙ |
| 175 | AF | ッ | 191 | BF | ソ | 207 | CF | マ | 223 | DF | ゚ |
年寄りの昔話になりますが、1980年頃に日本で売られていた「8ビットパソコン」(今のパソコンはたいてい64ビットです)では、こんなカタカナしか表示できないのが普通でした。
なお、JIS X 0201では、半角カナだけでなく、英数字等、ASCIIの範囲の文字も規定しています(ラテン文字用図形文字集合)。これはほぼASCIIと同じなのですが、以下の2点が異なります。
どちらも、日本で使用頻度が高い文字に置き換えた、ということでしょう。実際、日本でバックスラッシュやチルダは(プログラミング等、コンピュータに関わること以外では)まず使いません。なので¥のように日本で重要な文字に置き換えた、というのはわかるのですが――結果として、環境により同じ文字が「⧵」と表示されたり「¥」と表示されたりする、ということになってしまっています。
ふたつめのオーバーラインは、チルダの文字「˜」で表記してもよいとされていて、実際に日本語版のPCでも˜が表示されることがほとんどです。問題はバックスラッシュと円マークの方で、これはJavaScriptを含め、C言語起源のプログラミング言語では割とよく使う記号なのに、フォントによって円マークになったりバックスラッシュになったりします。プログラミングの入門書などでも、サンプルプログラムなどを円マークにしているものもバックスラッシュにしているものもあったりします。
日本語版のWindowsならたいていは円マークが表示されると思いますが、バックスラッシュが表示されたとしても意味は同じですので、混乱しないようにしてください。
| 10進 | 16進 | 文字 | 10進 | 16進 | 文字 | 10進 | 16進 | 文字 | 10進 | 16進 | 文字 | 10進 | 16進 | 文字 | 10進 | 16進 | 文字 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 32 | 20 | SP | 48 | 30 | 0 | 64 | 40 | @ | 80 | 50 | P | 96 | 60 | ` | 112 | 70 | p |
| 33 | 21 | ! | 49 | 31 | 1 | 65 | 41 | A | 81 | 51 | Q | 97 | 61 | a | 113 | 71 | q |
| 34 | 22 | " | 50 | 32 | 2 | 66 | 42 | B | 82 | 52 | R | 98 | 62 | b | 114 | 72 | r |
| 35 | 23 | # | 51 | 33 | 3 | 67 | 43 | C | 83 | 53 | S | 99 | 63 | c | 115 | 73 | s |
| 36 | 24 | $ | 52 | 34 | 4 | 68 | 44 | D | 84 | 54 | T | 100 | 64 | d | 116 | 74 | t |
| 37 | 25 | % | 53 | 35 | 5 | 69 | 45 | E | 85 | 55 | U | 101 | 65 | e | 117 | 75 | u |
| 38 | 26 | & | 54 | 36 | 6 | 70 | 46 | F | 86 | 56 | V | 102 | 66 | f | 118 | 76 | v |
| 39 | 27 | ' | 55 | 37 | 7 | 71 | 47 | G | 87 | 57 | W | 103 | 67 | g | 119 | 77 | w |
| 40 | 28 | ( | 56 | 38 | 8 | 72 | 48 | H | 88 | 58 | X | 104 | 68 | h | 120 | 78 | x |
| 41 | 29 | ) | 57 | 39 | 9 | 73 | 49 | I | 89 | 59 | Y | 105 | 69 | i | 121 | 79 | y |
| 42 | 2A | * | 58 | 3A | : | 74 | 4A | J | 90 | 5A | Z | 106 | 6A | j | 122 | 7A | z |
| 43 | 2B | + | 59 | 3B | ; | 75 | 4B | K | 91 | 5B | [ | 107 | 6B | k | 123 | 7B | { |
| 44 | 2C | , | 60 | 3C | < | 76 | 4C | L | 92 | 5C | ¥ | 108 | 6C | l | 124 | 7C | | |
| 45 | 2D | - | 61 | 3D | = | 77 | 4D | M | 93 | 5D | ] | 109 | 6D | m | 125 | 7D | } |
| 46 | 2E | . | 62 | 3E | > | 78 | 4E | N | 94 | 5E | ^ | 110 | 6E | n | 126 | 7E | ‾ |
| 47 | 2F | / | 63 | 3F | ? | 79 | 4F | O | 95 | 5F | _ | 111 | 6F | o | |||
JISというのは日本産業規格(Japanese Industrial Standards)の略で、「じす」と読みます。
「え? JISは日本工業規格だろ?」と思った人は知識が古いです。2019年7月1日から日本産業規格に改称されました。
「JISといえばこんなマーク「〄」が鉛筆とかについてるよね、これがJISマークだろ」と思った人はおっさんまたはおばさんです。現在JISマークのデザインは変わっていますし※3、鉛筆にJISマークがついていたのは1998年までです。いや本当、世の中知らないうちにいろいろ変わっているものです。
JIS(日本産業規格)は、コンピュータ関連の規格にとどまらず、土木・建築とかネジとか、(昔の鉛筆にマークがついていたことからもわかるように)鉛筆とかまで、いろいろなものの規格を定めています。経済産業省のWebページ(2020年1月のニュースリリース)には以下のように紹介されています。
JIS(Japanese Industrial Standards)は、製品、データ、サービスなどの種類や品質、それらを確認する試験方法又は評価方法や、要求される規格値などを定めており、例えば、生産者、サービスの提供者、使用者・消費者などが安心して品質が良い製品を入手したり、サービスの提供を受けることができるために用いられています。
経済産業省では、技術の進歩や、社会的環境の変化等、必要に応じて、JISを制定・改正しています。
カタカナが表示できるだけでも進歩といえば進歩ですが、ヤッパリカタカナダケデハヨミニククテショウガナイわけで、ひらがなや漢字の文字コードも定められました。それがJIS X 0208です。
JIS X 0208には、漢字(第1水準2,965文字および第2水準3,390文字)や各種記号のほか、数字やアルファベットやカタカナも含みます。第1水準、第2水準は使用頻度で分けられていて、性能の低いコンピュータは第1水準だけを、性能が高いコンピュータは第2水準も表示できるようにする、というための区分でした。1990年代にはたいていのコンピュータは第2水準までサポートしていましたが、これだけあれば、たいていの日本語の文章は普通に書くことができます。ただ、たとえば「髙木さん」(高木さんではなく、いわゆる「はしご高」の髙木さん)の「髙」のように、表現できない文字も一部ありました。
JIS X 0208の漢字の一覧をこちらのページに載せておきます(横幅が広すぎるので別ページにしました)。
JIS X 0208では、漢字やひらがなや、各種記号やギリシャ文字やキリル文字を、まず94の「区」に分け、区の中の94の「点」コードで表現しています(「区点コード」と呼びます)。これで94×94の8836文字を表現できますから、第1水準と第2水準の漢字2,965+3,390文字とひらがなカタカナ記号くらいなら入ります。「それにしたってなぜ94なんて半端な数字なの?」という疑問については後述します。
前述のように、JIS X 0208は、ひらがなや漢字だけでなく、数字やアルファベットやカタカナも含みます。数字やアルファベットはASCIIで表現できますし、カタカナはJIS X 0201でも表現できるのに、それとは違う文字として、数字やアルファベットやカタカナを定義したわけです。
なぜそんなことをしたのかといえば、ASCIIやJIS X 0201の範囲の数字やアルファベットやカタカナが、基本的に縦長だったからなのだと思います。
今でも「A」という文字は正方形よりは縦長に見えていると思いますが、今、あなたが見ているこのページの文字は、(おそらく)プロポーショナルフォントという、文字ごとに幅が異なるフォント(字体)で表示されていると思います。つまり、「W」(ダブリュー)と「l」(小文字のL)とでは異なる幅に見えるということです。たくさん出せばよくわかるでしょう。「WWWWWW」「llllll」だと、どちらも同じ5文字なのに「lllll」の方がだいぶ幅が狭く見えているのではないでしょうか。英語圏では、紙の本などでも、このように幅の狭い文字は狭く印刷するのが当たり前です。英語では、単語を空白で区切るので、たとえば「intelligence」のような単語を同じ幅の文字で書くと、LとIが続くあたりがスカスカで単語の切れ目に見えかねない、といった事情があるのだと思います。
しかし、文字ごとに異なる幅で表示する、というのは、今でこそ当たり前ですが、昔のコンピュータでは性能的にかなり厳しいものがありました。そこで、昔のコンピュータは、すべての文字が同じ幅(こういうのを等幅フォントと言います)で、数字やアルファベットはたいてい幅と高さの比が1:2になっていました。JIS X 0201のカタカナも、これに合わせて、幅の狭い縦長の文字になっています。なのでJIS X 0201のカタカナはコンナミエカタになっているわけです。
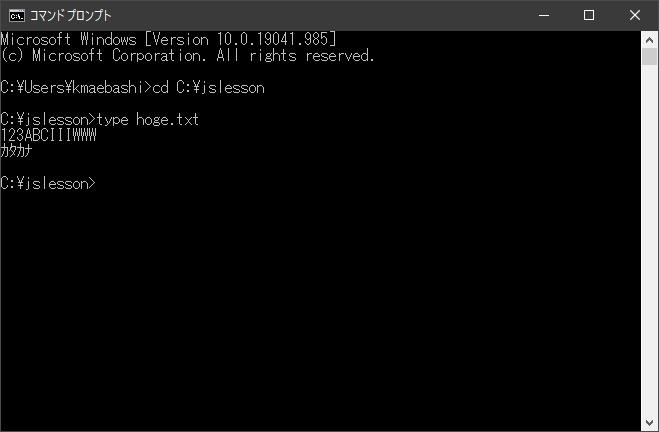
今のWindowsでも、この時代のコンピュータと同じような画面を表示する方法があります。スタートボタンから、「Windowsシステムツール」の下の「コマンドプロンプト」を選択すると表示されるのがコマンドプロンプトです。昔のコンピュータは、画面をいっぱいに使って、これくらいの文字数しか表示できませんでした。
「123ABCIIIWWW」および「カタカナ」という文字を表示しています。IもWも同じ幅で表示されていること、縦長の文字になっていることがわかると思います。
しかし、日本語の漢字やひらがなやカタカナは、本や新聞の活字で見るとわかるでしょうが、だいたい正方形です。これを自然に表現するには、ASCIIやJIS X 0201の2文字分の幅が必要です。JIS X 0208で追加された文字は、当時、たいていASCII文字の2倍の幅で表示されました。これもコマンドプロンプトで表示してみましょう。
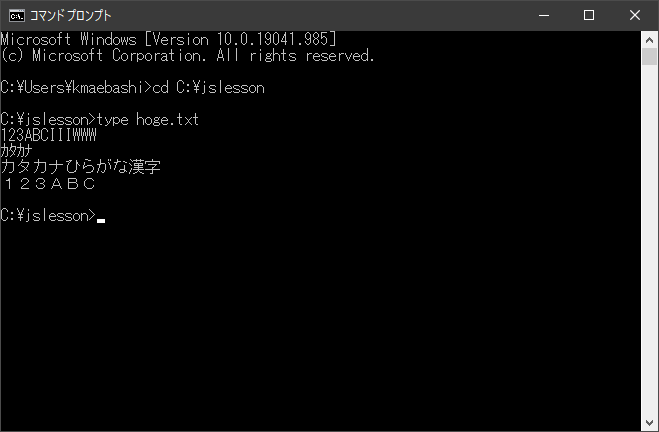
前回の「123ABCIIIWWW」、「カタカナ」に加えて、「カタカナひらがな漢字」と「123ABC」と表示しています。今回追加した文字が、前回の文字のちょうど倍の幅(つまり、2文字分の幅)になっていることがわかると思います。
この「123ABCIIIWWW」、「カタカナ」のような文字が半角文字で、「カタカナひらがな漢字」、「123ABC」のような文字が全角文字です。※4
全角の英数字は、JIS X 0208で追加された文字なので、ASCIIの(半角の)英数字とは別物です。「はじめに」のBMI計算プログラムで、身長、体重をうっかり全角数字で入れてしまうと、JavaScriptのプログラムはこれを数字と認識してくれません。数値を入力しているつもりなのに「身長は数値で入力してください」というエラーが出たのはそのためです。一部、かなり親切なプログラムだと、全角数字を勝手に半角で解釈してくれるプログラムもありますが……(エクセルとか。というか、そういうプログラムは、私はこれしか知らない)
正直なところ、プログラマである私の感覚からすれば、半角のカタカナハサスガニミットモナイから全角カタカナを作るのは理解できますが、全角の英数字なんて作らなければよかったのでは?と思うのですが、これもまあプログラマと一般人の認識のずれなのかもしれません。新聞社とか、全角英数大好きみたいだし。Web上の記事ですら、Webページのアドレス(URL)を全角で記載していて、これではコピペで飛べないから不便なだけではないか、と私なんかは思うのですが。
さらにやっかいなことには、! " # $ % & ' ( ) + - * / = といった記号類にも! ” # $ % & ’ ( )+ - * / =という全角文字がありますし、空白にも半角と全角があります。しかし、前述の通り、プログラムを書くのに使うのは、(ユーザに表示するメッセージとかコメントとかを除けば)基本ASCII文字だけです。全角の文字は使いません。全角の空白に至っては、なにせ見えないので、「画面上でプログラムを見ても何もおかしいところはないのになぜかエラーになる」という事が起きます(エディタによっては区別がつくようにしてくれているものもあります。まあ、よく見ようと印刷しちゃったら、絶対区別できませんね)。
ここまで説明してきたJIS X 0201とかJIS X 0208という規格は、今となっては古い規格で、今や実際にコンピュータが扱う文字コードはほぼUnicode(ユニコード)に統一されています。
JISナントカカントカという規格は、JISというだけあって日本の規格です。それに対しUnicodeは、全世界の文字に通しで文字コード(Unicodeではコードポイントと呼びます)を振る、という発想で決められた文字コードです。Unicodeのおかげで、韓国語とかアラビア語とか中国語の簡体字とかを混在して表示できるわけです。このように。
韓国語:안녕하세요?/하십니까
アラビア語:اَسَّلاَمُ عَلَيْكُم
簡体字中国語:你好
いまどきのコンピュータおよびそのうえで動くソフトウェアはほぼ間違いなくUnicodeに対応しています※5。おそらくあなたが今この文章を読んでいるブラウザでも、韓国語、アラビア語、簡体字中国語が表示されていることでしょう。
上で、JIS X 0208の漢字は第1水準で2,965文字、第2水準で3,390文字と書きましたが、Unicodeは2020年3月のUnicode13.0.0の時点で143,859文字が収録されています。これだけたくさんあるので、JIS X 0208で表現できる漢字どころか、絵文字の類もたくさん入っています。☃とか☕とか🍉とか🍺とか。漢字にしても、「はしご高」の髙木さんもちゃんと表現できますし、有名な牛丼チェーン店も吉野家ではなくて看板通りに𠮷野家と書けます――が、これはいいことばかりではないかもしれません。「吉野家」で検索しても見つからないかもしれないためです。
そして、過去の文書の互換性を考えれば、仕方がないというよりはむしろ当然のこととして、Unicodeでも全角英数字や半角カタカナは生き残りました。
ここから先を読むには、ビットとかバイトとか2進数とかの知識が必要です。知らない人はまず「ビット、バイト、2進数、16進数」を読んでください。
エンコーディング(encoding)とは、文字コードを、実際にバイトとしてどう表現するのかについての決まりです。
まず、ASCIIコードだけしか使えない時代は、1文字を1バイトとしてそのまま表現していました。ASCIIコードは0~127で7ビットに収まっていますから、1バイト(8ビット)で表現できるわけです。「1ビット余ってるのでは? どうせなら8ビット全部使えば、0~255の、倍の文字を表現できたのでは?」と思うかもしれませんが、ASCIIコードの発明当初は、この余った1ビットをパリティビット(parity bit)として使っていたようです。パリティビットというのは、パリティビットを除く7ビットのうち「1」になっているビット数が偶数か奇数かを保持するビットのことで、通信状態が悪かったりメモリの出来が悪かったりとかでたまたまどこかの1ビットがひっくり返ってしまった場合、それを検知できます。もちろん、通信やメモリが十分に信頼性が高かったり、他の手段で正しさを保証できるならパリティビットは不要になります。
パリティビットを使わないなら、1バイトで8ビット分、0~255を表現できますから、ASCIIに加えて128文字分、別の文字を入れられることになります。昔の日本のパソコンなどは、ここに半角カタカナを入れていました。上の、JIS X0201の半角カタカナの表では、半角カタカナには16進数でA0~DFまでのコードが割り当てられていることがわかります。
さて、次は漢字です。JIS X 0208の漢字は、1~94の区点コードで表現されています。これに32を足すと33~126、16進なら0x21~0xFEとなり、ASCIIの制御文字と被らない、7ビットふたつで、1文字の漢字を表現できる、ということになります。こちらの表では、「CODE」のところに、32を足して16進数表記にした値を記載しています。
昔のアメリカ製のプログラムは、何しろASCIIしか前提にしていないので、8ビット目が立っていたら勝手に消してしまうようなものもありました。特に電子メールは、相手に届くまでいくつかのメールサーバを経由して飛んでいくのですが、その中にひとつでも「8ビット目を無視する」ようなものがあったら文字化けしてしまいます※6。その点、JISの区点コードに32を加える方式なら、7ビットに収まっており、かつASCIIの制御文字にもならないので変なことにもならず、メールを送ることができるわけです。
とはいえ、実際のメールでは、ASCIIの文字と漢字を混在させる必要があります。そこで使われた方法がエスケープシーケンス(escape sequence)という特別なバイトの並びで「ここからは漢字(ひらがな等含む)とする」とか「ここからはASCIIとする」という切り替えを行うことでASCII文字と漢字を混在させます。たとえば「ここからは漢字」のエスケープシーケンスは、16進なら1B, 24, 42の3バイトです。この1文字目の1Bが、ASCII制御文字のESC(エスケープ)なので、エスケープシーケンスと呼ばれるわけです。この形の表現形式をISO-2022-JPと呼びます。ISO-2022-JPは、以前は「JISコード」と呼ばれることもありました。
ところで、ISO-2022-JPのように、エスケープシーケンスでASCIIと漢字を切り替えるような方式は、プログラムで文字列を扱うには割と不便です。「先頭から何文字目の文字を取り出したい」という場合、先頭からエスケープシーケンスを解釈しつつ順に読んでいくしかありません。また、当時は「全角文字は半角文字の倍の幅を取る」ものでしたが、バイト数と画面上の幅も一致しません。
そこで作られたエンコーディングが、EUC(拡張UNIXコード:Extended UNIX Code)とシフトJISです。
EUC(日本語用のEUC-JP)では、漢字やひらがなの時には8ビット目を1にします。JIS X 0208の漢字やひらがなは、区点コードに32を加えた状態でも7ビットで収まっていますから、こうすれば2バイトで1文字を表現できます。ASCII文字は7ビットなので、漢字部分は8ビット目が立っていることで簡単に見分けがつきますし、漢字やひらがながASCII文字の倍の幅を取る(全角文字)環境下では、バイト数が画面の幅にも一致します。ただし、それは半角カタカナを使わない範囲でのことで、EUCはいちおう半角カタカナを表現することはできたものの、2バイト必要でした(0x8Eを前に付けるというルール)。なお、ISO-2022-JPはそもそも半角カタカナを含んでいません。かつて「メールでは半角カタカナを使うな」と言われたのはそのためです。
EUCは、拡張UNIXコードと言われるとおり、UNIXというOSで使うために作られたエンコーディングです(今ならLinuxというUNIXのクローンOSの方が有名かもしれません)。UNIXは歴史的に学者とかエンジニアとかが主に使ってきたからか、半角カタカナについては冷淡な文化があったように思います(今でも?)。
しかし、パソコンの世界では、しばらく半角カタカナを使ってきた歴史もあり、捨てるわけにもいきません。また、当時日本で普及していたNECのPC-9800シリーズでは、「テキストVRAM」という、幅80文字高さ25文字に相当するメモリ領域に設定した文字を、ハードウェアで画面描画していた(ウインドウなど存在しなかった時代です)という事情もあって※7、バイト数と画面上の幅を同じにする必要もありました。つまり、画面上でASCII文字と同じ幅である半角カタカナは、1バイトで表現する必要があったということです。そこで考案されたのがシフトJIS(Shift_JIS)です。
シフトJISでは、半角カタカナは8ビット目が立った1バイトで表現します。上のJIS X 0201の表を見ればわかるように、半角カタカナが使用するのは0xA0~0xDFだけなので、残りの領域を使って漢字の1バイト目を、そして次のバイトをほぼフルに使って2バイト目を保持します。具体的には、0x81~0x9Fおよび0xE0~0xEFの47個が1バイト目、2バイト目は0x40~0x7Eの188個を使用します。これで47×188の8836文字、JIS区点コードの94×94=8836文字と同じだけの文字を表現できます。
このように、シフトJISでは、2バイト目にはASCIIの文字と重なるバイトを使います。このため、もともと漢字を扱う機能がないプログラムでシフトJISのファイルを処理すると、2バイト目がASCII文字と解釈されて意図しない動きになることがあります。具体的には、たとえばgccというコンパイラで、文字列(文字列リテラル)中に2バイト目が0x5C(ASCIIなら⧵、日本語環境なら¥)となる文字が含まれると、それがC言語の文字列では特別な意味を持つので意図しない動きをしてしまう、という問題が起きます(0x5C問題)。EUCなら、漢字は1バイト目も2バイト目も8ビット目が立っていて、そんな文字はASCIIにはないので、こういう問題は発生しないのですが(もちろん、これはコンパイラが8ビット目が立っているバイトを「何も言わずにそのまま通す」からであって、「たまたま動いている」とも言えます)。
ISO-2022-JP、EUC、シフトJISは、どれも英数字の文字コードとしてはASCII(JIS X 0201)を、ひらがなや漢字の文字コードとしてはJIS X 0208を使っています。つまりISO-2022-JPとかEUCとかシフトJISとかいうものは、文字コードをバイトの並びとして表現するエンコーディングの方式です。これらを指して文字コードと呼ぶ人がときどきいますが、うるさいことを言えばそれは間違いです。
さて、長々と書いてきましたが、今となってはISO-2022-JPもEUCもシフトJISも、これから積極的に使っていくようなものではありません。今や時代はUnicodeです。そして、Unicodeは文字コードですが、Unicodeという文字コードに対してもいくつかのエンコーディングが存在します。
もともと、Unicodeというのは、「世界中のすべての文字を、2バイト(16ビット)固定長で表現する」ことを目指していました。1991年10月のUniocde1.0.0では実際そうなっています。それを素直に表現するなら、「2バイト(16ビット)で1文字を表現し、それをずらずらと並べる」という方法が考えられるでしょう。この方式のエンコーディングをUTF-16と呼びます。JavaScriptでも、内部的には、文字列はUTF-16で保持しています。
ただし、前述のように、現在のUnicode(Unicode13.0.0)では収録文字数は14万文字を超えており、2バイトでは65,536文字までしか表せませんから、Unicodeの文字は16ビットでは収まっていません。そこで、UTF-16では、収まらなかった文字はサロゲートペア(surrogate pair)という方法で16ビットの値をふたつ使って表現することになりました。たとえば上で例に出した、上が「士」ではなくて「土」になっている看板通りの𠮷野家の「𠮷」の字は、サロゲートペアで表現される文字です。おかげで、JavaScriptでは、「吉野家」の文字列長は3なのですが、「𠮷野家」では4になります。。「𠮷」の字が、サロゲートペアの文字であるため2文字分の長さを持つためで、おかげでJavaScriptの文字列長をそのまま「文字数」として扱うことはできません※8。これは、たとえば以下のようなJavaScriptプログラムで確認できます。
1: alert("「吉野家」の長さ…" + "吉野家".length); // 『「吉野家」の長さ…3』と表示される
2: alert("「𠮷野家」の長さ…" + "𠮷野家".length); // 『「𠮷野家」の長さ…4』と表示される
1文字を表現するのに4バイト(32ビット)使うUTF-32というエンコーディングもあります(LinuxのC言語で「ワイド文字」というのを使えば、UTF-32になります)。これを使えば、「𠮷野家」の長さは3になります。しかし、Unicodeの異体字セレクタという機能を使うと、いずれにせよ、バイト数を2とか4とかで割った値と文字数は一致しません。
ところで、UTF-16では、ASCIIの範囲の英数字も2バイト食います(UTF-32なら4バイト食います)。英語圏の人にしてみればこれは何とも無駄に思えるでしょうし、UTF-16で保存した英字だけのテキストファイルは、従来の、ASCII文字を想定したエディタでは開くことができません。バイト単位で見たとき、1バイトおきに0が登場するのだから当然です。つまり、UTF-16は、ASCIIと互換性がありません。
そこで考えられたのが、UTF-8というエンコーディングです。UTF-8では、7ビットまでの文字はASCIIコードと同じになっています。そのため、ASCIIを扱えるエディタ等なら、ASCII文字の範囲内なら開けます。そして、ASCIIの範囲外の文字は複数のバイトで表現しますが、先頭の1バイトの冒頭のビットの並びで、後に何バイト続くのかを示します。2バイト目以降は、先頭2ビットが常に「10」になっています。1文字を表現するのに最大6バイトまで使うことが想定されています※9。
下の表で、「?」になっているところが、実際にUnicodeのコードポイントを表現するのに使えるビットです。
| バイト数 | 有効なビット数 | 2進数表記 | |||||
|---|---|---|---|---|---|---|---|
| 1 | 7 | 0??????? | |||||
| 2 | 11 | 110????? | 10?????? | ||||
| 3 | 16 | 1110???? | 10?????? | 10?????? | |||
| 4 | 21 | 11110??? | 10?????? | 10?????? | 10?????? | ||
| 5 | 26 | 111110?? | 10?????? | 10?????? | 10?????? | 10?????? | |
| 6 | 31 | 1111110? | 10?????? | 10?????? | 10?????? | 10?????? | 10?????? |
この方式には、以下のような利点があります。
ただし、いいことばかりではなくて、EUCやシフトJISやUTF-16なら日本語のひらがなや普通の漢字は2バイトでしたが、UTF-8では3バイト食います。まあ、仕方がないですけれども。
JavaScriptの文字列といった内部表現はともかく、外部とファイルや通信でやり取りする際の文字コードは、今やUTF-8が普通です。
プログラムで文字を扱うには、1文字当たりのバイト数が一定になっていれば、いろいろ都合がよいものです。5文字目の文字を取り出したいときに、1文字1バイト固定なら5バイト目、1文字2バイト固定なら10バイト目から2バイトを取り出せば済むからです。そして、前述の通り、Unicodeは当初世界中の文字を2バイトで表そうとしていました。しかし、結局、世界中の文字をたった65,536文字で表そうなどというのは無理があり、2バイトを超えてしまった分はサロゲートペアとして表現せざるを得なくなりました。それにより、「1文字あたりのバイト数が一定」という夢は破れた――と思っている人がいるかもしれませんが、実際はそう単純なものでもありません。
Unicodeが2バイトで収まりきらなくなってサロゲートペアを導入したのは1996年のUnicode 2.0.0からです。しかし、Unicodeは、その最初の提案(1989年9月のUnicode Draft 1)の時点で、たとえばドイツ語のウムラウトのような文字(Ä)は通常のローマ字の後ろにアクセント記号を付加するという形式(合成文字) で表現する、ということが表明されていました。よって、ÄのUnicode での表現はU+0042 U+0308と、2バイトの組をふたつ使います(ただし、既存のLatin-1 コードとの互換性のため、U+00C4 でもよいことになっています)。つまり、Unicode は、最初から「1 文字固定長」を目指したコードではなかったのです。
とはいえ、JavaScript(とかJavaとかC#とか)は内部的に文字列をUTF-16で保持していて、2バイト固定長で1文字を表現できると期待していた、としか思えないところもあるのですが……
公開日: 2021/06/20